 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Sentiment Analysis: Perceived vs Induced Sentiments
Dec 12, 2023Social media has created a global network where people can easily access and exchange vast information. This information gives rise to a variety of opinions, reflecting both positive and negative viewpoints. GIFs stand out as a multimedia format offering a visually engaging way for users to communicate. In this research, we propose a multimodal framework that integrates visual and textual features to predict the GIF sentiment. It also incorporates attributes including face emotion detection and OCR generated captions to capture the semantic aspects of the GIF. The developed classifier achieves an accuracy of 82.7% on Twitter GIFs, which is an improvement over state-of-the-art models. Moreover, we have based our research on the ReactionGIF dataset, analysing the variance in sentiment perceived by the author and sentiment induced in the reader
An Automated Multi-Web Platform Voting Framework to Predict Misleading Information Proliferated during COVID-19 Outbreak using Ensemble Method
Sep 19, 2021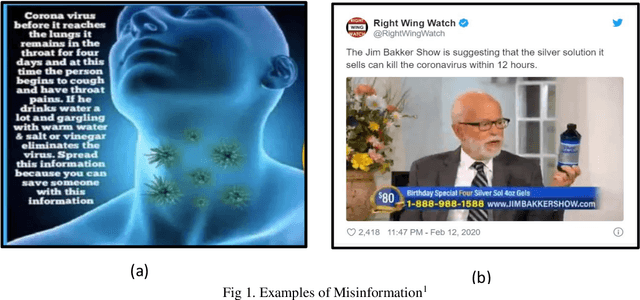

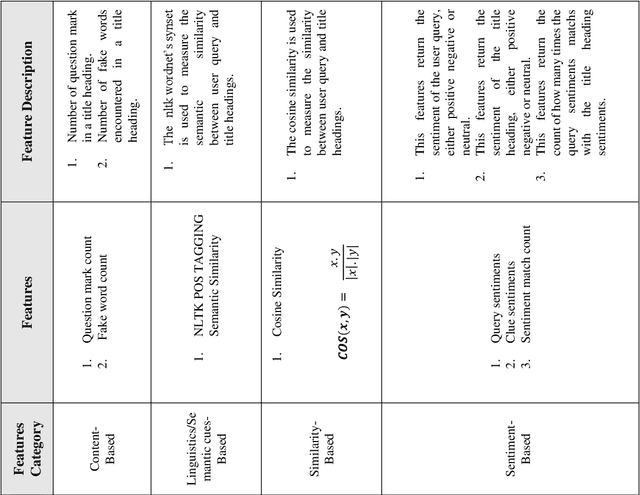
Spreading of misleading information on social web platforms has fuelled huge panic and confusion among the public regarding the Corona disease, the detection of which is of paramount importance. To address this issue, in this paper, we have developed an automated system that can collect and validate the fact from multi web-platform to decide the credibility of the content. To identify the credibility of the posted claim, probable instances/clues(titles) of news information are first gathered from various web platforms. Later, the crucial set of features is retrieved that further feeds into the ensemble-based machine learning model to classify the news as misleading or real. The four sets of features based on the content, linguistics/semantic cues, similarity, and sentiments gathered from web-platforms and voting are applied to validate the news. Finally, the combined voting decides the support given to a specific claim. In addition to the validation part, a unique source platform is designed for collecting data/facts from three web platforms (Twitter, Facebook, Google) based on certain queries/words. This unique platform can also help researchers build datasets and gather useful/efficient clues from various web platforms. It has been observed that our proposed intelligent strategy gives promising results and quite effective in predicting misleading information. The proposed work provides practical implications for the policy makers and health practitioners that could be useful in protecting the world from misleading information proliferation during this pandemic.