 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Code with the Help of Retrieved Template Functions and Stack Overflow Answers
Apr 13, 2021

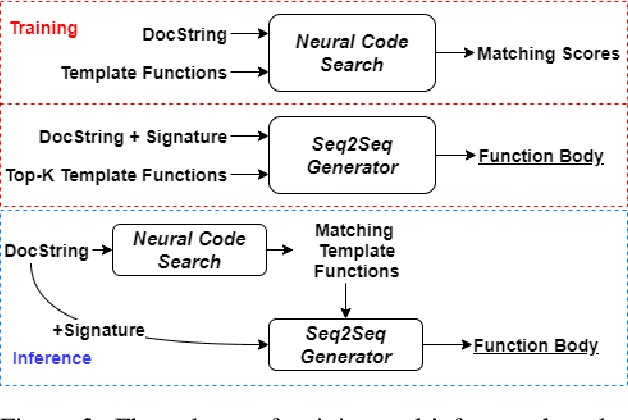

We approach the important challenge of code autocompletion as an open-domain task, in which a sequence-to-sequence code generator model is enhanced with the ability to attend to reference code snippets supplied by a semantic code search engine. In this work, we present a novel framework to precisely retrieve template functions as well as intent-snippet pairs and effectively train such a retrieval-guided code generator. To demonstrate the effectiveness of our model designs, we perform extensive experiments with CodeSearchNet which contains template functions and CoNaLa which contains Stack Overflow intent-snippet pairs. We also investigate different retrieval models, including Elasticsearch, DPR, and our fusion representation search model, which currently holds the number one spot on the CodeSearchNet leaderboard. We observe improvements by leveraging multiple database elements and further gain from retrieving diverse data points by using Maximal Marginal Relevance. Overall, we see a 4% improvement to cross-entropy loss, a 15% improvement to edit distance, and a 44% improvement to BLEU score when retrieving template functions. We see subtler improvements of 2%, 11%, and 6% respectively when retrieving Stack Overflow intent-snippet pairs. We also create a novel Stack Overflow-Function Alignment dataset, which consists of 150K tuples of functions and Stack Overflow intent-snippet pairs that are of help in writing the associated function, of which 1.7K are manually curated.
Automating Image Analysis by Annotating Landmarks with Deep Neural Networks
Feb 02, 2017

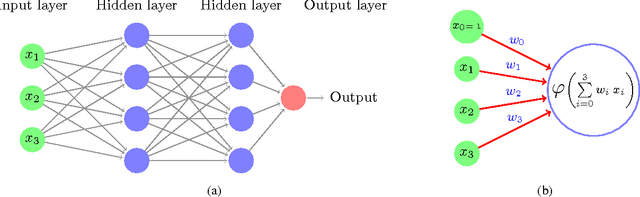

Image and video analysis is often a crucial step in the study of animal behavior and kinematics. Often these analyses require that the position of one or more animal landmarks are annotated (marked) in numerous images. The process of annotating landmarks can require a significant amount of time and tedious labor, which motivates the need for algorithms that can automatically annotate landmarks. In the community of scientists that use image and video analysis to study the 3D flight of animals, there has been a trend of developing more automated approaches for annotating landmarks, yet they fall short of being generally applicable. Inspired by the success of Deep Neural Networks (DNNs) on many problems in the field of computer vision, we investigate how suitable DNNs are for accurate and automatic annotation of landmarks in video datasets representative of those collected by scientists studying animals. Our work shows, through extensive experimentation on videos of hawkmoths, that DNNs are suitable for automatic and accurate landmark localization. In particular, we show that one of our proposed DNNs is more accurate than the current best algorithm for automatic localization of landmarks on hawkmoth videos. Moreover, we demonstrate how these annotations can be used to quantitatively analyze the 3D flight of a hawkmoth. To facilitate the use of DNNs by scientists from many different fields, we provide a self contained explanation of what DNNs are, how they work, and how to apply them to other datasets using the freely available library Caffe and supplemental code that we provide.
Discovering Useful Parts for Pose Estimation in Sparsely Annotated Datasets
May 02, 2016Our work introduces a novel way to increase pose estimation accuracy by discovering parts from unannotated regions of training images. Discovered parts are used to generate more accurate appearance likelihoods for traditional part-based models like Pictorial Structures [13] and its derivatives. Our experiments on images of a hawkmoth in flight show that our proposed approach significantly improves over existing work [27] for this application, while also being more generally applicable. Our proposed approach localizes landmarks at least twice as accurately as a baseline based on a Mixture of Pictorial Structures (MPS) model. Our unique High-Resolution Moth Flight (HRMF) dataset is made publicly available with annotations.