 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Structure-Aware Drum Transcription Based on Self-Attention Mechanisms
Paper and Code
May 12, 2021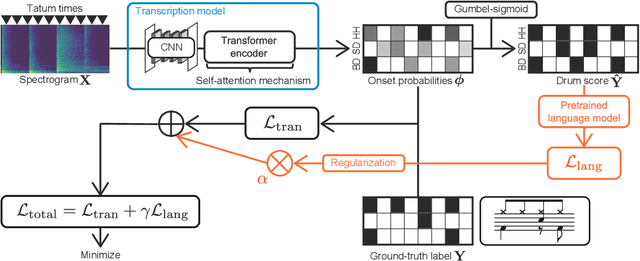
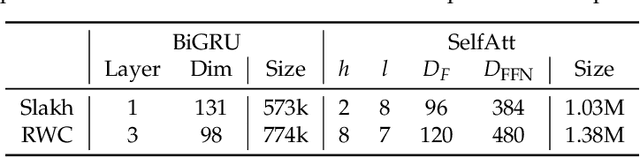
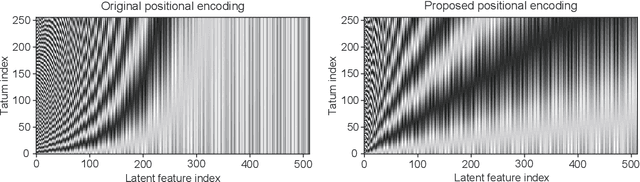
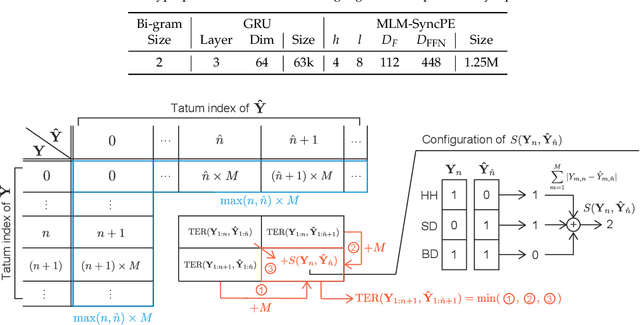
This paper describes an automatic drum transcription (ADT) method that directly estimates a tatum-level drum score from a music signal, in contrast to most conventional ADT methods that estimate the frame-level onset probabilities of drums. To estimate a tatum-level score, we propose a deep transcription model that consists of a frame-level encoder for extracting the latent features from a music signal and a tatum-level decoder for estimating a drum score from the latent features pooled at the tatum level. To capture the global repetitive structure of drum scores, which is difficult to learn with a recurrent neural network (RNN), we introduce a self-attention mechanism with tatum-synchronous positional encoding into the decoder. To mitigate the difficulty of training the self-attention-based model from an insufficient amount of paired data and improve the musical naturalness of the estimated scores, we propose a regularized training method that uses a global structure-aware masked language (score) model with a self-attention mechanism pretrained from an extensive collection of drum scores. Experimental results showed that the proposed regularized model outperformed the conventional RNN-based model in terms of the tatum-level error rate and the frame-level F-measure, even when only a limited amount of paired data was available so that the non-regularized model underperformed the RNN-based model.