 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTatum-Level Drum Transcription Based on a Convolutional Recurrent Neural Network with Language Model-Based Regularized Training
Oct 08, 2020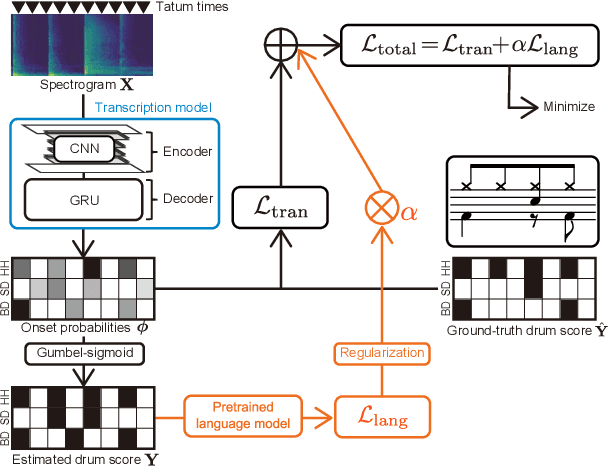



This paper describes a neural drum transcription method that detects from music signals the onset times of drums at the $\textit{tatum}$ level, where tatum times are assumed to be estimated in advance. In conventional studies on drum transcription, deep neural networks (DNNs) have often been used to take a music spectrogram as input and estimate the onset times of drums at the $\textit{frame}$ level. The major problem with such frame-to-frame DNNs, however, is that the estimated onset times do not often conform with the typical tatum-level patterns appearing in symbolic drum scores because the long-term musically meaningful structures of those patterns are difficult to learn at the frame level. To solve this problem, we propose a regularized training method for a frame-to-tatum DNN. In the proposed method, a tatum-level probabilistic language model (gated recurrent unit (GRU) network or repetition-aware bi-gram model) is trained from an extensive collection of drum scores. Given that the musical naturalness of tatum-level onset times can be evaluated by the language model, the frame-to-tatum DNN is trained with a regularizer based on the pretrained language model. The experimental results demonstrate the effectiveness of the proposed regularized training method.
Semi-supervised Neural Chord Estimation Based on a Variational Autoencoder with Discrete Labels and Continuous Textures of Chords
May 14, 2020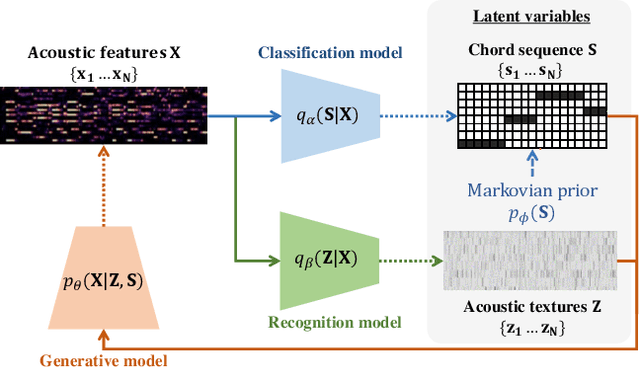
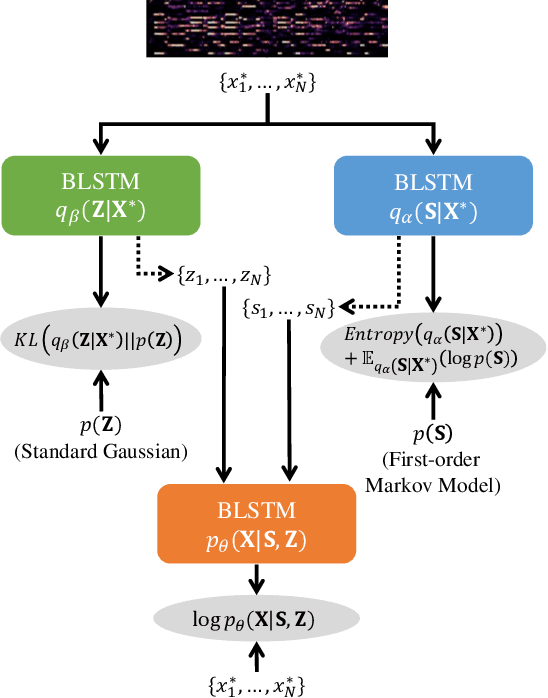

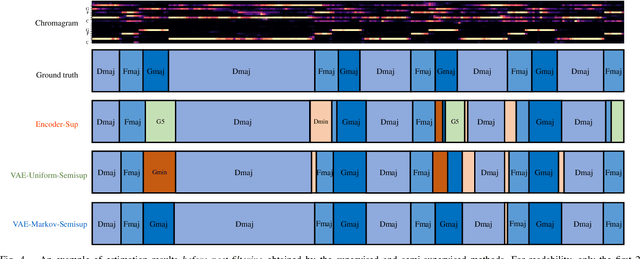
This paper describes a statistically-principled semi-supervised method of automatic chord estimation (ACE) that can make effective use of any music signals regardless of the availability of chord annotations. The typical approach to ACE is to train a deep classification model (neural chord estimator) in a supervised manner by using only a limited amount of annotated music signals. In this discriminative approach, prior knowledge about chord label sequences (characteristics of model output) has scarcely been taken into account. In contract, we propose a unified generative and discriminative approach in the framework of amortized variational inference. More specifically, we formulate a deep generative model that represents the complex generative process