 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegular Partitions and Their Use in Structural Pattern Recognition
Paper and Code
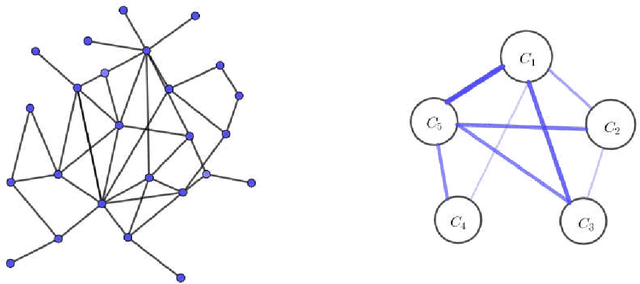
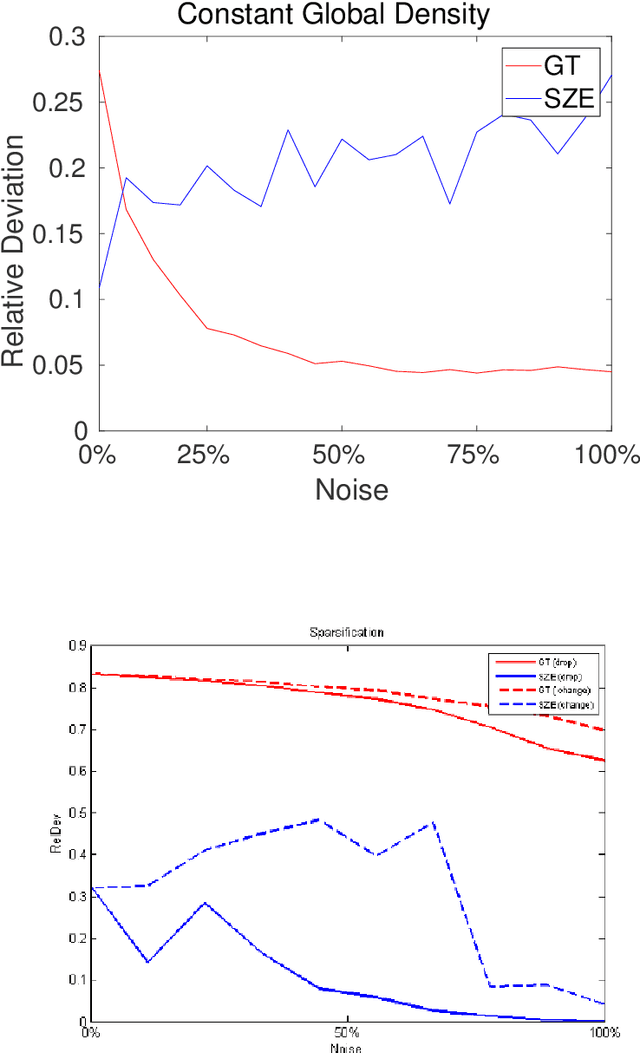
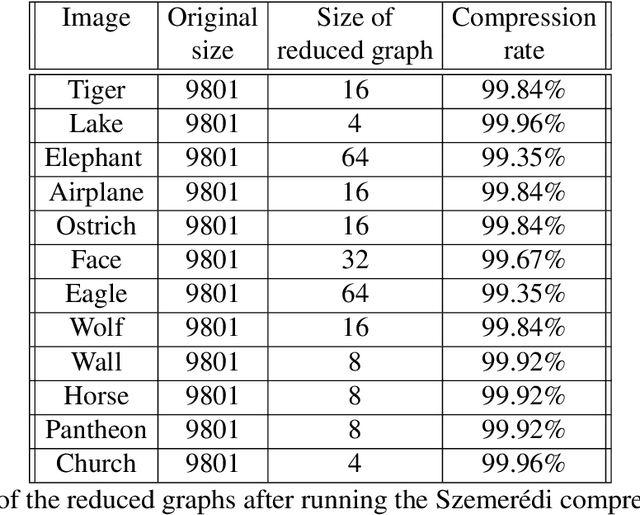
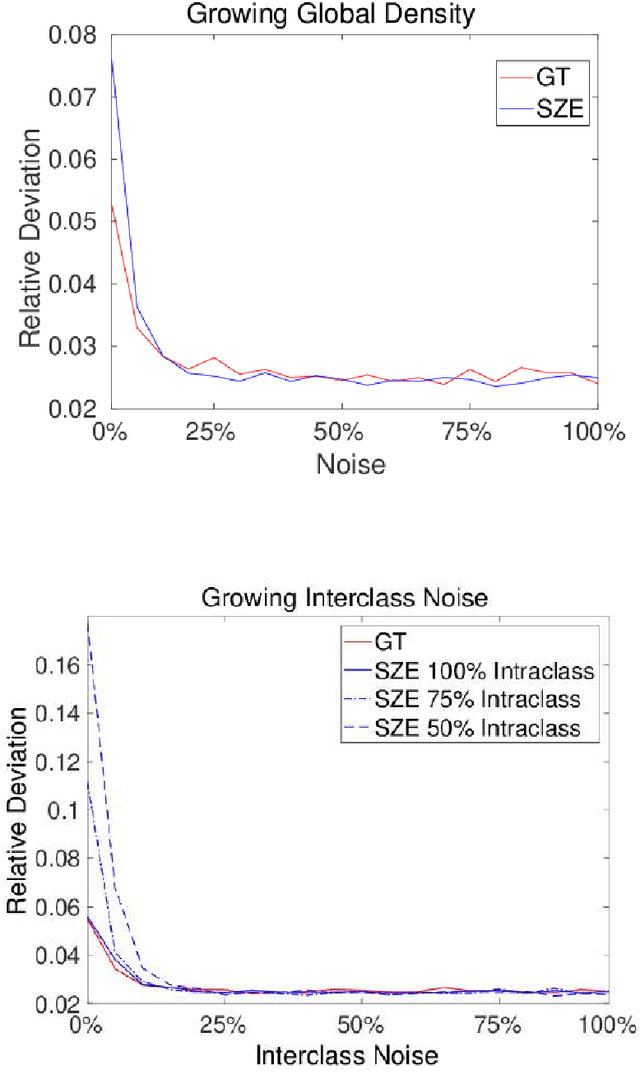
Recent years are characterized by an unprecedented quantity of available network data which are produced at an astonishing rate by an heterogeneous variety of interconnected sensors and devices. This high-throughput generation calls for the development of new effective methods to store, retrieve, understand and process massive network data. In this thesis, we tackle this challenge by introducing a framework to summarize large graphs based on Szemer\'edi's Regularity Remma (RL), which roughly states that any sufficiently large graph can almost entirely be partitioned into a bounded number of random-like bipartite graphs. The partition resulting from the RL gives rise to a summary, which inherits many of the essential structural properties of the original graph. We first extend an heuristic version of the RL to improve its efficiency and its robustness. We use the proposed algorithm to address graph-based clustering and image segmentation tasks. In the second part of the thesis, we introduce a new heuristic algorithm which is characterized by an improvement of the summary quality both in terms of reconstruction error and of noise filtering. We use the proposed heuristic to address the graph search problem defined under a similarity measure. Finally, we study the linkage among the regularity lemma, the stochastic block model and the minimum description length. This study provide us a principled way to develop a graph decomposition algorithm based on stochastic block model which is fitted using likelihood maximization.