 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Negative Interference in Multilingual Sequential Knowledge Editing through Null-Space Constraints
Jun 12, 2025Efficiently updating multilingual knowledge in large language models (LLMs), while preserving consistent factual representations across languages, remains a long-standing and unresolved challenge. While deploying separate editing systems for each language might seem viable, this approach incurs substantial costs due to the need to manage multiple models. A more efficient solution involves integrating knowledge updates across all languages into a unified model. However, performing sequential edits across languages often leads to destructive parameter interference, significantly degrading multilingual generalization and the accuracy of injected knowledge. To address this challenge, we propose LangEdit, a novel null-space constrained framework designed to precisely isolate language-specific knowledge updates. The core innovation of LangEdit lies in its ability to project parameter updates for each language onto the orthogonal complement of previous updated subspaces. This approach mathematically guarantees update independence while preserving multilingual generalization capabilities. We conduct a comprehensive evaluation across three model architectures, six languages, and four downstream tasks, demonstrating that LangEdit effectively mitigates parameter interference and outperforms existing state-of-the-art editing methods. Our results highlight its potential for enabling efficient and accurate multilingual knowledge updates in LLMs. The code is available at https://github.com/VRCMF/LangEdit.git.
Towards More Accurate Personalized Image Generation: Addressing Overfitting and Evaluation Bias
Mar 09, 2025Personalized image generation via text prompts has great potential to improve daily life and professional work by facilitating the creation of customized visual content. The aim of image personalization is to create images based on a user-provided subject while maintaining both consistency of the subject and flexibility to accommodate various textual descriptions of that subject. However, current methods face challenges in ensuring fidelity to the text prompt while not overfitting to the training data. In this work, we introduce a novel training pipeline that incorporates an attractor to filter out distractions in training images, allowing the model to focus on learning an effective representation of the personalized subject. Moreover, current evaluation methods struggle due to the lack of a dedicated test set. The evaluation set-up typically relies on the training data of the personalization task to compute text-image and image-image similarity scores, which, while useful, tend to overestimate performance. Although human evaluations are commonly used as an alternative, they often suffer from bias and inconsistency. To address these issues, we curate a diverse and high-quality test set with well-designed prompts. With this new benchmark, automatic evaluation metrics can reliably assess model performance
TS-LLaVA: Constructing Visual Tokens through Thumbnail-and-Sampling for Training-Free Video Large Language Models
Nov 17, 2024Recent advances in multimodal Large Language Models (LLMs) have shown great success in understanding multi-modal contents. For video understanding tasks, training-based video LLMs are difficult to build due to the scarcity of high-quality, curated video-text paired data. In contrast, paired image-text data are much easier to obtain, and there is substantial similarity between images and videos. Consequently, extending image LLMs for video understanding tasks presents an appealing alternative. Developing effective strategies for compressing visual tokens from multiple frames is a promising way to leverage the powerful pre-trained image LLM. In this work, we explore the limitations of the existing compression strategies for building a training-free video LLM. The findings lead to our method TS-LLaVA, which constructs visual tokens through a Thumbnail-and-Sampling strategy. Given a video, we select few equidistant frames from all input frames to construct a Thumbnail image as a detailed visual cue, complemented by Sampled visual tokens from all input frames. Our method establishes the new state-of-the-art performance among training-free video LLMs on various benchmarks. Notably, our 34B model outperforms GPT-4V on the MVBench benchmark, and achieves performance comparable to the 72B training-based video LLM, Video-LLaMA2, on the challenging MLVU benchmark. Code is available at https://github.com/tingyu215/TS-LLaVA.
Introducing Routing Functions to Vision-Language Parameter-Efficient Fine-Tuning with Low-Rank Bottlenecks
Mar 14, 2024Mainstream parameter-efficient fine-tuning (PEFT) methods, such as LoRA or Adapter, project a model's hidden states to a lower dimension, allowing pre-trained models to adapt to new data through this low-rank bottleneck. However, PEFT tasks involving multiple modalities, like vision-language (VL) tasks, require not only adaptation to new data but also learning the relationship between different modalities. Targeting at VL PEFT tasks, we propose a family of operations, called routing functions, to enhance VL alignment in the low-rank bottlenecks. The routing functions adopt linear operations and do not introduce new trainable parameters. In-depth analyses are conducted to study their behavior. In various VL PEFT settings, the routing functions significantly improve performance of the original PEFT methods, achieving over 20% improvement on VQAv2 ($\text{RoBERTa}_{\text{large}}$+ViT-L/16) and 30% on COCO Captioning (GPT2-medium+ViT-L/16). Also when fine-tuning a pre-trained multimodal model such as CLIP-BART, we observe smaller but consistent improvements across a range of VL PEFT tasks.
