 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgramming Language Agnostic Mining of Code and Language Pairs with Sequence Labeling Based Question Answering
Mar 21, 2022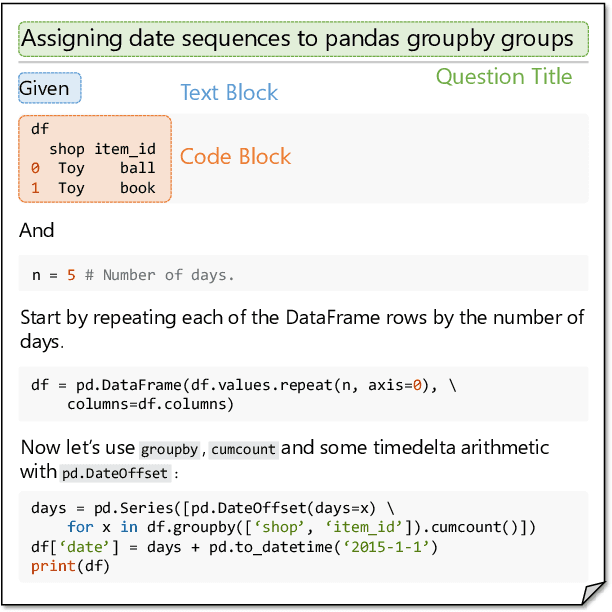
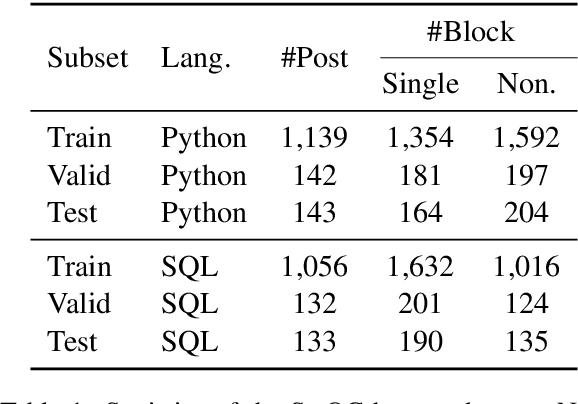
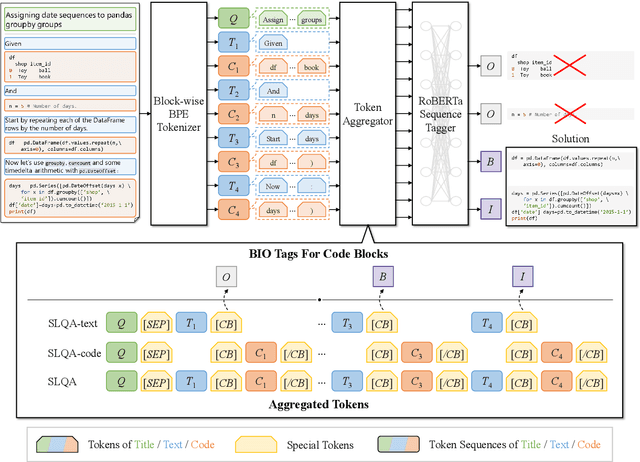
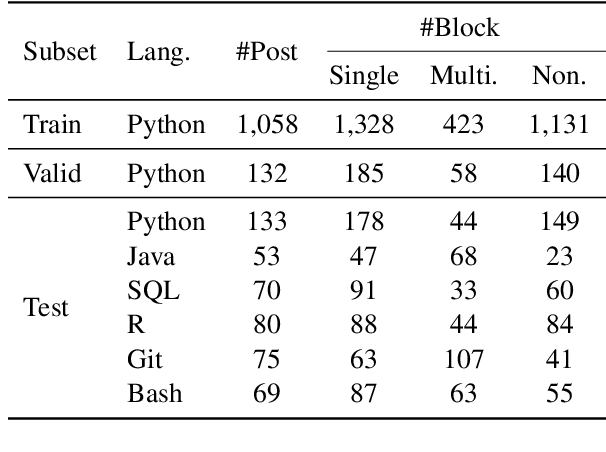
Mining aligned natural language (NL) and programming language (PL) pairs is a critical task to NL-PL understanding. Existing methods applied specialized hand-crafted features or separately-trained models for each PL. However, they usually suffered from low transferability across multiple PLs, especially for niche PLs with less annotated data. Fortunately, a Stack Overflow answer post is essentially a sequence of text and code blocks and its global textual context can provide PL-agnostic supplementary information. In this paper, we propose a Sequence Labeling based Question Answering (SLQA) method to mine NL-PL pairs in a PL-agnostic manner. In particular, we propose to apply the BIO tagging scheme instead of the conventional binary scheme to mine the code solutions which are often composed of multiple blocks of a post. Experiments on current single-PL single-block benchmarks and a manually-labeled cross-PL multi-block benchmark prove the effectiveness and transferability of SLQA. We further present a parallel NL-PL corpus named Lang2Code automatically mined with SLQA, which contains about 1.4M pairs on 6 PLs. Under statistical analysis and downstream evaluation, we demonstrate that Lang2Code is a large-scale high-quality data resource for further NL-PL research.