 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-efficient LLM Fine-tuning for Code Generation
Apr 17, 2025Large language models (LLMs) have demonstrated significant potential in code generation tasks. However, there remains a performance gap between open-source and closed-source models. To address this gap, existing approaches typically generate large amounts of synthetic data for fine-tuning, which often leads to inefficient training. In this work, we propose a data selection strategy in order to improve the effectiveness and efficiency of training for code-based LLMs. By prioritizing data complexity and ensuring that the sampled subset aligns with the distribution of the original dataset, our sampling strategy effectively selects high-quality data. Additionally, we optimize the tokenization process through a "dynamic pack" technique, which minimizes padding tokens and reduces computational resource consumption. Experimental results show that when training on 40% of the OSS-Instruct dataset, the DeepSeek-Coder-Base-6.7B model achieves an average performance of 66.9%, surpassing the 66.1% performance with the full dataset. Moreover, training time is reduced from 47 minutes to 34 minutes, and the peak GPU memory decreases from 61.47 GB to 42.72 GB during a single epoch. Similar improvements are observed with the CodeLlama-Python-7B model on the Evol-Instruct dataset. By optimizing both data selection and tokenization, our approach not only improves model performance but also improves training efficiency.
CodeACT: Code Adaptive Compute-efficient Tuning Framework for Code LLMs
Aug 05, 2024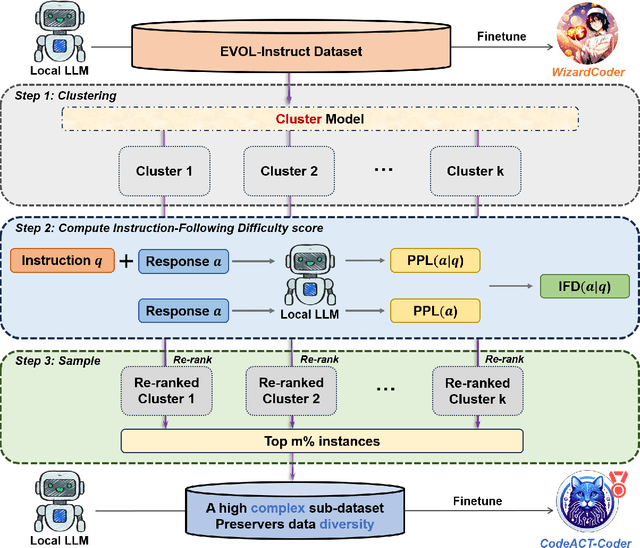
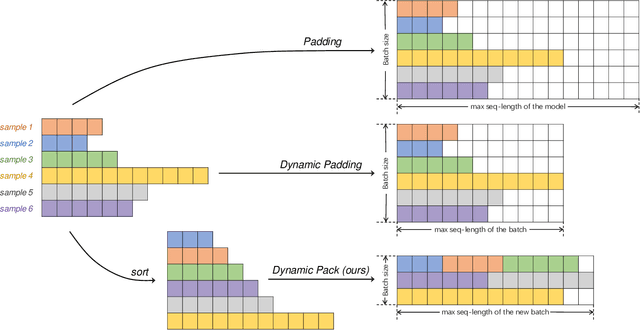
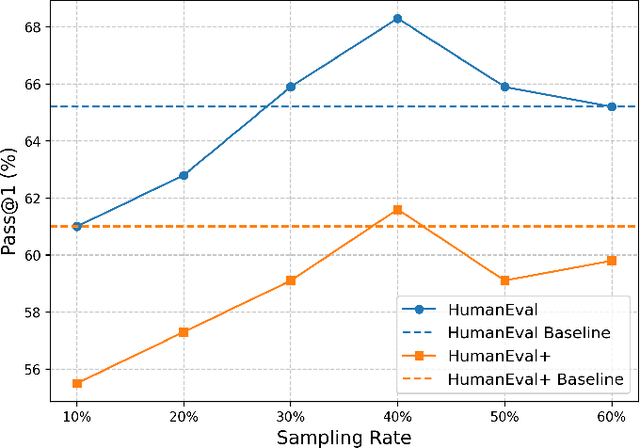
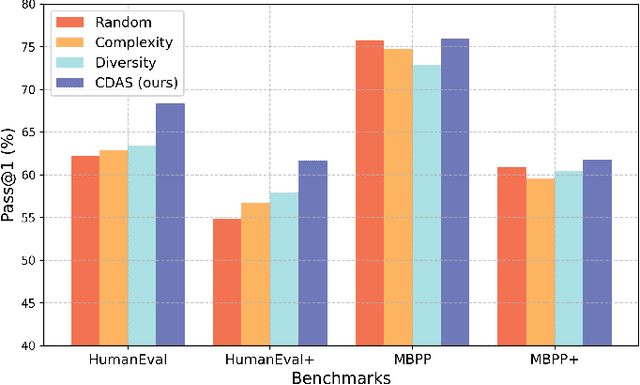
Large language models (LLMs) have shown great potential in code-related tasks, yet open-source models lag behind their closed-source counterparts. To bridge this performance gap, existing methods generate vast amounts of synthetic data for fine-tuning, leading to inefficiencies in training. Motivated by the need for more effective and efficient training, we propose the Code Adaptive Compute-efficient Tuning (CodeACT) framework. CodeACT introduces the Complexity and Diversity Aware Sampling (CDAS) method to select high-quality training data based on complexity and diversity, and the Dynamic Pack padding strategy to reduce computational resource usage by minimizing padding tokens during training. Experimental results demonstrate that CodeACT-DeepSeek-Coder-6.7B, fine-tuned on only 40% of the EVOL-Instruct data, achieves an 8.6% performance increase on HumanEval, reduces training time by 78%, and decreases peak GPU memory usage by 27%. These findings underscore CodeACT's ability to enhance the performance and efficiency of open-source models. By optimizing both the data selection and training processes, CodeACT offers a comprehensive approach to improving the capabilities of open-source LLMs while significantly reducing computational requirements, addressing the dual challenges of data quality and training efficiency, and paving the way for more resource-efficient and performant models.
FractalAD: A simple industrial anomaly segmentation method using fractal anomaly generation and backbone knowledge distillation
Jan 30, 2023



Although industrial anomaly detection (AD) technology has made significant progress in recent years, generating realistic anomalies and learning priors knowledge of normal remain challenging tasks. In this study, we propose an end-to-end industrial anomaly segmentation method called FractalAD. Training samples are obtained by synthesizing fractal images and patches from normal samples. This fractal anomaly generation method is designed to sample the full morphology of anomalies. Moreover, we designed a backbone knowledge distillation structure to extract prior knowledge contained in normal samples. The differences between a teacher and a student model are converted into anomaly attention using a cosine similarity attention module. The proposed method enables an end-to-end semantic segmentation network to be used for anomaly detection without adding any trainable parameters to the backbone and segmentation head. The results of ablation studies confirmed the effectiveness of fractal anomaly generation and backbone knowledge distillation. The results of performance experiments showed that FractalAD achieved competitive results on the MVTec AD dataset compared with other state-of-the-art anomaly detection methods.