 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Sentence Embedding via Semantic Subspace Analysis
Mar 04, 2020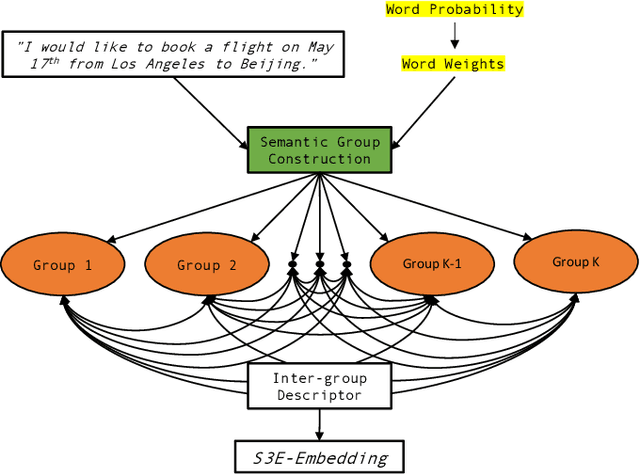
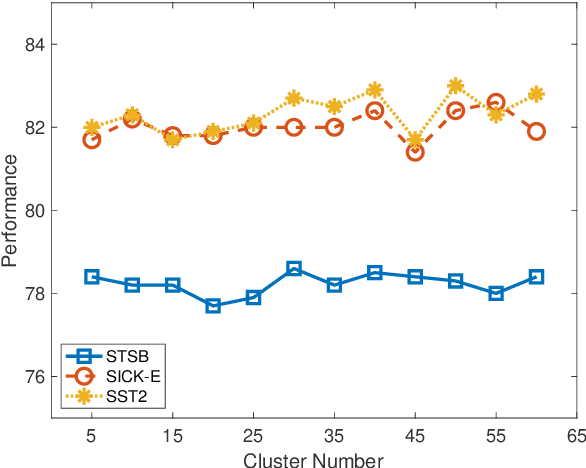


A novel sentence embedding method built upon semantic subspace analysis, called semantic subspace sentence embedding (S3E), is proposed in this work. Given the fact that word embeddings can capture semantic relationship while semantically similar words tend to form semantic groups in a high-dimensional embedding space, we develop a sentence representation scheme by analyzing semantic subspaces of its constituent words. Specifically, we construct a sentence model from two aspects. First, we represent words that lie in the same semantic group using the intra-group descriptor. Second, we characterize the interaction between multiple semantic groups with the inter-group descriptor. The proposed S3E method is evaluated on both textual similarity tasks and supervised tasks. Experimental results show that it offers comparable or better performance than the state-of-the-art. The complexity of our S3E method is also much lower than other parameterized models.
Graph Representation Learning: A Survey
Sep 03, 2019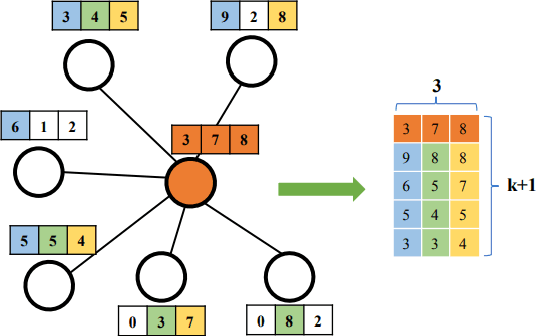
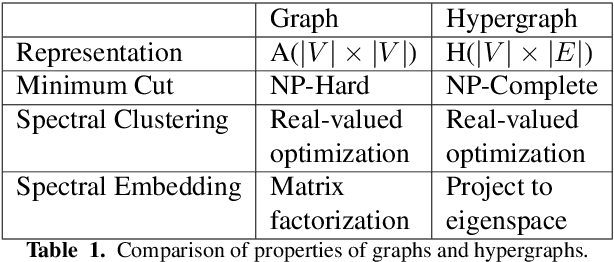
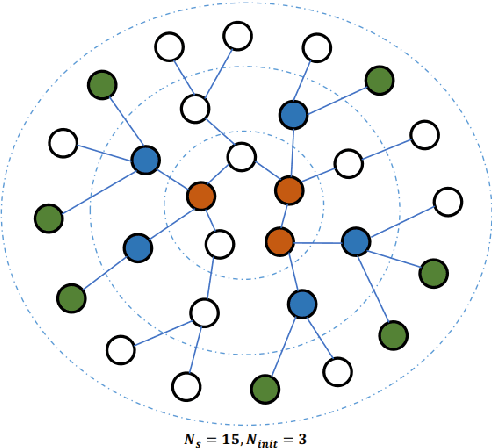
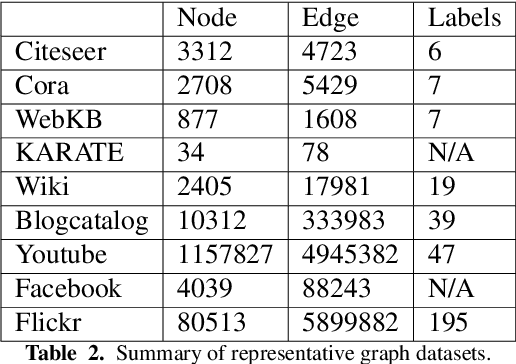
Research on graph representation learning has received a lot of attention in recent years since many data in real-world applications come in form of graphs. High-dimensional graph data are often in irregular form, which makes them more difficult to analyze than image/video/audio data defined on regular