 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Inverse Drum Machine: Source Separation Through Joint Transcription and Analysis-by-Synthesis
May 06, 2025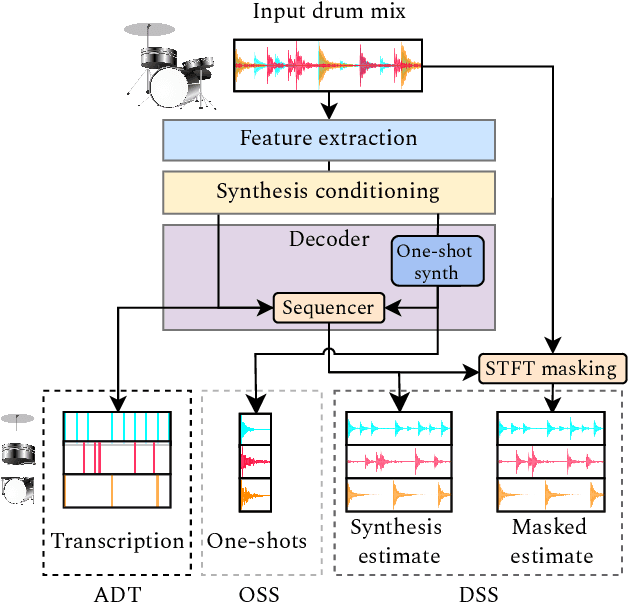



We introduce the Inverse Drum Machine (IDM), a novel approach to drum source separation that combines analysis-by-synthesis with deep learning. Unlike recent supervised methods that rely on isolated stems, IDM requires only transcription annotations. It jointly optimizes automatic drum transcription and one-shot drum sample synthesis in an end-to-end framework. By convolving synthesized one-shot samples with estimated onsets-mimicking a drum machine-IDM reconstructs individual drum stems and trains a neural network to match the original mixture. Evaluations on the StemGMD dataset show that IDM achieves separation performance on par with state-of-the-art supervised methods, while substantially outperforming matrix decomposition baselines.
A fully differentiable model for unsupervised singing voice separation
Jan 30, 2024A novel model was recently proposed by Schulze-Forster et al. in [1] for unsupervised music source separation. This model allows to tackle some of the major shortcomings of existing source separation frameworks. Specifically, it eliminates the need for isolated sources during training, performs efficiently with limited data, and can handle homogeneous sources (such as singing voice). But, this model relies on an external multipitch estimator and incorporates an Ad hoc voice assignment procedure. In this paper, we propose to extend this framework and to build a fully differentiable model by integrating a multipitch estimator and a novel differentiable assignment module within the core model. We show the merits of our approach through a set of experiments, and we highlight in particular its potential for processing diverse and unseen data.
Unsupervised Harmonic Parameter Estimation Using Differentiable DSP and Spectral Optimal Transport
Jan 15, 2024


In neural audio signal processing, pitch conditioning has been used to enhance the performance of synthesizers. However, jointly training pitch estimators and synthesizers is a challenge when using standard audio-to-audio reconstruction loss, leading to reliance on external pitch trackers. To address this issue, we propose using a spectral loss function inspired by optimal transportation theory that minimizes the displacement of spectral energy. We validate this approach through an unsupervised autoencoding task that fits a harmonic template to harmonic signals. We jointly estimate the fundamental frequency and amplitudes of harmonics using a lightweight encoder and reconstruct the signals using a differentiable harmonic synthesizer. The proposed approach offers a promising direction for improving unsupervised parameter estimation in neural audio applications.
* Accepted in ICASSP 2024
Singer Identity Representation Learning using Self-Supervised Techniques
Jan 10, 2024Significant strides have been made in creating voice identity representations using speech data. However, the same level of progress has not been achieved for singing voices. To bridge this gap, we suggest a framework for training singer identity encoders to extract representations suitable for various singing-related tasks, such as singing voice similarity and synthesis. We explore different self-supervised learning techniques on a large collection of isolated vocal tracks and apply data augmentations during training to ensure that the representations are invariant to pitch and content variations. We evaluate the quality of the resulting representations on singer similarity and identification tasks across multiple datasets, with a particular emphasis on out-of-domain generalization. Our proposed framework produces high-quality embeddings that outperform both speaker verification and wav2vec 2.0 pre-trained baselines on singing voice while operating at 44.1 kHz. We release our code and trained models to facilitate further research on singing voice and related areas.
* Accepted at the ISMIR conference, Milan, Italy, 2023