of chroma vectors (observed variables) from the discrete labels and continuous textures of chords (latent variables). Chord labels and textures are assumed to follow a Markov model favoring self-transitions and a standard Gaussian distribution, respectively. Given chroma vectors as observed data, the posterior distributions of latent chord labels and textures are computed approximately by using deep classification and recognition models, respectively. These three models are combined to form a variational autoencoder and trained jointly in a semi-supervised manner. The experimental results show that the performance of the classification model can be improved by additionally using non-annotated music signals and/or by regularizing the classification model with the Markov model of chord labels and the generative model of chroma vectors even in the fully-supervised condition.
Multi-Step Chord Sequence Prediction Based on Aggregated Multi-Scale Encoder-Decoder Network
Nov 12, 2019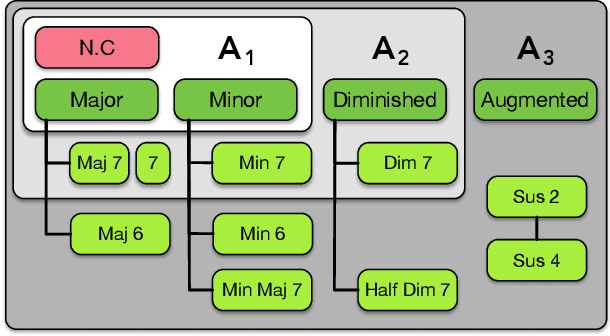
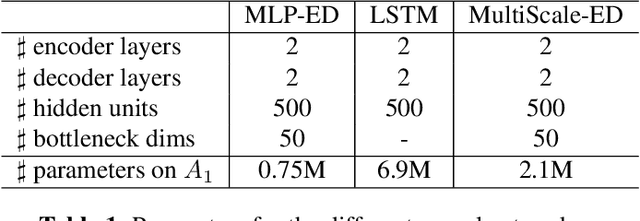
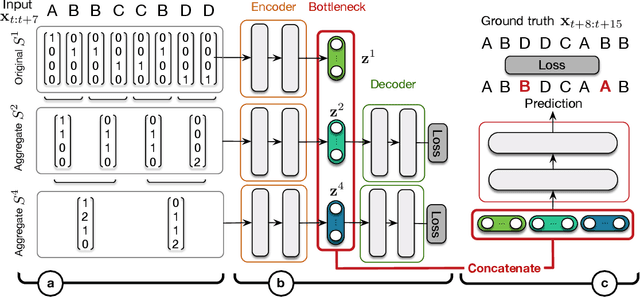
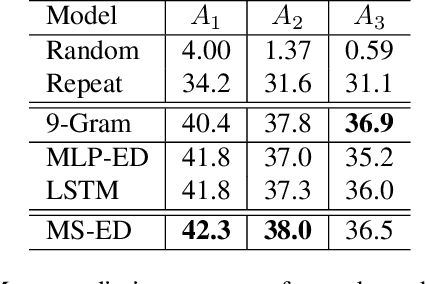
This paper studies the prediction of chord progressions for jazz music by relying on machine learning models. The motivation of our study comes from the recent success of neural networks for performing automatic music composition. Although high accuracies are obtained in single-step prediction scenarios, most models fail to generate accurate multi-step chord predictions. In this paper, we postulate that this comes from the multi-scale structure of musical information and propose new architectures based on an iterative temporal aggregation of input labels. Specifically, the input and ground truth labels are merged into increasingly large temporal bags, on which we train a family of encoder-decoder networks for each temporal scale. In a second step, we use these pre-trained encoder bottleneck features at each scale in order to train a final encoder-decoder network. Furthermore, we rely on different reductions of the initial chord alphabet into three adapted chord alphabets. We perform evaluations against several state-of-the-art models and show that our multi-scale architecture outperforms existing methods in terms of accuracy and perplexity, while requiring relatively few parameters. We analyze musical properties of the results, showing the influence of downbeat position within the analysis window on accuracy, and evaluate errors using a musically-informed distance metric.