lattices. Various graph embedding techniques have been developed to convert the raw graph data into a low-dimensional vector representation while preserving the intrinsic graph properties. In this review, we first explain the graph embedding task and its challenges. Next, we review a wide range of graph embedding techniques with insights. Then, we evaluate several state-of-the-art methods against small and large datasets and compare their performance. Finally, potential applications and future directions are presented.
Evaluating Word Embedding Models: Methods and Experimental Results
Jan 29, 2019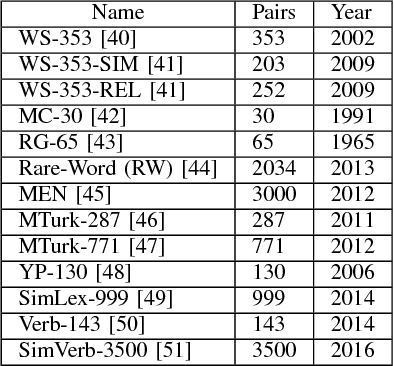

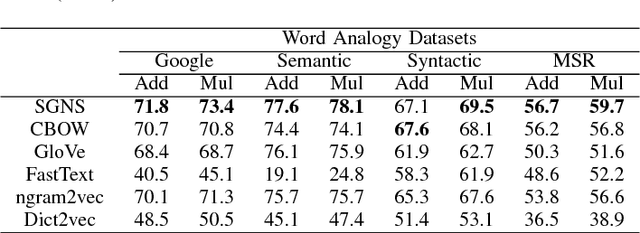
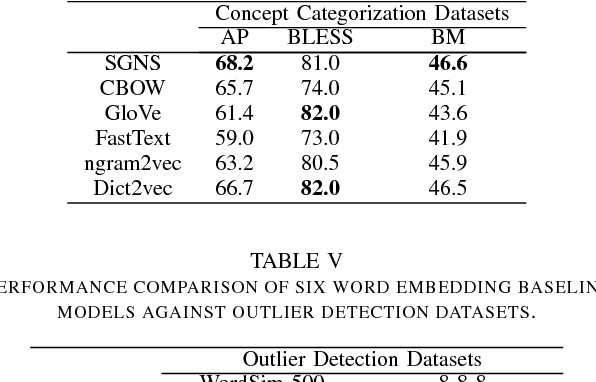
Extensive evaluation on a large number of word embedding models for language processing applications is conducted in this work. First, we introduce popular word embedding models and discuss desired properties of word models and evaluation methods (or evaluators). Then, we categorize evaluators into intrinsic and extrinsic two types. Intrinsic evaluators test the quality of a representation independent of specific natural language processing tasks while extrinsic evaluators use word embeddings as input features to a downstream task and measure changes in performance metrics specific to that task. We report experimental results of intrinsic and extrinsic evaluators on six word embedding models. It is shown that different evaluators focus on different aspects of word models, and some are more correlated with natural language processing tasks. Finally, we adopt correlation analysis to study performance consistency of extrinsic and intrinsic evalutors.