Visually-Aware Context Modeling for News Image Captioning
Aug 16, 2023The goal of News Image Captioning is to generate an image caption according to the content of both a news article and an image. To leverage the visual information effectively, it is important to exploit the connection between the context in the articles/captions and the images. Psychological studies indicate that human faces in images draw higher attention priorities. On top of that, humans often play a central role in news stories, as also proven by the face-name co-occurrence pattern we discover in existing News Image Captioning datasets. Therefore, we design a face-naming module for faces in images and names in captions/articles to learn a better name embedding. Apart from names, which can be directly linked to an image area (faces), news image captions mostly contain context information that can only be found in the article. Humans typically address this by searching for relevant information from the article based on the image. To emulate this thought process, we design a retrieval strategy using CLIP to retrieve sentences that are semantically close to the image. We conduct extensive experiments to demonstrate the efficacy of our framework. Without using additional paired data, we establish the new state-of-the-art performance on two News Image Captioning datasets, exceeding the previous state-of-the-art by 5 CIDEr points. We will release code upon acceptance.
Alleviating Exposure Bias in Diffusion Models through Sampling with Shifted Time Steps
May 26, 2023

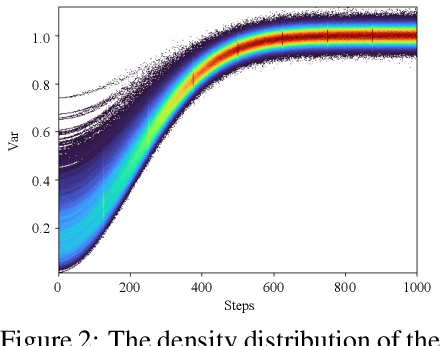

Denoising Diffusion Probabilistic Models (DDPM) have shown remarkable efficacy in the synthesis of high-quality images. However, their inference process characteristically requires numerous, potentially hundreds, of iterative steps, which could lead to the problem of exposure bias due to the accumulation of prediction errors over iterations. Previous work has attempted to mitigate this issue by perturbing inputs during training, which consequently mandates the retraining of the DDPM. In this work, we conduct a systematic study of exposure bias in diffusion models and, intriguingly, we find that the exposure bias could be alleviated with a new sampling method, without retraining the model. We empirically and theoretically show that, during inference, for each backward time step $t$ and corresponding state $\hat{x}_t$, there might exist another time step $t_s$ which exhibits superior coupling with $\hat{x}_t$. Based on this finding, we introduce an inference method named Time-Shift Sampler. Our framework can be seamlessly integrated with existing sampling algorithms, such as DDIM or DDPM, inducing merely minimal additional computations. Experimental results show that our proposed framework can effectively enhance the quality of images generated by existing sampling algorithms.
Weakly Supervised Face Naming with Symmetry-Enhanced Contrastive Loss
Oct 17, 2022
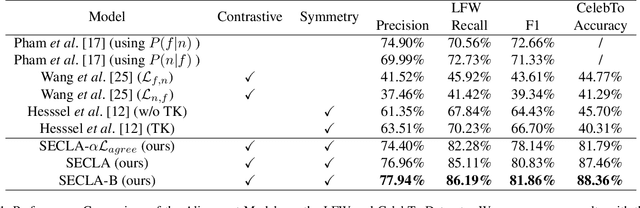
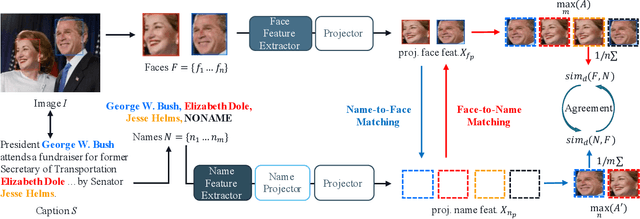
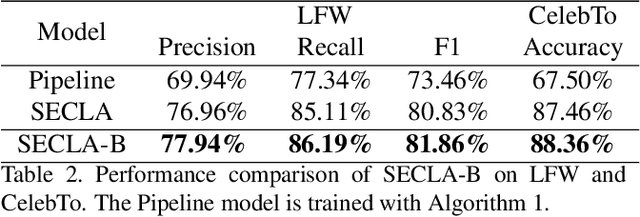
We revisit the weakly supervised cross-modal face-name alignment task; that is, given an image and a caption, we label the faces in the image with the names occurring in the caption. Whereas past approaches have learned the latent alignment between names and faces by uncertainty reasoning over a set of images and their respective captions, in this paper, we rely on appropriate loss functions to learn the alignments in a neural network setting and propose SECLA and SECLA-B. SECLA is a Symmetry-Enhanced Contrastive Learning-based Alignment model that can effectively maximize the similarity scores between corresponding faces and names in a weakly supervised fashion. A variation of the model, SECLA-B, learns to align names and faces as humans do, that is, learning from easy to hard cases to further increase the performance of SECLA. More specifically, SECLA-B applies a two-stage learning framework: (1) Training the model on an easy subset with a few names and faces in each image-caption pair. (2) Leveraging the known pairs of names and faces from the easy cases using a bootstrapping strategy with additional loss to prevent forgetting and learning new alignments at the same time. We achieve state-of-the-art results for both the augmented Labeled Faces in the Wild dataset and the Celebrity Together dataset. In addition, we believe that our methods can be adapted to other multimodal news understanding tasks.