 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePansharpening of PRISMA products for archaeological prospection
Apr 08, 2024



Hyperspectral data recorded from satellite platforms are often ill-suited for geo-archaeological prospection due to low spatial resolution. The established potential of hyperspectral data from airborne sensors in identifying archaeological features has, on the other side, generated increased interest in enhancing hyperspectral data to achieve higher spatial resolution. This improvement is crucial for detecting traces linked to sub-surface geo-archaeological features and can make satellite hyperspectral acquisitions more suitable for archaeological research. This research assesses the usability of pansharpened PRISMA satellite products in geo-archaeological prospections. Three pan-sharpening methods (GSA, MTF-GLP and HySure) are compared quantitatively and qualitatively and tested over the archaeological landscape of Aquileia (Italy). The results suggest that the application of pansharpening techniques makes hyperspectral satellite imagery highly suitable, under certain conditions, to the identification of sub-surface archaeological features of small and large size.
Impact of LiDAR visualisations on semantic segmentation of archaeological objects
Apr 08, 2024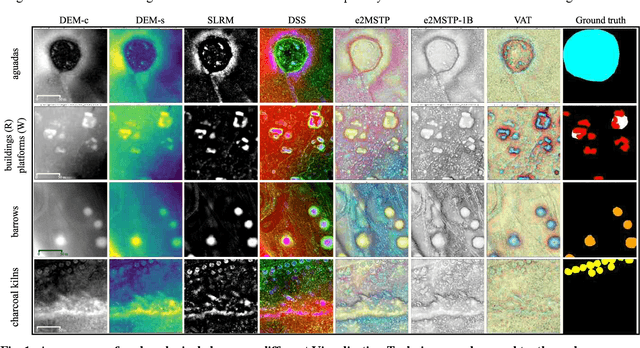

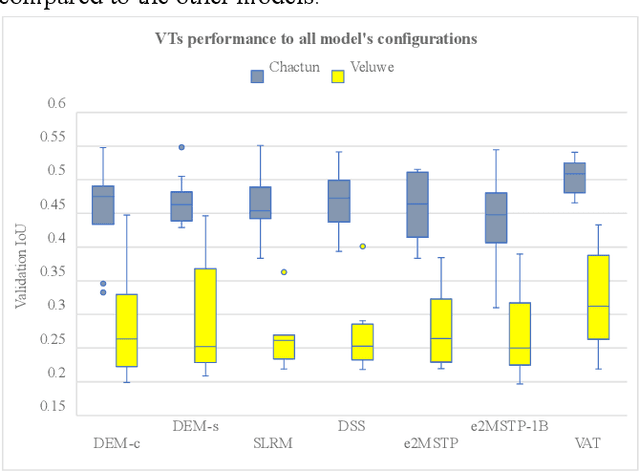
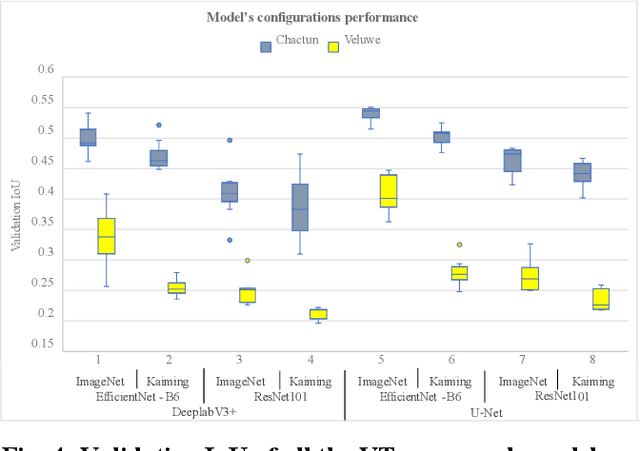
Deep learning methods in LiDAR-based archaeological research often leverage visualisation techniques derived from Digital Elevation Models to enhance characteristics of archaeological objects present in the images. This paper investigates the impact of visualisations on deep learning performance through a comprehensive testing framework. The study involves the use of eight semantic segmentation models to evaluate seven diverse visualisations across two study areas, encompassing five archaeological classes. Experimental results reveal that the choice of appropriate visualisations can influence performance by up to 8%. Yet, pinpointing one visualisation that outperforms the others in segmenting all archaeological classes proves challenging. The observed performance variation, reaching up to 25% across different model configurations, underscores the importance of thoughtfully selecting model configurations and LiDAR visualisations for successfully segmenting archaeological objects.
