 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline speaker diarization of meetings guided by speech separation
Paper and Code
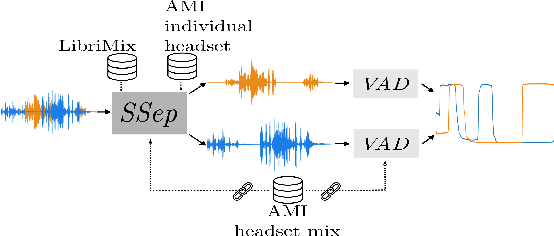
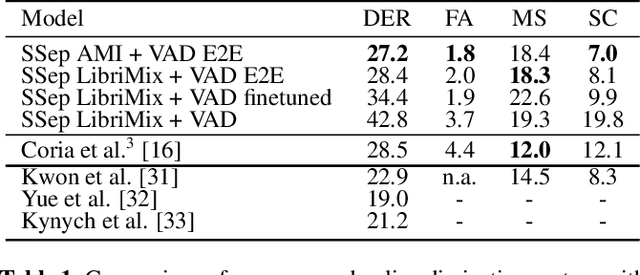
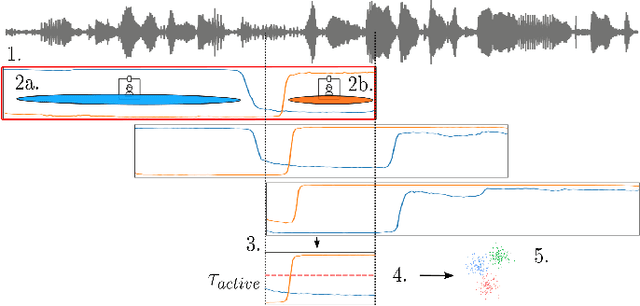
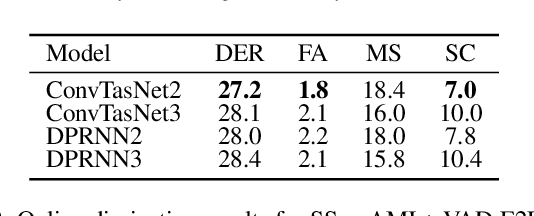
Overlapped speech is notoriously problematic for speaker diarization systems. Consequently, the use of speech separation has recently been proposed to improve their performance. Although promising, speech separation models struggle with realistic data because they are trained on simulated mixtures with a fixed number of speakers. In this work, we introduce a new speech separation-guided diarization scheme suitable for the online speaker diarization of long meeting recordings with a variable number of speakers, as present in the AMI corpus. We envisage ConvTasNet and DPRNN as alternatives for the separation networks, with two or three output sources. To obtain the speaker diarization result, voice activity detection is applied on each estimated source. The final model is fine-tuned end-to-end, after first adapting the separation to real data using AMI. The system operates on short segments, and inference is performed by stitching the local predictions using speaker embeddings and incremental clustering. The results show that our system improves the state-of-the-art on the AMI headset mix, using no oracle information and under full evaluation (no collar and including overlapped speech). Finally, we show the strength of our system particularly on overlapped speech sections.