 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Data Imputation using Constraints
May 10, 2022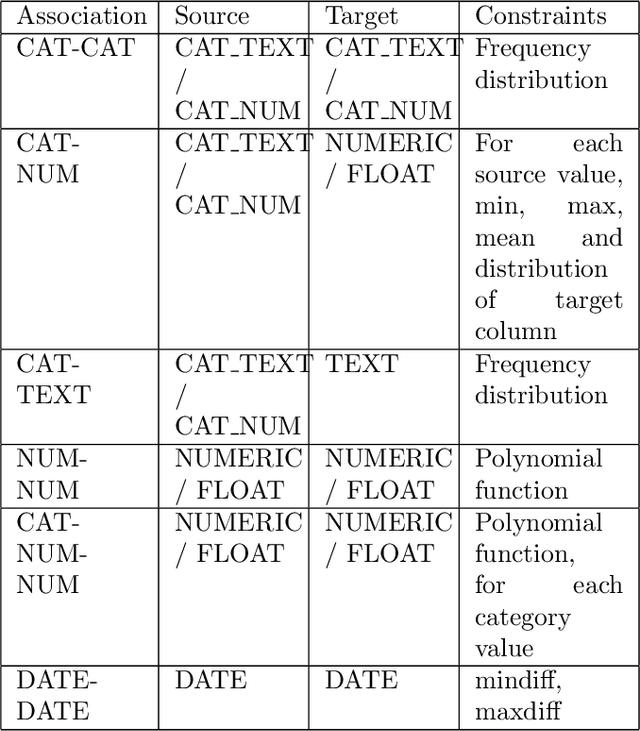
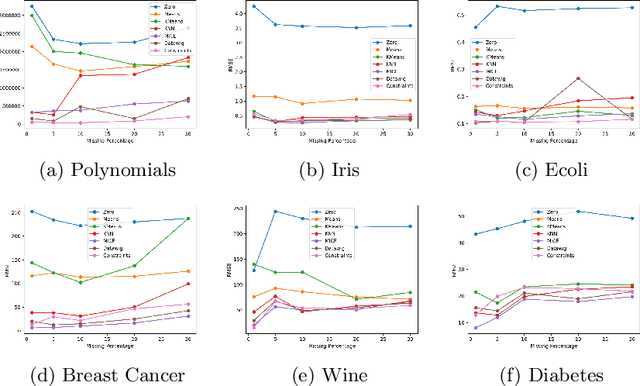
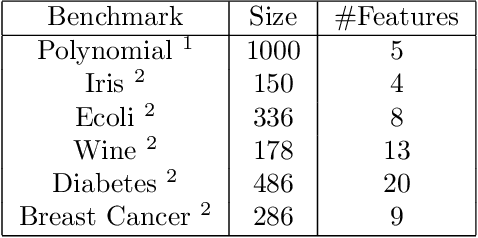
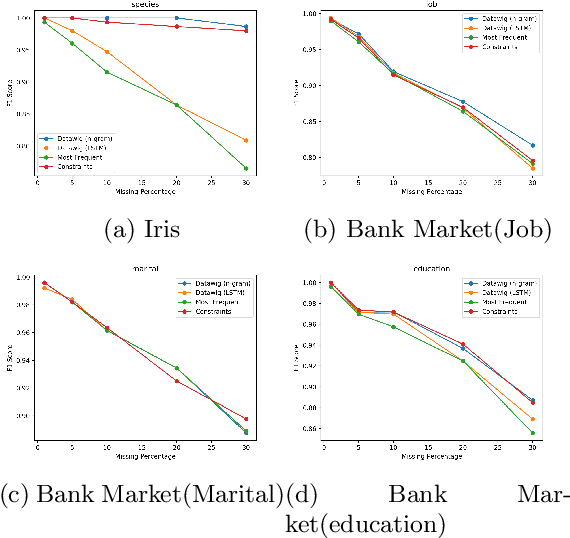
Data values in a dataset can be missing or anomalous due to mishandling or human error. Analysing data with missing values can create bias and affect the inferences. Several analysis methods, such as principle components analysis or singular value decomposition, require complete data. Many approaches impute numeric data and some do not consider dependency of attributes on other attributes, while some require human intervention and domain knowledge. We present a new algorithm for data imputation based on different data type values and their association constraints in data, which are not handled currently by any system. We show experimental results using different metrics comparing our algorithm with state of the art imputation techniques. Our algorithm not only imputes the missing values but also generates human readable explanations describing the significance of attributes used for every imputation.
