 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study of Situational Reasoning for Traffic Understanding
Jun 05, 2023
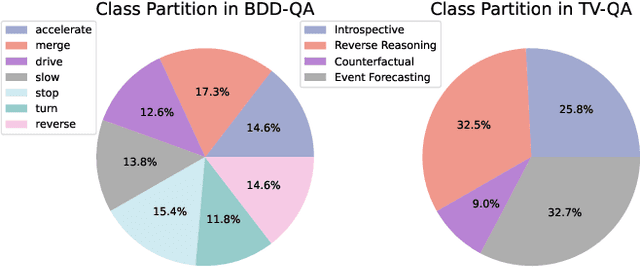

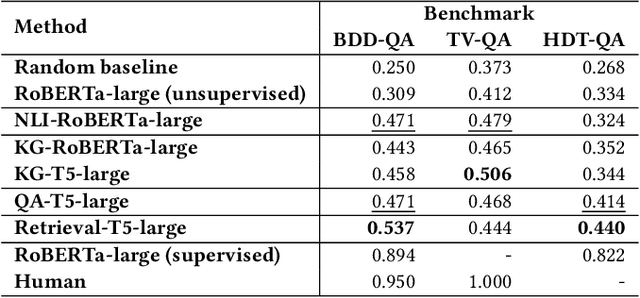
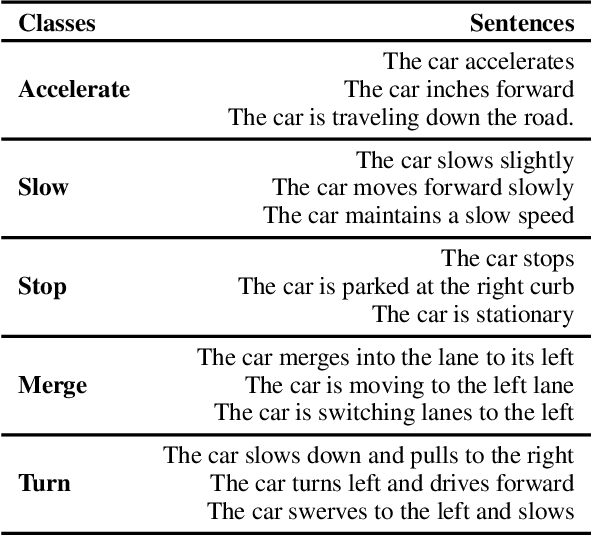
Intelligent Traffic Monitoring (ITMo) technologies hold the potential for improving road safety/security and for enabling smart city infrastructure. Understanding traffic situations requires a complex fusion of perceptual information with domain-specific and causal commonsense knowledge. Whereas prior work has provided benchmarks and methods for traffic monitoring, it remains unclear whether models can effectively align these information sources and reason in novel scenarios. To address this assessment gap, we devise three novel text-based tasks for situational reasoning in the traffic domain: i) BDD-QA, which evaluates the ability of Language Models (LMs) to perform situational decision-making, ii) TV-QA, which assesses LMs' abilities to reason about complex event causality, and iii) HDT-QA, which evaluates the ability of models to solve human driving exams. We adopt four knowledge-enhanced methods that have shown generalization capability across language reasoning tasks in prior work, based on natural language inference, commonsense knowledge-graph self-supervision, multi-QA joint training, and dense retrieval of domain information. We associate each method with a relevant knowledge source, including knowledge graphs, relevant benchmarks, and driving manuals. In extensive experiments, we benchmark various knowledge-aware methods against the three datasets, under zero-shot evaluation; we provide in-depth analyses of model performance on data partitions and examine model predictions categorically, to yield useful insights on traffic understanding, given different background knowledge and reasoning strategies.
Utilizing Background Knowledge for Robust Reasoning over Traffic Situations
Dec 04, 2022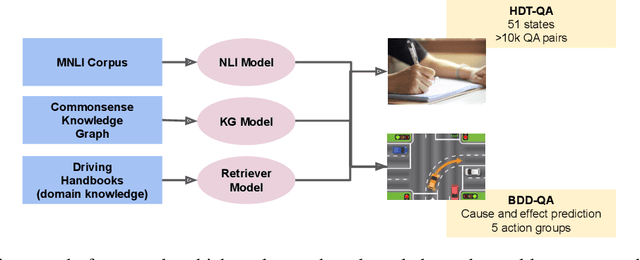

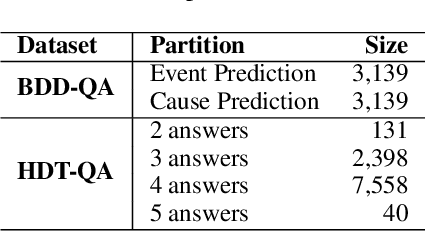
Understanding novel situations in the traffic domain requires an intricate combination of domain-specific and causal commonsense knowledge. Prior work has provided sufficient perception-based modalities for traffic monitoring, in this paper, we focus on a complementary research aspect of Intelligent Transportation: traffic understanding. We scope our study to text-based methods and datasets given the abundant commonsense knowledge that can be extracted using language models from large corpus and knowledge graphs. We adopt three knowledge-driven approaches for zero-shot QA over traffic situations, based on prior natural language inference methods, commonsense models with knowledge graph self-supervision, and dense retriever-based models. We constructed two text-based multiple-choice question answering sets: BDD-QA for evaluating causal reasoning in the traffic domain and HDT-QA for measuring the possession of domain knowledge akin to human driving license tests. Among the methods, Unified-QA reaches the best performance on the BDD-QA dataset with the adaptation of multiple formats of question answers. Language models trained with inference information and commonsense knowledge are also good at predicting the cause and effect in the traffic domain but perform badly at answering human-driving QA sets. For such sets, DPR+Unified-QA performs the best due to its efficient knowledge extraction.