 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeACT: Code Adaptive Compute-efficient Tuning Framework for Code LLMs
Paper and Code
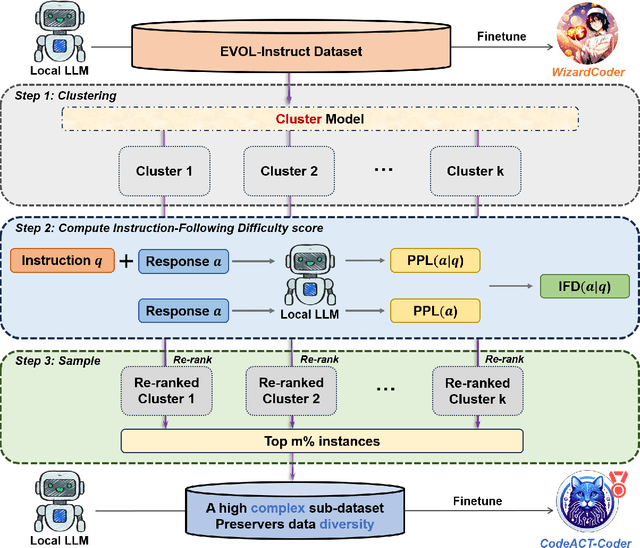
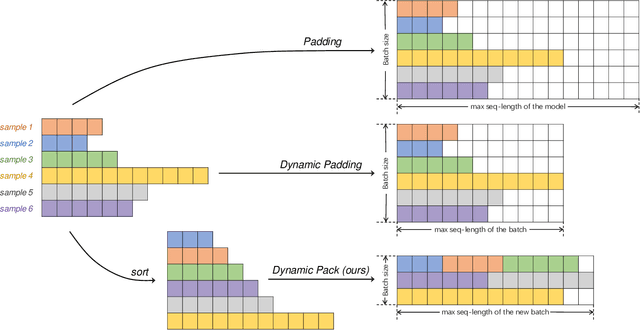
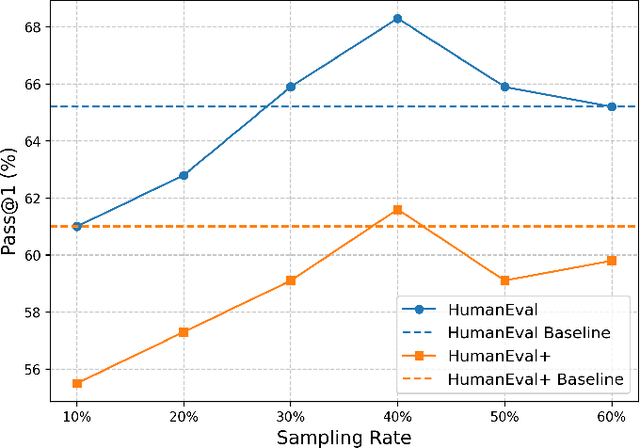
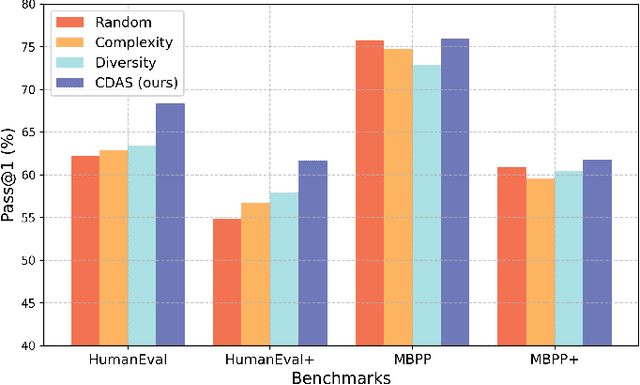
Large language models (LLMs) have shown great potential in code-related tasks, yet open-source models lag behind their closed-source counterparts. To bridge this performance gap, existing methods generate vast amounts of synthetic data for fine-tuning, leading to inefficiencies in training. Motivated by the need for more effective and efficient training, we propose the Code Adaptive Compute-efficient Tuning (CodeACT) framework. CodeACT introduces the Complexity and Diversity Aware Sampling (CDAS) method to select high-quality training data based on complexity and diversity, and the Dynamic Pack padding strategy to reduce computational resource usage by minimizing padding tokens during training. Experimental results demonstrate that CodeACT-DeepSeek-Coder-6.7B, fine-tuned on only 40% of the EVOL-Instruct data, achieves an 8.6% performance increase on HumanEval, reduces training time by 78%, and decreases peak GPU memory usage by 27%. These findings underscore CodeACT's ability to enhance the performance and efficiency of open-source models. By optimizing both the data selection and training processes, CodeACT offers a comprehensive approach to improving the capabilities of open-source LLMs while significantly reducing computational requirements, addressing the dual challenges of data quality and training efficiency, and paving the way for more resource-efficient and performant models.