Music Transcription Based on Bayesian Piece-Specific Score Models Capturing Repetitions
Aug 18, 2019

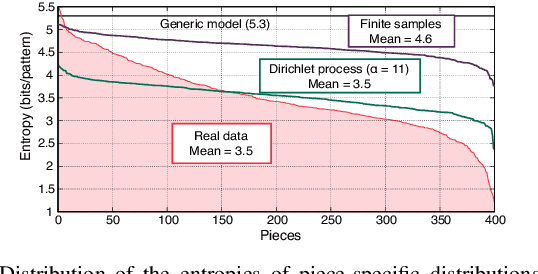
Most work on models for music transcription has focused on describing local sequential dependence of notes in musical scores and failed to capture their global repetitive structure, which can be a useful guide for transcribing music. Focusing on the rhythm, we formulate several classes of Bayesian Markov models of musical scores that describe repetitions indirectly by sparse transition probabilities of notes or note patterns. This enables us to construct piece-specific models for unseen scores with unfixed repetitive structure and to derive tractable inference algorithms. Moreover, to describe approximate repetitions, we explicitly incorporate a process of modifying the repeated notes/note patterns. We apply these models as a prior music language model for rhythm transcription, where piece-specific score models are inferred from performed MIDI data by unsupervised learning, in contrast to the conventional supervised construction of score models. Evaluations using vocal melodies of popular music showed that the Bayesian models improved the transcription accuracy for most of the tested model types, indicating the universal efficacy of the proposed approach.
Statistical Learning and Estimation of Piano Fingering
Apr 23, 2019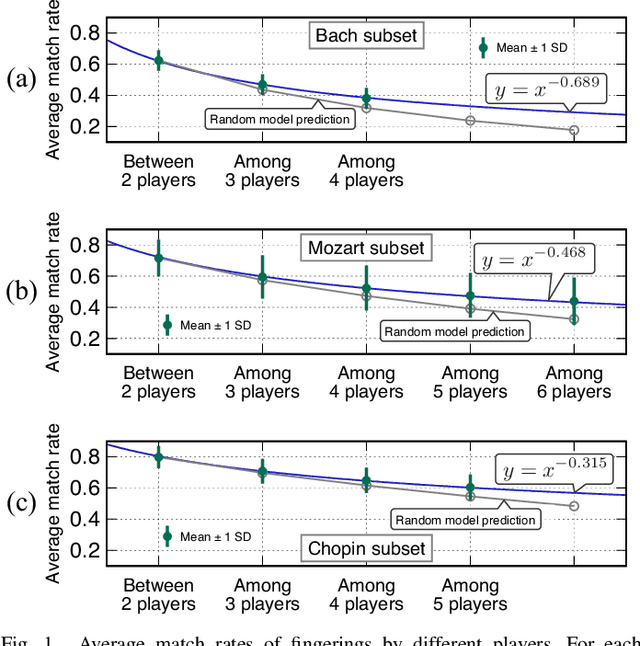
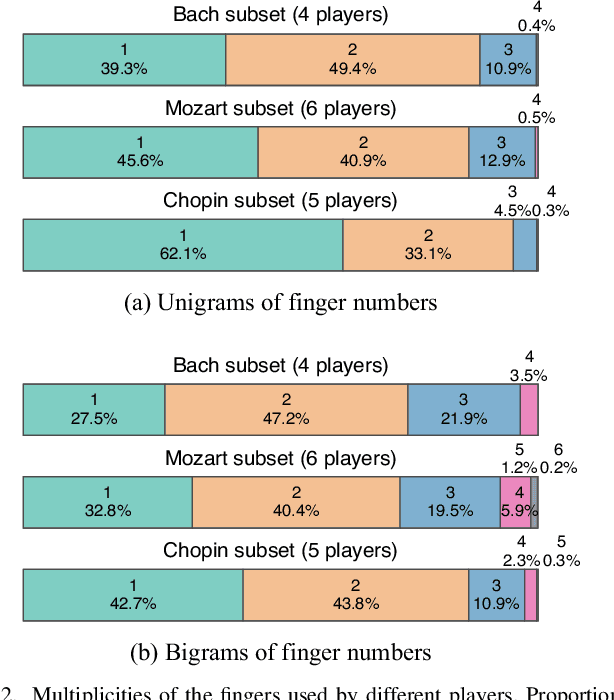
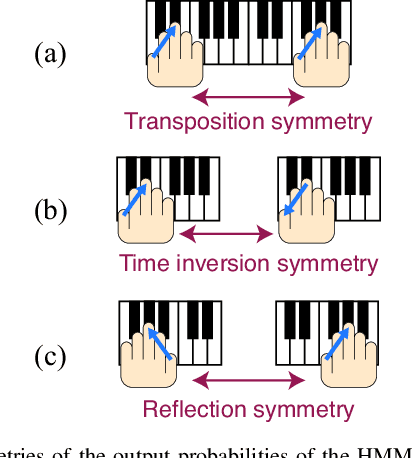
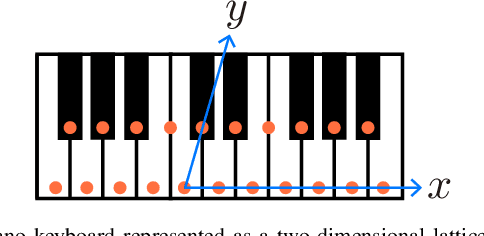
Automatic estimation of piano fingering is important for computationally understanding the process of music performance and applicable to performance assistance and education systems. While a natural way to formulate the quality of fingerings is to construct models of the constraints/costs of performance, it is generally difficult to find appropriate parameter values for these models. Here we study an alternative data-driven approach based on statistical modeling in which the naturalness of a given fingering is described by probabilities. Specifically, we construct two types of hidden Markov models (HMMs) and their higher-order extensions. We also