 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBARET : Balanced Attention based Real image Editing driven by Target-text Inversion
Paper and Code
Dec 09, 2023
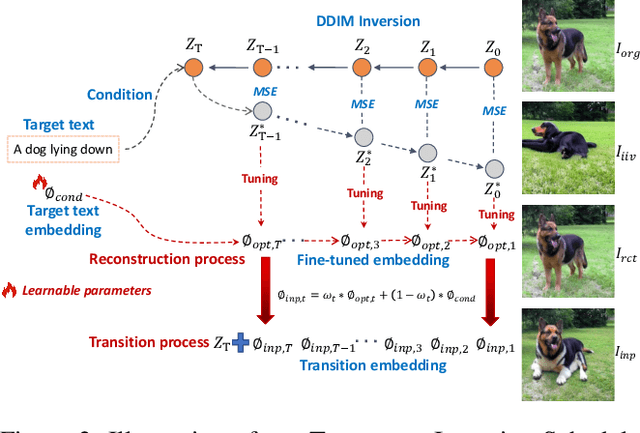


Image editing approaches with diffusion models have been rapidly developed, yet their applicability are subject to requirements such as specific editing types (e.g., foreground or background object editing, style transfer), multiple conditions (e.g., mask, sketch, caption), and time consuming fine-tuning of diffusion models. For alleviating these limitations and realizing efficient real image editing, we propose a novel editing technique that only requires an input image and target text for various editing types including non-rigid edits without fine-tuning diffusion model. Our method contains three novelties:(I) Target-text Inversion Schedule (TTIS) is designed to fine-tune the input target text embedding to achieve fast image reconstruction without image caption and acceleration of convergence.(II) Progressive Transition Scheme applies progressive linear interpolation between target text embedding and its fine-tuned version to generate transition embedding for maintaining non-rigid editing capability.(III) Balanced Attention Module (BAM) balances the tradeoff between textual description and image semantics.By the means of combining self-attention map from reconstruction process and cross-attention map from transition process, the guidance of target text embeddings in diffusion process is optimized.In order to demonstrate editing capability, effectiveness and efficiency of the proposed BARET, we have conducted extensive qualitative and quantitative experiments. Moreover, results derived from user study and ablation study further prove the superiority over other methods.