 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Optimization of Graph Convolutional Network using Subgraph Variance
Paper and Code
Oct 06, 2021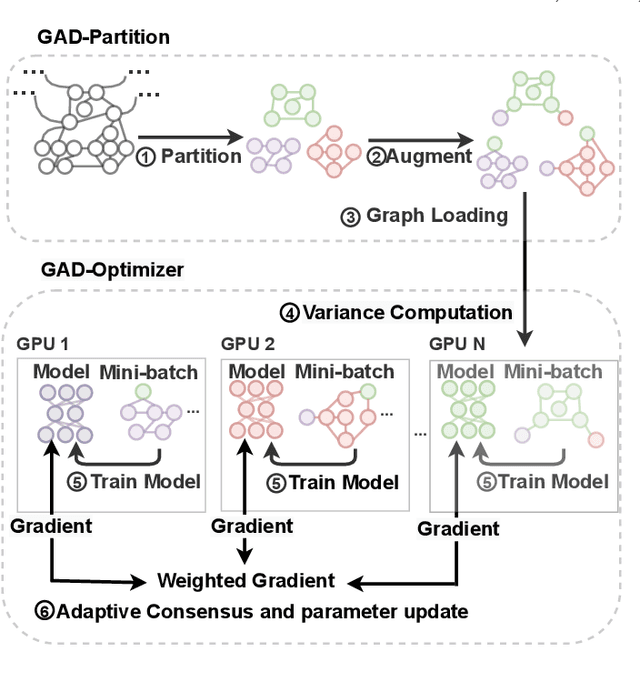


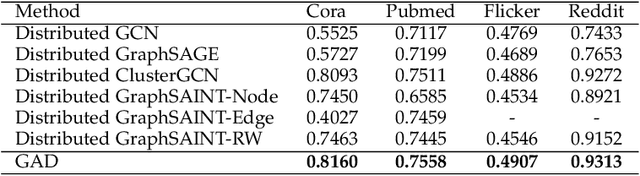
In recent years, Graph Convolutional Networks (GCNs) have achieved great success in learning from graph-structured data. With the growing tendency of graph nodes and edges, GCN training by single processor cannot meet the demand for time and memory, which led to a boom into distributed GCN training frameworks research. However, existing distributed GCN training frameworks require enormous communication costs between processors since multitudes of dependent nodes and edges information need to be collected and transmitted for GCN training from other processors. To address this issue, we propose a Graph Augmentation based Distributed GCN framework(GAD). In particular, GAD has two main components, GAD-Partition and GAD-Optimizer. We first propose a graph augmentation-based partition (GAD-Partition) that can divide original graph into augmented subgraphs to reduce communication by selecting and storing as few significant nodes of other processors as possible while guaranteeing the accuracy of the training. In addition, we further design a subgraph variance-based importance calculation formula and propose a novel weighted global consensus method, collectively referred to as GAD-Optimizer. This optimizer adaptively reduces the importance of subgraphs with large variances for the purpose of reducing the effect of extra variance introduced by GAD-Partition on distributed GCN training. Extensive experiments on four large-scale real-world datasets demonstrate that our framework significantly reduces the communication overhead (50%), improves the convergence speed (2X) of distributed GCN training, and slight gain in accuracy (0.45%) based on minimal redundancy compared to the state-of-the-art methods.