Data Synthesis for Testing Black-Box Machine Learning Models
Nov 03, 2021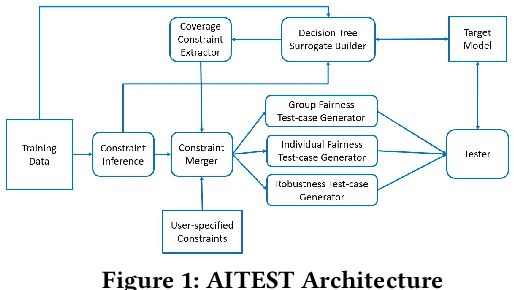
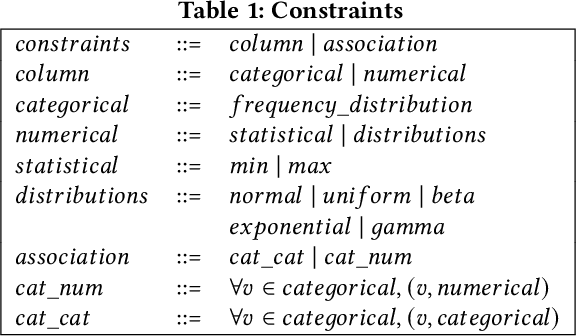
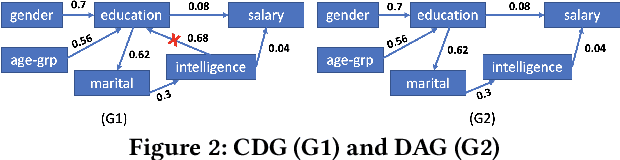
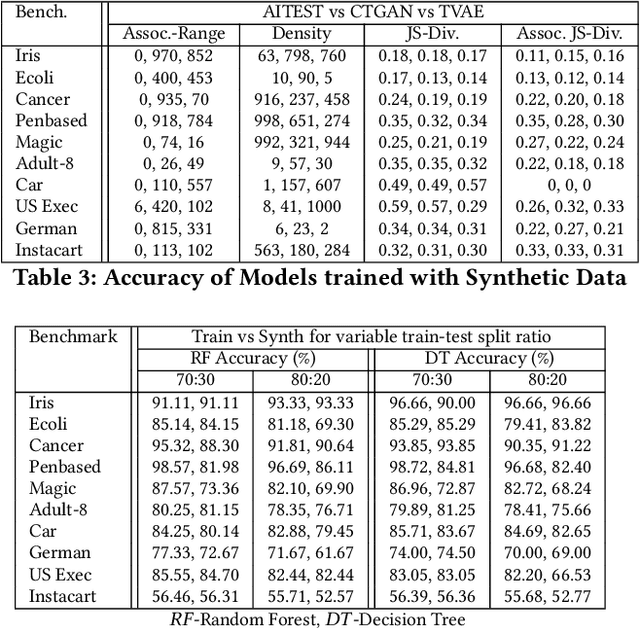
The increasing usage of machine learning models raises the question of the reliability of these models. The current practice of testing with limited data is often insufficient. In this paper, we provide a framework for automated test data synthesis to test black-box ML/DL models. We address an important challenge of generating realistic user-controllable data with model agnostic coverage criteria to test a varied set of properties, essentially to increase trust in machine learning models. We experimentally demonstrate the effectiveness of our technique.
