 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Can an Accent Identifier Learn? Probing Phonetic and Prosodic Information in a Wav2vec2-based Accent Identification Model
Jun 10, 2023


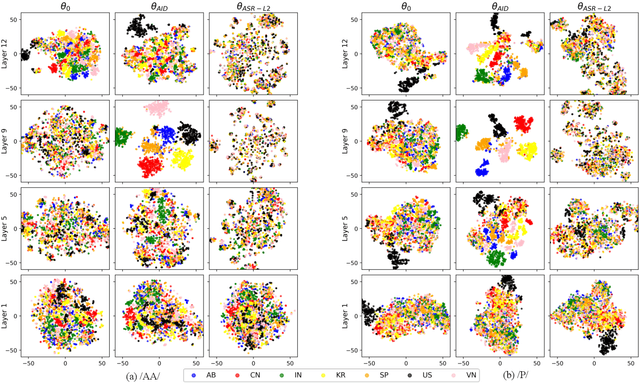
This study is focused on understanding and quantifying the change in phoneme and prosody information encoded in the Self-Supervised Learning (SSL) model, brought by an accent identification (AID) fine-tuning task. This problem is addressed based on model probing. Specifically, we conduct a systematic layer-wise analysis of the representations of the Transformer layers on a phoneme correlation task, and a novel word-level prosody prediction task. We compare the probing performance of the pre-trained and fine-tuned SSL models. Results show that the AID fine-tuning task steers the top 2 layers to learn richer phoneme and prosody representation. These changes share some similarities with the effects of fine-tuning with an Automatic Speech Recognition task. In addition, we observe strong accent-specific phoneme representations in layer 9. To sum up, this study provides insights into the understanding of SSL features and their interactions with fine-tuning tasks.
Improving Mispronunciation Detection with Wav2vec2-based Momentum Pseudo-Labeling for Accentedness and Intelligibility Assessment
Apr 07, 2022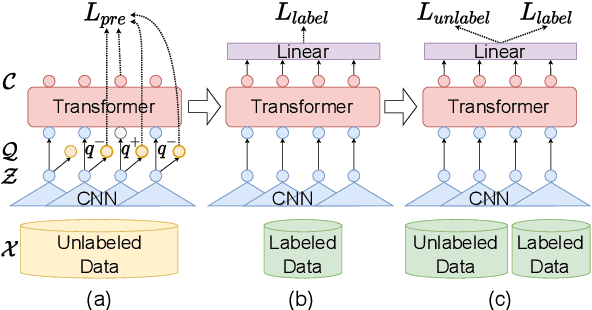
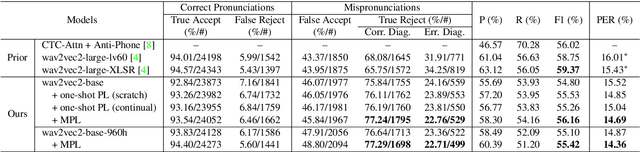
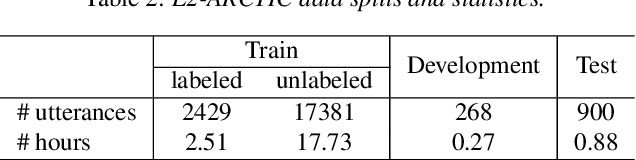
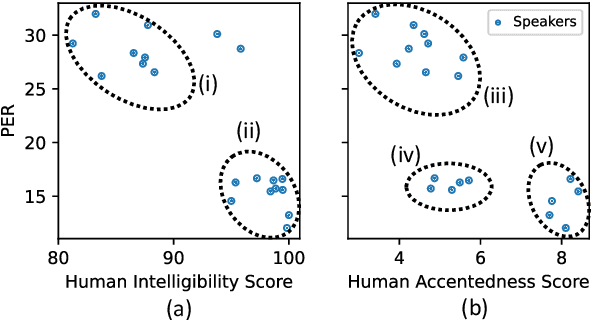
Current leading mispronunciation detection and diagnosis (MDD) systems achieve promising performance via end-to-end phoneme recognition. One challenge of such end-to-end solutions is the scarcity of human-annotated phonemes on natural L2 speech. In this work, we leverage unlabeled L2 speech via a pseudo-labeling (PL) procedure and extend the fine-tuning approach based on pre-trained self-supervised learning (SSL) models. Specifically, we use Wav2vec 2.0 as our SSL model, and fine-tune it using original labeled L2 speech samples plus the created pseudo-labeled L2 speech samples. Our pseudo labels are dynamic and are produced by an ensemble of the online model on-the-fly, which ensures that our model is robust to pseudo label noise. We show that fine-tuning with pseudo labels gains a 5.35% phoneme error rate reduction and 2.48% MDD F1 score improvement over a labeled-samples-only fine-tuning baseline. The proposed PL method is also shown to outperform conventional offline PL methods. Compared to the state-of-the-art MDD systems, our MDD solution achieves a more accurate and consistent phonetic error diagnosis. In addition, we conduct an open test on a separate UTD-4Accents dataset, where our system recognition outputs show a strong correlation with human perception, based on accentedness and intelligibility.