 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDNN-Free Low-Latency Adaptive Speech Enhancement Based on Frame-Online Beamforming Powered by Block-Online FastMNMF
Paper and Code
Jul 22, 2022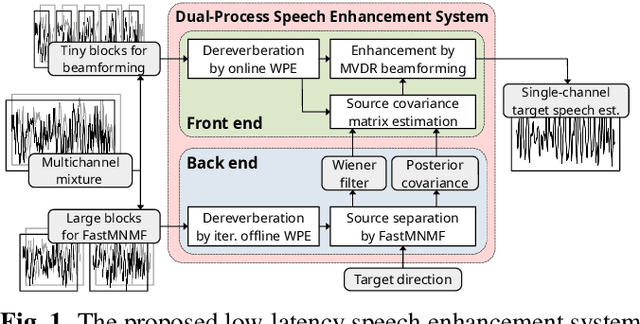
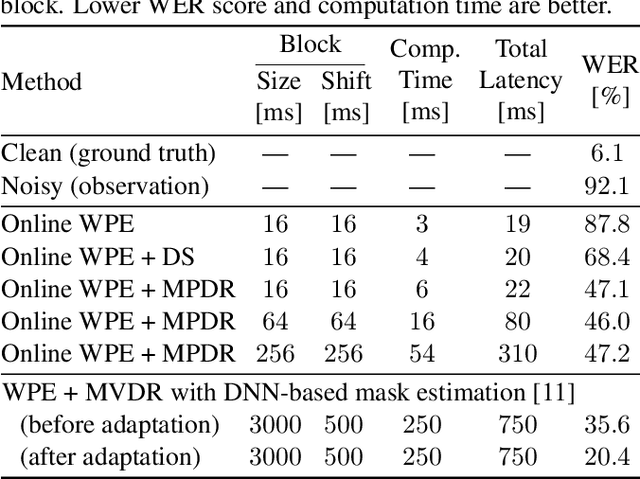

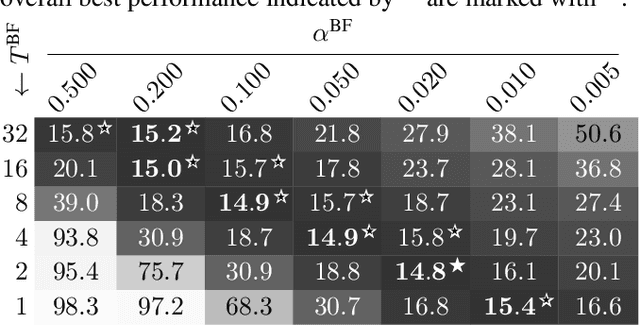
This paper describes a practical dual-process speech enhancement system that adapts environment-sensitive frame-online beamforming (front-end) with help from environment-free block-online source separation (back-end). To use minimum variance distortionless response (MVDR) beamforming, one may train a deep neural network (DNN) that estimates time-frequency masks used for computing the covariance matrices of sources (speech and noise). Backpropagation-based run-time adaptation of the DNN was proposed for dealing with the mismatched training-test conditions. Instead, one may try to directly estimate the source covariance matrices with a state-of-the-art blind source separation method called fast multichannel non-negative matrix factorization (FastMNMF). In practice, however, neither the DNN nor the FastMNMF can be updated in a frame-online manner due to its computationally-expensive iterative nature. Our DNN-free system leverages the posteriors of the latest source spectrograms given by block-online FastMNMF to derive the current source covariance matrices for frame-online beamforming. The evaluation shows that our frame-online system can quickly respond to scene changes caused by interfering speaker movements and outperformed an existing block-online system with DNN-based beamforming by 5.0 points in terms of the word error rate.