 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost-Processing of Word Representations via Variance Normalization and Dynamic Embedding
Paper and Code
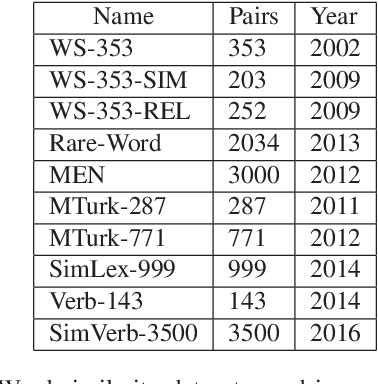
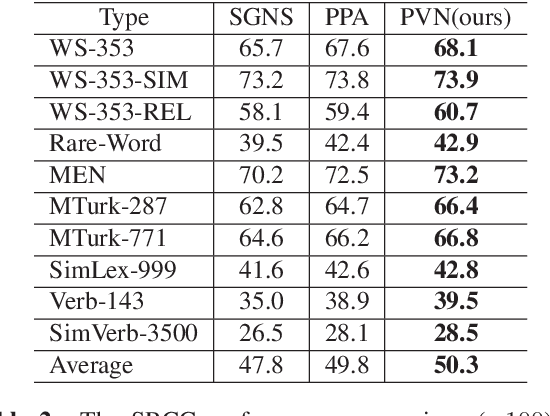
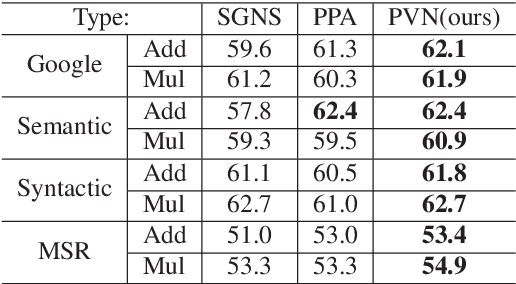
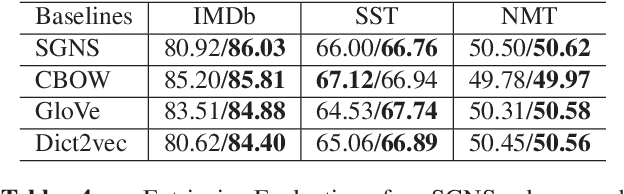
Although embedded vector representations of words offer impressive performance on many natural language processing (NLP) applications, the information of ordered input sequences is lost to some extent if only context-based samples are used in the training. For further performance improvement, two new post-processing techniques, called post-processing via variance normalization (PVN) and post-processing via dynamic embedding (PDE), are proposed in this work. The PVN method normalizes the variance of principal components of word vectors while the PDE method learns orthogonal latent variables from ordered input sequences. The PVN and the PDE methods can be integrated to achieve better performance. We apply these post-processing techniques to two popular word embedding methods (i.e., word2vec and GloVe) to yield their post-processed representations. Extensive experiments are conducted to demonstrate the effectiveness of the proposed post-processing techniques.