study deep neural network (DNN)-based methods for comparison. Using a newly released dataset of fingering annotations, we conduct systematic evaluations of these models as well as a representative constraint-based method and find that the methods based on high-order HMMs outperform others in terms of estimation accuracies. We also quantitatively study individual difference of fingering and propose evaluation measures that can be used with multiple ground truth data. We conclude that the HMM-based methods are currently state of the art and generate acceptable fingerings in most parts and that they have certain limitations such as ignorance of phrase boundaries and interdependence of the two hands.
Statistical Piano Reduction Controlling Performance Difficulty
Oct 25, 2018

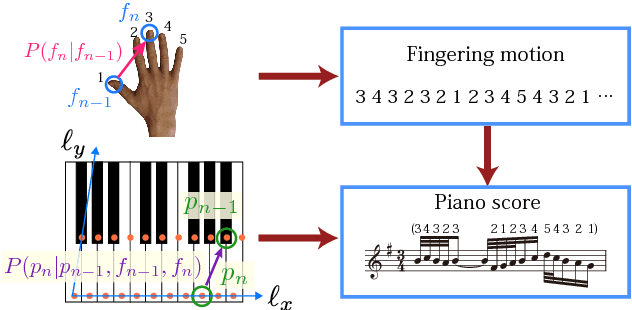
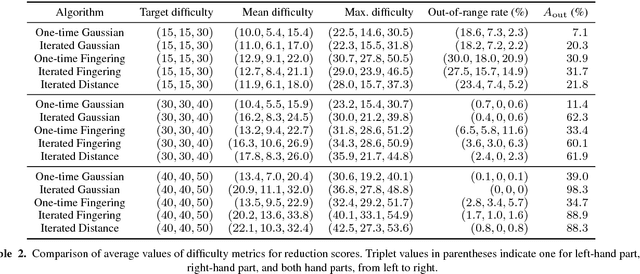
We present a statistical-modelling method for piano reduction, i.e. converting an ensemble score into piano scores, that can control performance difficulty. While previous studies have focused on describing the condition for playable piano scores, it depends on player's skill and can change continuously with the tempo. We thus computationally quantify performance difficulty as well as musical fidelity to the original score, and formulate the problem as optimization of musical fidelity under constraints on difficulty values. First, performance difficulty measures are developed by means of probabilistic generative models for piano scores and the relation to the rate of performance errors is studied. Second, to describe musical fidelity, we construct a probabilistic model integrating a prior piano-score model and a model representing how ensemble scores are likely to be edited. An iterative optimization algorithm for piano reduction is developed based on statistical inference of the model. We confirm the effect of the iterative procedure; we find that subjective difficulty and musical fidelity monotonically increase with controlled difficulty values; and we show that incorporating sequential dependence of pitches and fingering motion in the piano-score model improves the quality of reduction scores in high-difficulty cases.
