 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCo-Imitation Learning without Expert Demonstration
Paper and Code
Mar 27, 2021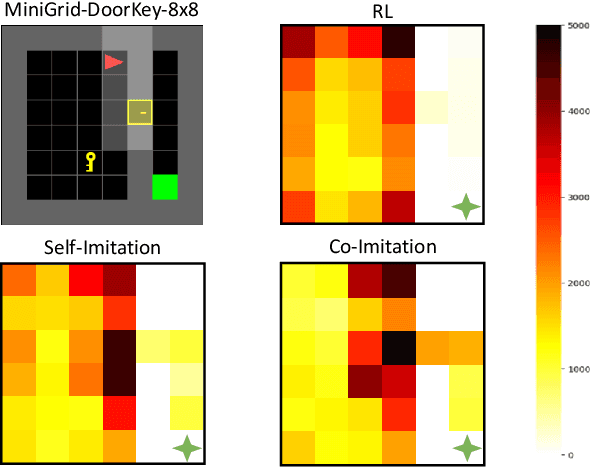
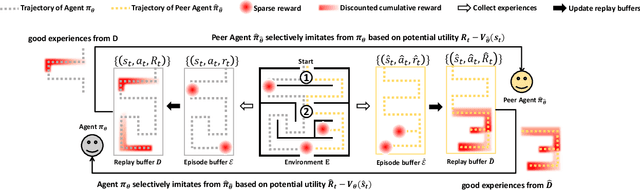
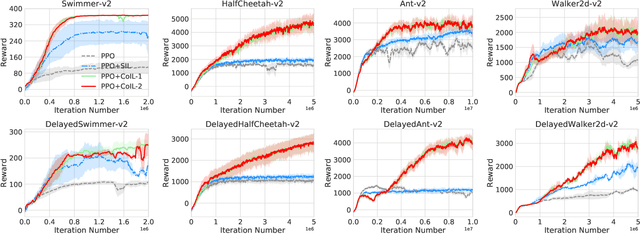

Imitation learning is a primary approach to improve the efficiency of reinforcement learning by exploiting the expert demonstrations. However, in many real scenarios, obtaining expert demonstrations could be extremely expensive or even impossible. To overcome this challenge, in this paper, we propose a novel learning framework called Co-Imitation Learning (CoIL) to exploit the past good experiences of the agents themselves without expert demonstration. Specifically, we train two different agents via letting each of them alternately explore the environment and exploit the peer agent's experience. While the experiences could be valuable or misleading, we propose to estimate the potential utility of each piece of experience with the expected gain of the value function. Thus the agents can selectively imitate from each other by emphasizing the more useful experiences while filtering out noisy ones. Experimental results on various tasks show significant superiority of the proposed Co-Imitation Learning framework, validating that the agents can benefit from each other without external supervision.