Data Quality Toolkit: Automatic assessment of data quality and remediation for machine learning datasets
Sep 05, 2021

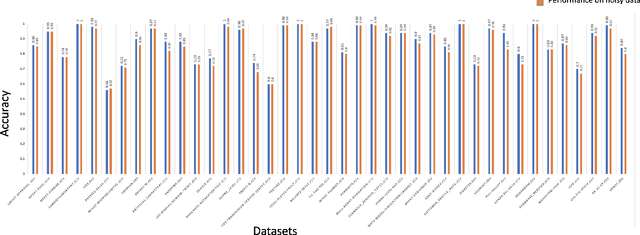
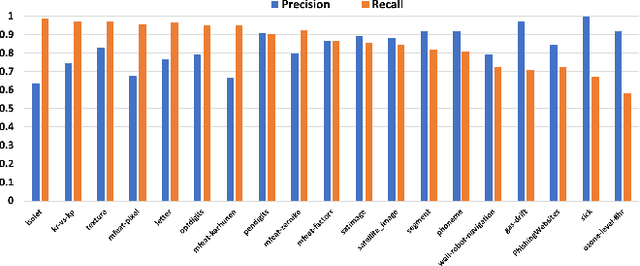
The quality of training data has a huge impact on the efficiency, accuracy and complexity of machine learning tasks. Various tools and techniques are available that assess data quality with respect to general cleaning and profiling checks. However these techniques are not applicable to detect data issues in the context of machine learning tasks, like noisy labels, existence of overlapping classes etc. We attempt to re-look at the data quality issues in the context of building a machine learning pipeline and build a tool that can detect, explain and remediate issues in the data, and systematically and automatically capture all the changes applied to the data. We introduce the Data Quality Toolkit for machine learning as a library of some key quality metrics and relevant remediation techniques to analyze and enhance the readiness of structured training datasets for machine learning projects. The toolkit can reduce the turn-around times of data preparation pipelines and streamline the data quality assessment process. Our toolkit is publicly available via IBM API Hub [1] platform, any developer can assess the data quality using the IBM's Data Quality for AI apis [2]. Detailed tutorials are also available on IBM Learning Path [3].
Testing Framework for Black-box AI Models
Feb 11, 2021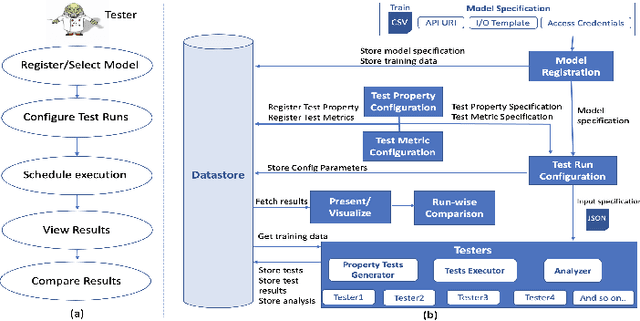
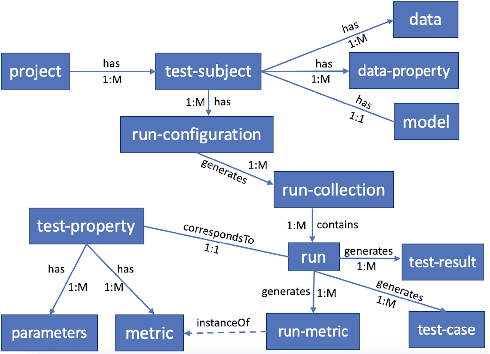
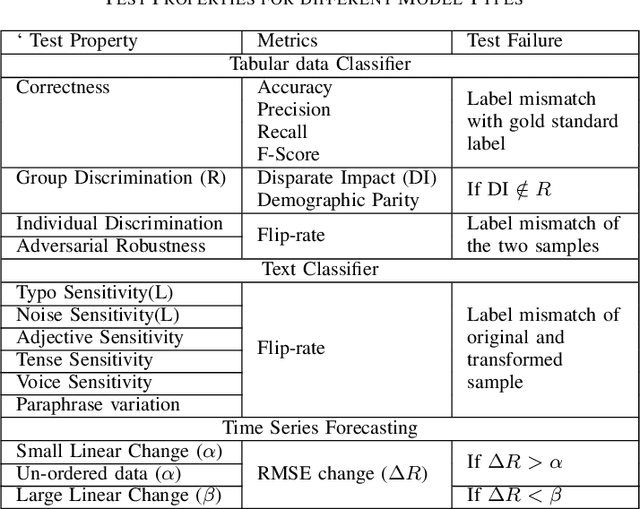
With widespread adoption of AI models for important decision making, ensuring reliability of such models remains an important challenge. In this paper, we present an end-to-end generic framework for testing AI Models which performs automated test generation for different modalities such as text, tabular, and time-series data and across various properties such as accuracy, fairness, and robustness. Our tool has been used for testing industrial AI models and was very effective to uncover issues present in those models. Demo video link: https://youtu.be/984UCU17YZI