Post-Processing of Word Representations via Variance Normalization and Dynamic Embedding
Sep 05, 2018
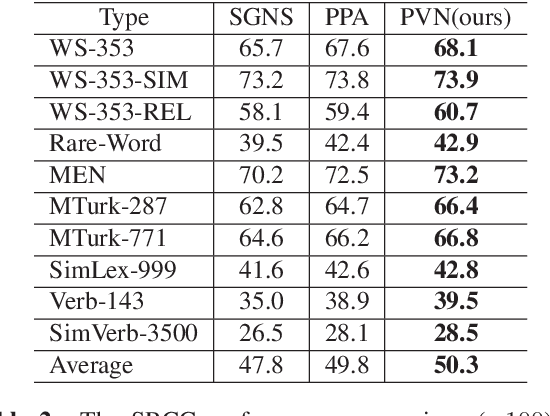
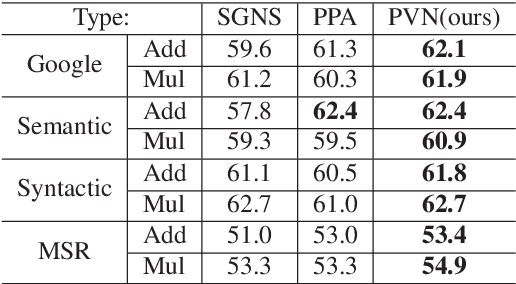
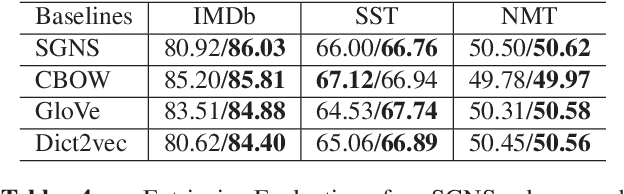
Although embedded vector representations of words offer impressive performance on many natural language processing (NLP) applications, the information of ordered input sequences is lost to some extent if only context-based samples are used in the training. For further performance improvement, two new post-processing techniques, called post-processing via variance normalization (PVN) and post-processing via dynamic embedding (PDE), are proposed in this work. The PVN method normalizes the variance of principal components of word vectors while the PDE method learns orthogonal latent variables from ordered input sequences. The PVN and the PDE methods can be integrated to achieve better performance. We apply these post-processing techniques to two popular word embedding methods (i.e., word2vec and GloVe) to yield their post-processed representations. Extensive experiments are conducted to demonstrate the effectiveness of the proposed post-processing techniques.
Graph-based Deep-Tree Recursive Neural Network (DTRNN) for Text Classification
Sep 04, 2018

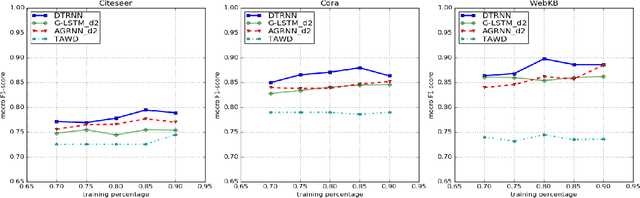
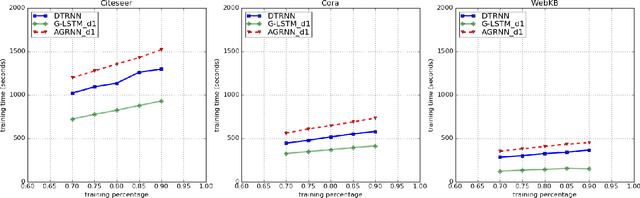
A novel graph-to-tree conversion mechanism called the deep-tree generation (DTG) algorithm is first proposed to predict text data represented by graphs. The DTG method can generate a richer and more accurate representation for nodes (or vertices) in graphs. It adds flexibility in exploring the vertex neighborhood information to better reflect the second order proximity and homophily equivalence in a graph. Then, a Deep-Tree Recursive Neural Network (DTRNN) method is presented and used to classify vertices that contains text data in graphs. To demonstrate the effectiveness of the DTRNN method, we apply it to three real-world graph datasets and show that the DTRNN method outperforms several state-of-the-art benchmarking methods.