 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRhythm Transcription of Polyphonic Piano Music Based on Merged-Output HMM for Multiple Voices
Paper and Code
Jan 29, 2017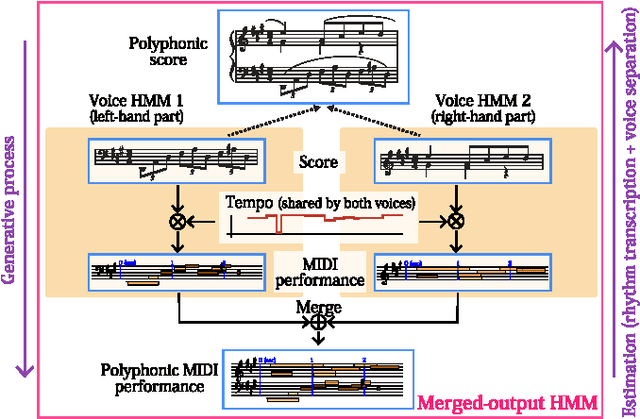


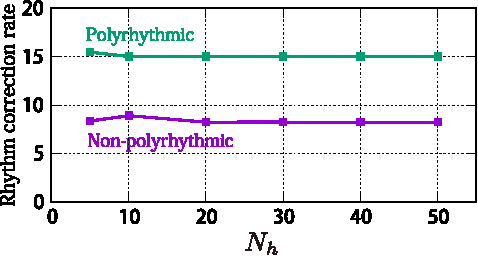
In a recent conference paper, we have reported a rhythm transcription method based on a merged-output hidden Markov model (HMM) that explicitly describes the multiple-voice structure of polyphonic music. This model solves a major problem of conventional methods that could not properly describe the nature of multiple voices as in polyrhythmic scores or in the phenomenon of loose synchrony between voices. In this paper we present a complete description of the proposed model and develop an inference technique, which is valid for any merged-output HMMs for which output probabilities depend on past events. We also examine the influence of the architecture and parameters of the method in terms of accuracies of rhythm transcription and voice separation and perform comparative evaluations with six other algorithms. Using MIDI recordings of classical piano pieces, we found that the proposed model outperformed other methods by more than 12 points in the accuracy for polyrhythmic performances and performed almost as good as the best one for non-polyrhythmic performances. This reveals the state-of-the-art methods of rhythm transcription for the first time in the literature. Publicly available source codes are also provided for future comparisons.