Generative Statistical Models with Self-Emergent Grammar of Chord Sequences
Mar 02, 2018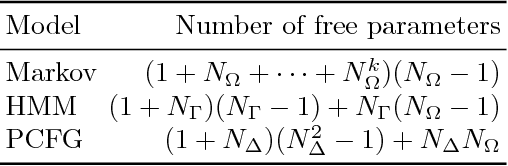
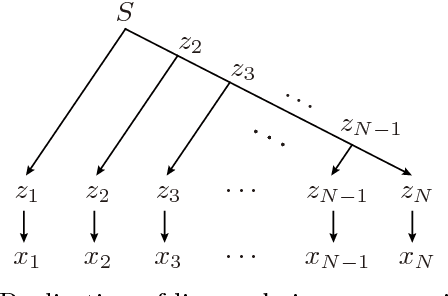

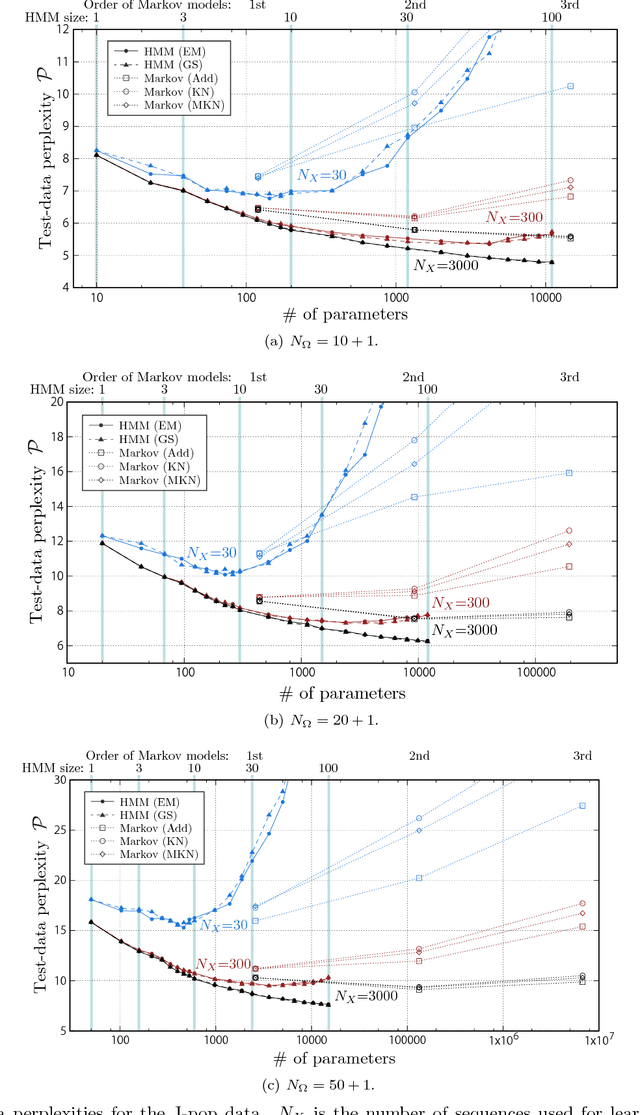
Generative statistical models of chord sequences play crucial roles in music processing. To capture syntactic similarities among certain chords (e.g. in C major key, between G and G7 and between F and Dm), we study hidden Markov models and probabilistic context-free grammar models with latent variables describing syntactic categories of chord symbols and their unsupervised learning techniques for inducing the latent grammar from data. Surprisingly, we find that these models often outperform conventional Markov models in predictive power, and the self-emergent categories often correspond to traditional harmonic functions. This implies the need for chord categories in harmony models from the informatics perspective.
Note Value Recognition for Piano Transcription Using Markov Random Fields
Jul 07, 2017



This paper presents a statistical method for use in music transcription that can estimate score times of note onsets and offsets from polyphonic MIDI performance signals. Because performed note durations can deviate largely from score-indicated values, previous methods had the problem of not being able to accurately estimate offset score times (or note values) and thus could only output incomplete musical scores. Based on observations that the pitch context and onset score times are influential on the configuration of note values, we construct a context-tree model that provides prior distributions of note values using these features and combine it with a performance model in the framework of Markov random fields. Evaluation results show that our method reduces the average error rate by around 40 percent compared to existing/simple methods. We also confirmed that, in our model, the score model plays a more important role than the performance model, and it automatically captures the voice structure by unsupervised learning.