Implicit neural representation for change detection
Jul 28, 2023



Detecting changes that occurred in a pair of 3D airborne LiDAR point clouds, acquired at two different times over the same geographical area, is a challenging task because of unmatching spatial supports and acquisition system noise. Most recent attempts to detect changes on point clouds are based on supervised methods, which require large labelled data unavailable in real-world applications. To address these issues, we propose an unsupervised approach that comprises two components: Neural Field (NF) for continuous shape reconstruction and a Gaussian Mixture Model for categorising changes. NF offer a grid-agnostic representation to encode bi-temporal point clouds with unmatched spatial support that can be regularised to increase high-frequency details and reduce noise. The reconstructions at each timestamp are compared at arbitrary spatial scales, leading to a significant increase in detection capabilities. We apply our method to a benchmark dataset of simulated LiDAR point clouds for urban sprawling. The dataset offers different challenging scenarios with different resolutions, input modalities and noise levels, allowing a multi-scenario comparison of our method with the current state-of-the-art. We boast the previous methods on this dataset by a 10% margin in intersection over union metric. In addition, we apply our methods to a real-world scenario to identify illegal excavation (looting) of archaeological sites and confirm that they match findings from field experts.
Tranfer Learning of Semantic Segmentation Methods for Identifying Buried Archaeological Structures on LiDAR Data
Jul 20, 2023
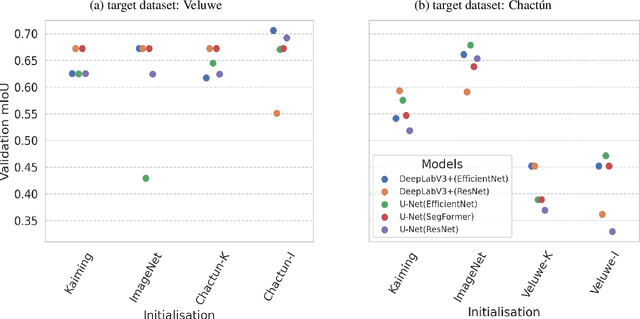
When applying deep learning to remote sensing data in archaeological research, a notable obstacle is the limited availability of suitable datasets for training models. The application of transfer learning is frequently employed to mitigate this drawback. However, there is still a need to explore its effectiveness when applied across different archaeological datasets. This paper compares the performance of various transfer learning configurations using two semantic segmentation deep neural networks on two LiDAR datasets. The experimental results indicate that transfer learning-based approaches in archaeology can lead to performance improvements, although a systematic enhancement has not yet been observed. We provide specific insights about the validity of such techniques that can serve as a baseline for future works.
Optimal Transport for Change Detection on LiDAR Point Clouds
Feb 14, 2023


The detection of changes occurring in multi-temporal remote sensing data plays a crucial role in monitoring several aspects of real life, such as disasters, deforestation, and urban planning. In the latter context, identifying both newly built and demolished buildings is essential to help landscape and city managers to promote sustainable development. While the use of airborne LiDAR point clouds has become widespread in urban change detection, the most common approaches require the transformation of a point cloud into a regular grid of interpolated height measurements, i.e. Digital Elevation Model (DEM). However, the DEM's interpolation step causes an information loss related to the height of the objects, affecting the detection capability of building changes, where the high resolution of LiDAR point clouds in the third dimension would be the most beneficial. Notwithstanding recent attempts to detect changes directly on point clouds using either a distance-based computation method or a semantic segmentation pre-processing step, only the M3C2 distance computation-based approach can identify both positive and negative changes, which is of paramount importance in urban planning. Motivated by the previous arguments, we introduce a principled change detection pipeline, based on optimal transport, capable of distinguishing between newly built buildings (positive changes) and demolished ones (negative changes). In this work, we propose to use unbalanced optimal transport to cope with the creation and destruction of mass related to building changes occurring in a bi-temporal pair of LiDAR point clouds. We demonstrate the efficacy of our approach on the only publicly available airborne LiDAR dataset for change detection by showing superior performance over the M3C2 and the previous optimal transport-based method presented by Nicolas Courty et al.at IGARSS 2016.
