 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTesting Framework for Black-box AI Models
Feb 11, 2021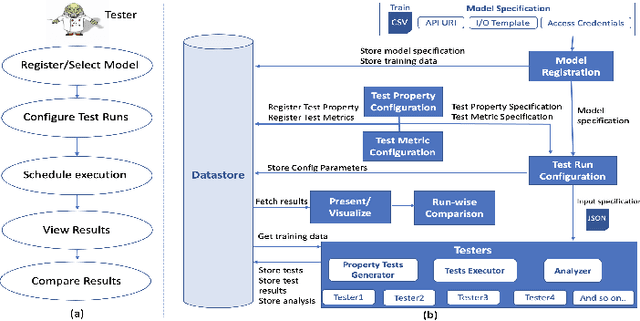
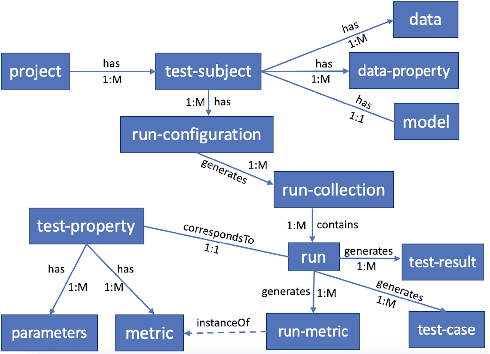
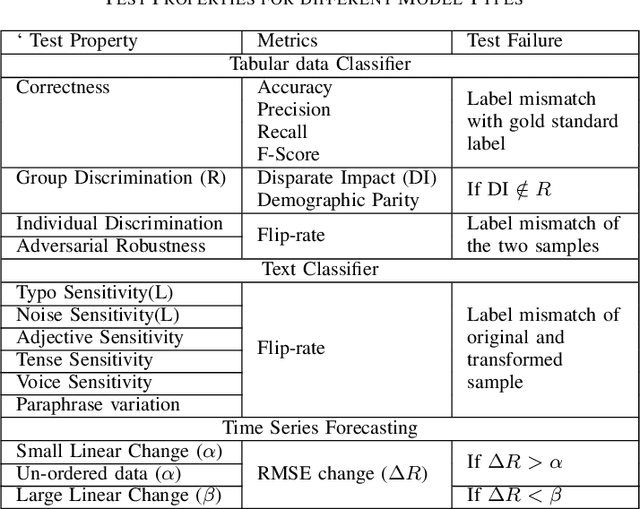
With widespread adoption of AI models for important decision making, ensuring reliability of such models remains an important challenge. In this paper, we present an end-to-end generic framework for testing AI Models which performs automated test generation for different modalities such as text, tabular, and time-series data and across various properties such as accuracy, fairness, and robustness. Our tool has been used for testing industrial AI models and was very effective to uncover issues present in those models. Demo video link: https://youtu.be/984UCU17YZI
Extracting Fairness Policies from Legal Documents
Sep 12, 2018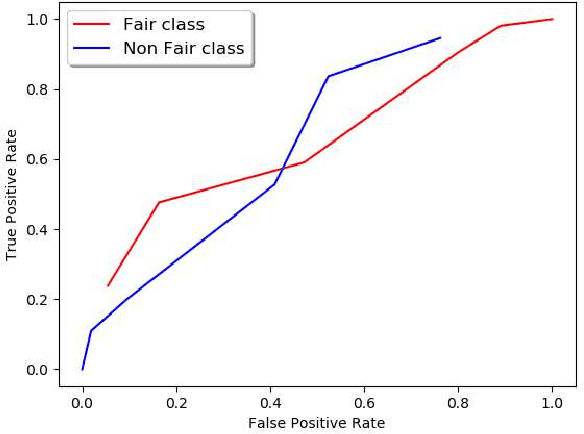
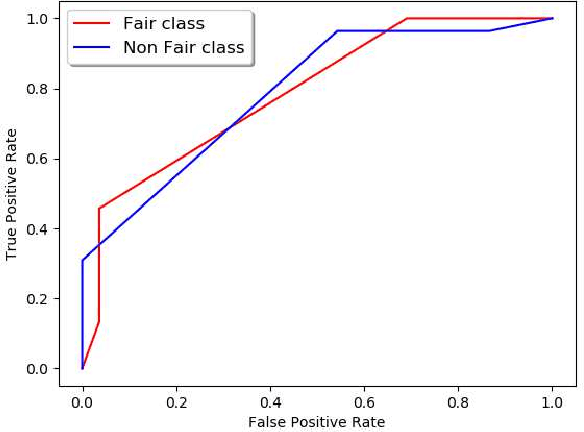
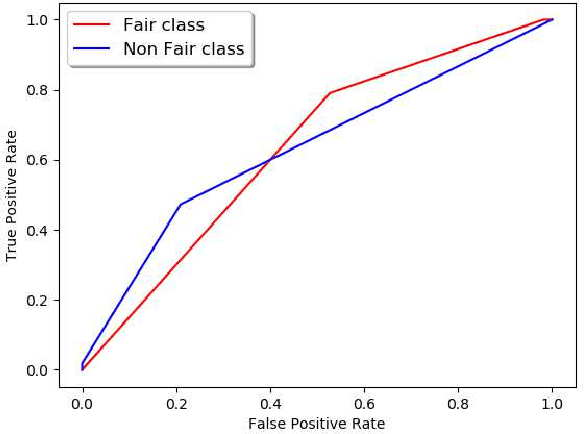
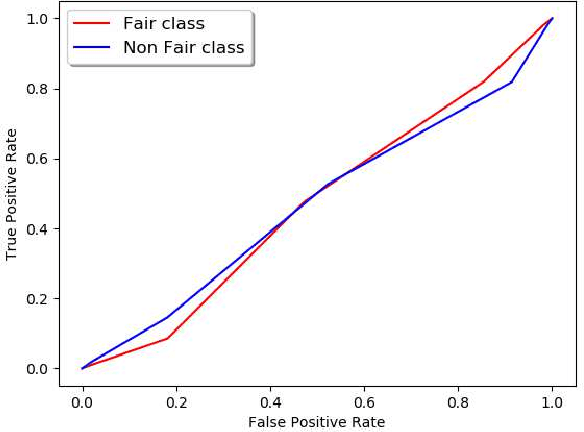
Machine Learning community is recently exploring the implications of bias and fairness with respect to the AI applications. The definition of fairness for such applications varies based on their domain of application. The policies governing the use of such machine learning system in a given context are defined by the constitutional laws of nations and regulatory policies enforced by the organizations that are involved in the usage. Fairness related laws and policies are often spread across the large documents like constitution, agreements, and organizational regulations. These legal documents have long complex sentences in order to achieve rigorousness and robustness. Automatic extraction of fairness policies, or in general, any specific kind of policies from large legal corpus can be very useful for the study of bias and fairness in the context of AI applications. We attempted to automatically extract fairness policies from publicly available law documents using two approaches based on semantic relatedness. The experiments reveal how classical Wordnet-based similarity and vector-based similarity differ in addressing this task. We have shown that similarity based on word vectors beats the classical approach with a large margin, whereas other vector representations of senses and sentences fail to even match the classical baseline. Further, we have presented thorough error analysis and reasoning to explain the results with appropriate examples from the dataset for deeper insights.