Rhythm Transcription of Polyphonic Piano Music Based on Merged-Output HMM for Multiple Voices
Jan 29, 2017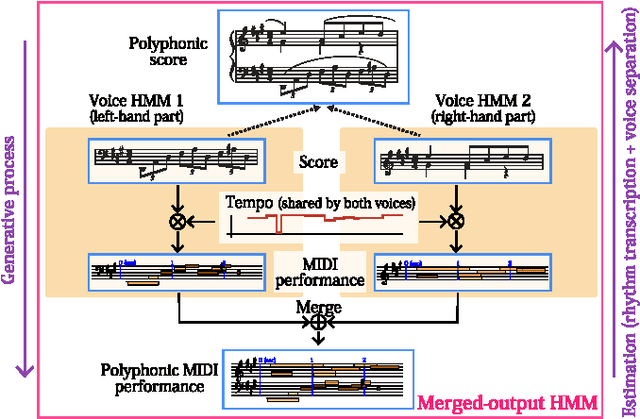


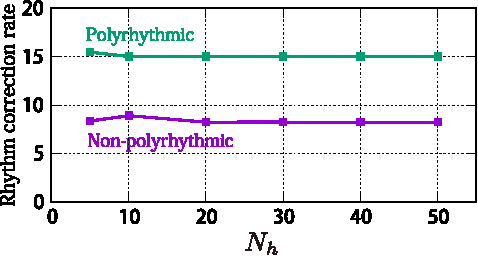
In a recent conference paper, we have reported a rhythm transcription method based on a merged-output hidden Markov model (HMM) that explicitly describes the multiple-voice structure of polyphonic music. This model solves a major problem of conventional methods that could not properly describe the nature of multiple voices as in polyrhythmic scores or in the phenomenon of loose synchrony between voices. In this paper we present a complete description of the proposed model and develop an inference technique, which is valid for any merged-output HMMs for which output probabilities depend on past events. We also examine the influence of the architecture and parameters of the method in terms of accuracies of rhythm transcription and voice separation and perform comparative evaluations with six other algorithms. Using MIDI recordings of classical piano pieces, we found that the proposed model outperformed other methods by more than 12 points in the accuracy for polyrhythmic performances and performed almost as good as the best one for non-polyrhythmic performances. This reveals the state-of-the-art methods of rhythm transcription for the first time in the literature. Publicly available source codes are also provided for future comparisons.
A Stochastic Temporal Model of Polyphonic MIDI Performance with Ornaments
Aug 03, 2016
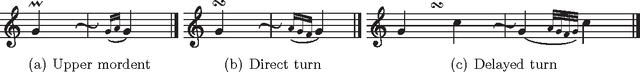
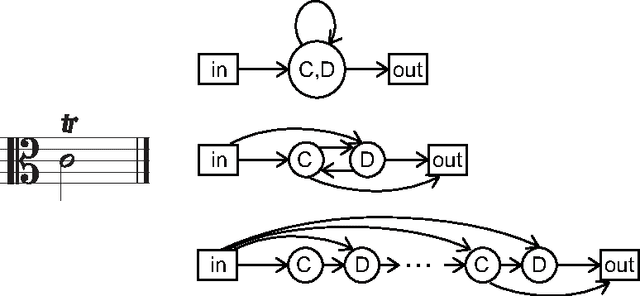
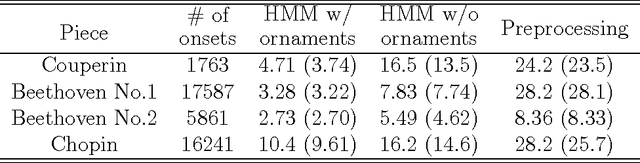
We study indeterminacies in realization of ornaments and how they can be incorporated in a stochastic performance model applicable for music information processing such as score-performance matching. We point out the importance of temporal information, and propose a hidden Markov model which describes it explicitly and represents ornaments with several state types. Following a review of the indeterminacies, they are carefully incorporated into the model through its topology and parameters, and the state construction for quite general polyphonic scores is explained in detail. By analyzing piano performance data, we find significant overlaps in inter-onset-interval distributions of chordal notes, ornaments, and inter-chord events, and the data is used to determine details of the model. The model is applied for score following and offline score-performance matching, yielding highly accurate matching for performances with many ornaments and relatively frequent errors, repeats, and skips.
* 35 pages, 6 figures, some explanations and evaluation results added, version accepted to JNMR