Regular Partitions and Their Use in Structural Pattern Recognition
Sep 16, 2019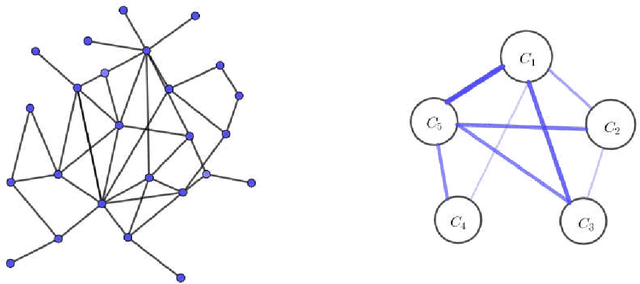
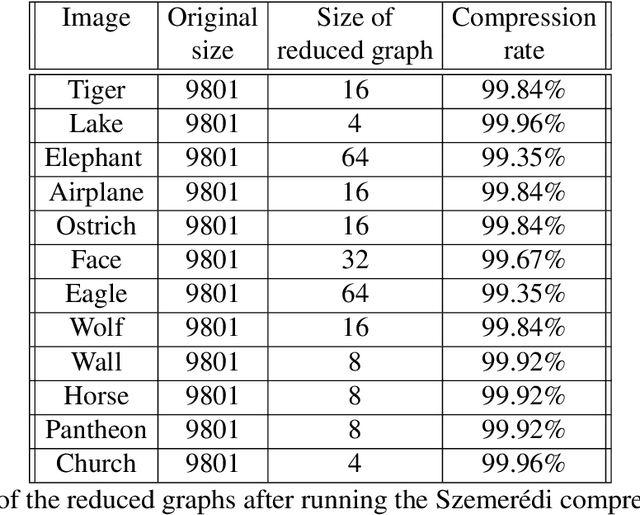
Recent years are characterized by an unprecedented quantity of available network data which are produced at an astonishing rate by an heterogeneous variety of interconnected sensors and devices. This high-throughput generation calls for the development of new effective methods to store, retrieve, understand and process massive network data. In this thesis, we tackle this challenge by introducing a framework to summarize large graphs based on Szemer\'edi's Regularity Remma (RL), which roughly states that any sufficiently large graph can almost entirely be partitioned into a bounded number of random-like bipartite graphs. The partition resulting from the RL gives rise to a summary, which inherits many of the essential structural properties of the original graph. We first extend an heuristic version of the RL to improve its efficiency and its robustness. We use the proposed algorithm to address graph-based clustering and image segmentation tasks. In the second part of the thesis, we introduce a new heuristic algorithm which is characterized by an improvement of the summary quality both in terms of reconstruction error and of noise filtering. We use the proposed heuristic to address the graph search problem defined under a similarity measure. Finally, we study the linkage among the regularity lemma, the stochastic block model and the minimum description length. This study provide us a principled way to develop a graph decomposition algorithm based on stochastic block model which is fitted using likelihood maximization.
