 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLIWhiz: A Non-Intrusive Lyric Intelligibility Prediction System for the Cadenza Challenge
Dec 11, 2025We present LIWhiz, a non-intrusive lyric intelligibility prediction system submitted to the ICASSP 2026 Cadenza Challenge. LIWhiz leverages Whisper for robust feature extraction and a trainable back-end for score prediction. Tested on the Cadenza Lyric Intelligibility Prediction (CLIP) evaluation set, LIWhiz achieves a 22.4% relative root mean squared error reduction over the STOI-based baseline, yielding a substantial improvement in normalized cross-correlation.
What Can an Accent Identifier Learn? Probing Phonetic and Prosodic Information in a Wav2vec2-based Accent Identification Model
Jun 10, 2023


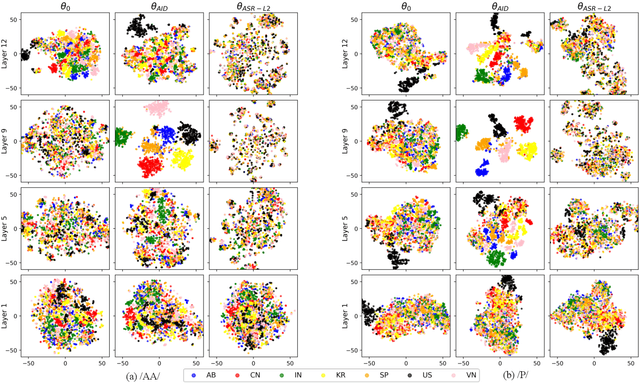
This study is focused on understanding and quantifying the change in phoneme and prosody information encoded in the Self-Supervised Learning (SSL) model, brought by an accent identification (AID) fine-tuning task. This problem is addressed based on model probing. Specifically, we conduct a systematic layer-wise analysis of the representations of the Transformer layers on a phoneme correlation task, and a novel word-level prosody prediction task. We compare the probing performance of the pre-trained and fine-tuned SSL models. Results show that the AID fine-tuning task steers the top 2 layers to learn richer phoneme and prosody representation. These changes share some similarities with the effects of fine-tuning with an Automatic Speech Recognition task. In addition, we observe strong accent-specific phoneme representations in layer 9. To sum up, this study provides insights into the understanding of SSL features and their interactions with fine-tuning tasks.
Filterbank Learning for Small-Footprint Keyword Spotting Robust to Noise
Nov 19, 2022



In the context of keyword spotting (KWS), the replacement of handcrafted speech features by learnable features has not yielded superior KWS performance. In this study, we demonstrate that filterbank learning outperforms handcrafted speech features for KWS whenever the number of filterbank channels is severely decreased. Reducing the number of channels might yield certain KWS performance drop, but also a substantial energy consumption reduction, which is key when deploying common always-on KWS on low-resource devices. Experimental results on a noisy version of the Google Speech Commands Dataset show that filterbank learning adapts to noise characteristics to provide a higher degree of robustness to noise, especially when dropout is integrated. Thus, switching from typically used 40-channel log-Mel features to 8-channel learned features leads to a relative KWS accuracy loss of only 3.5% while simultaneously achieving a 6.3x energy consumption reduction.