On the Interplay between Strong Regularity and Graph Densification
Mar 21, 2017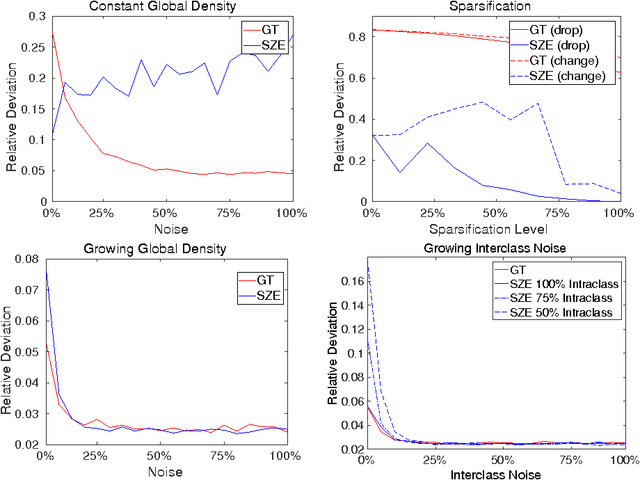
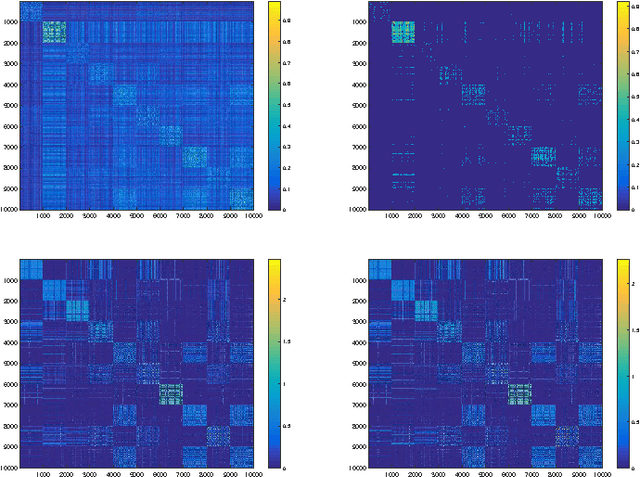
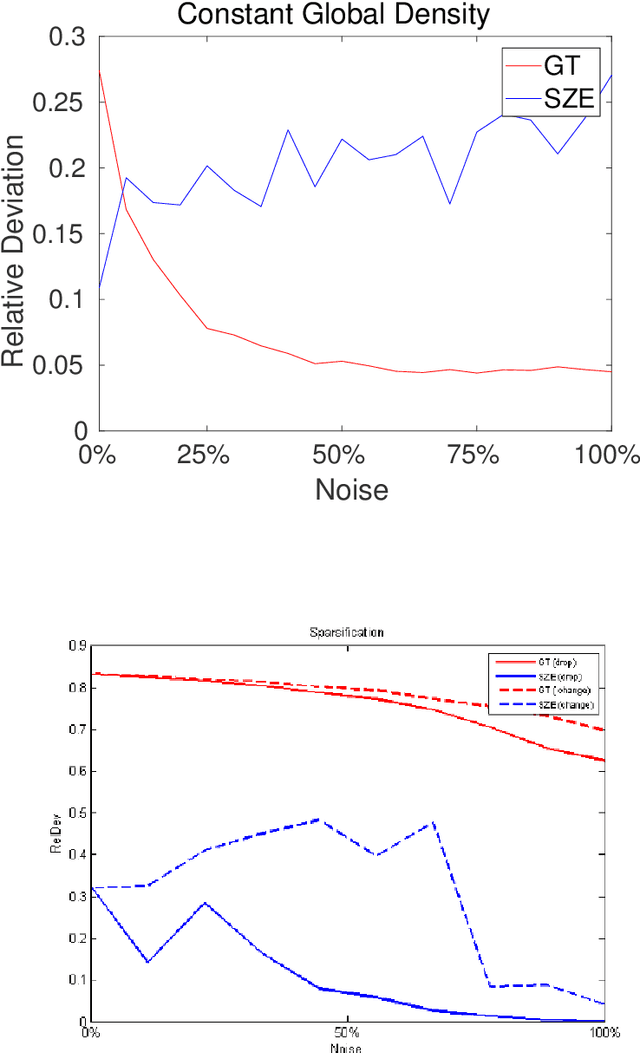
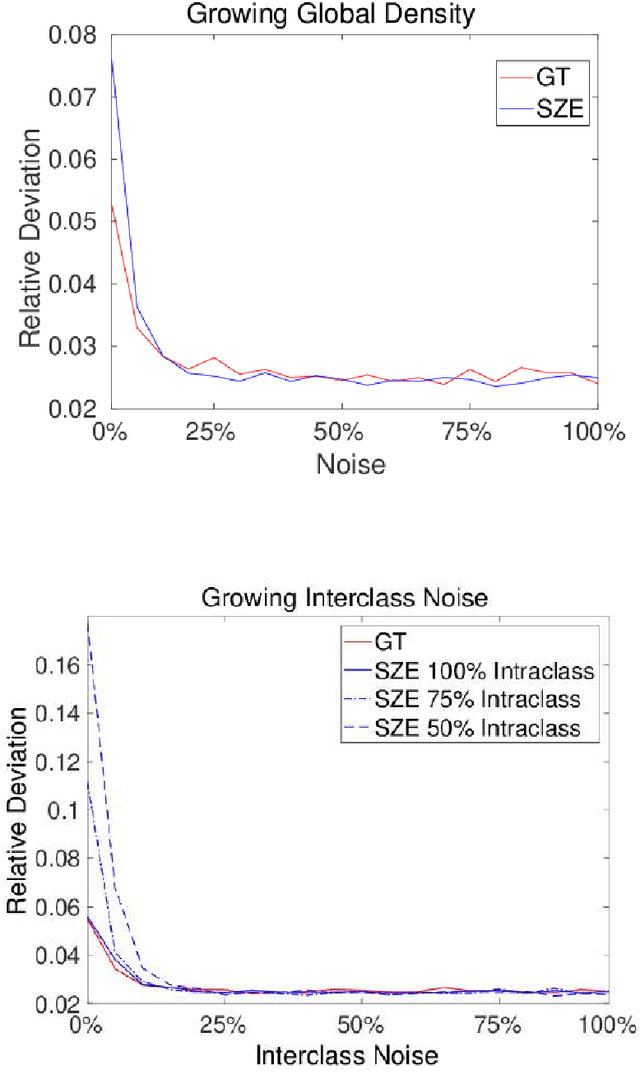
In this paper we analyze the practical implications of Szemer\'edi's regularity lemma in the preservation of metric information contained in large graphs. To this end, we present a heuristic algorithm to find regular partitions. Our experiments show that this method is quite robust to the natural sparsification of proximity graphs. In addition, this robustness can be enforced by graph densification.
Revealing Structure in Large Graphs: Szemerédi's Regularity Lemma and its Use in Pattern Recognition
Sep 21, 2016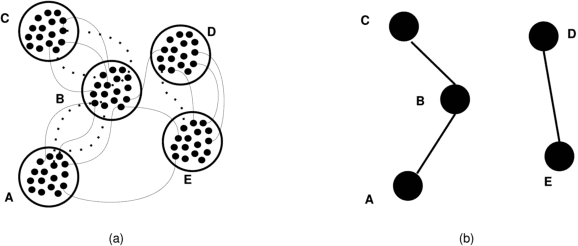
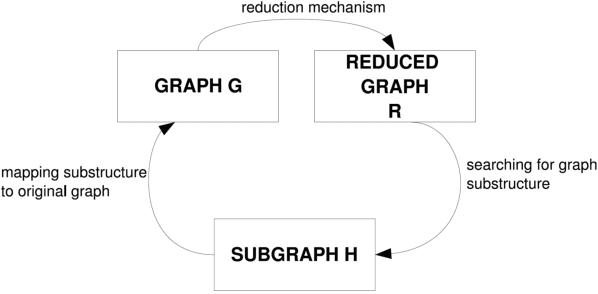
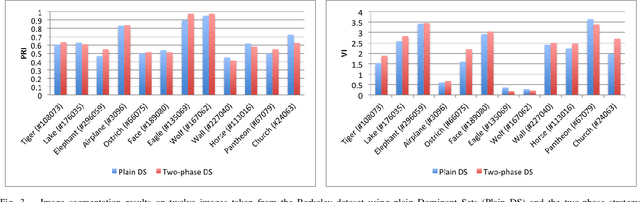
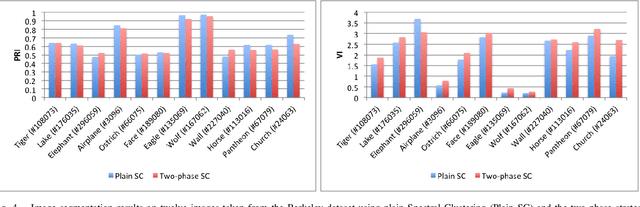
Introduced in the mid-1970's as an intermediate step in proving a long-standing conjecture on arithmetic progressions, Szemer\'edi's regularity lemma has emerged over time as a fundamental tool in different branches of graph theory, combinatorics and theoretical computer science. Roughly, it states that every graph can be approximated by the union of a small number of random-like bipartite graphs called regular pairs. In other words, the result provides us a way to obtain a good description of a large graph using a small amount of data, and can be regarded as a manifestation of the all-pervading dichotomy between structure and randomness. In this paper we will provide an overview of the regularity lemma and its algorithmic aspects, and will discuss its relevance in the context of pattern recognition research.