Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Statistical Models with Self-Emergent Grammar of Chord Sequences
Paper and Code
Mar 02, 2018
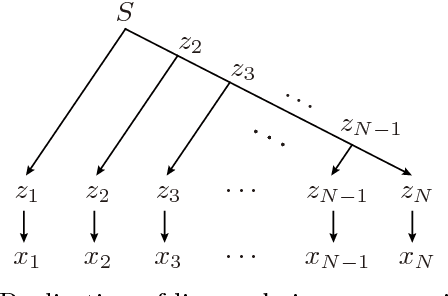

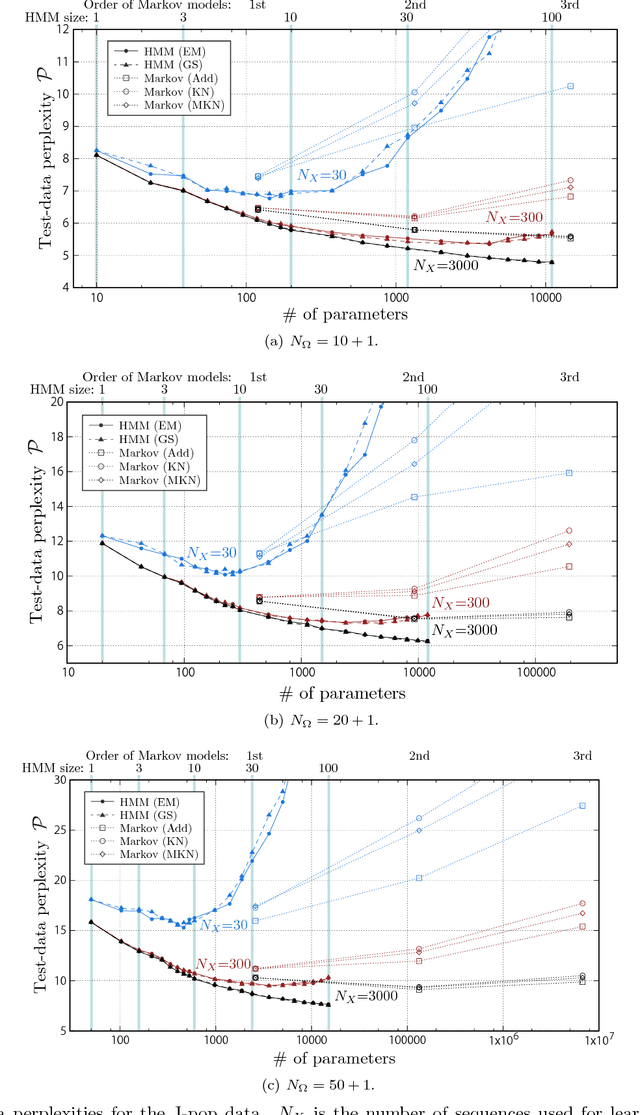
Generative statistical models of chord sequences play crucial roles in music processing. To capture syntactic similarities among certain chords (e.g. in C major key, between G and G7 and between F and Dm), we study hidden Markov models and probabilistic context-free grammar models with latent variables describing syntactic categories of chord symbols and their unsupervised learning techniques for inducing the latent grammar from data. Surprisingly, we find that these models often outperform conventional Markov models in predictive power, and the self-emergent categories often correspond to traditional harmonic functions. This implies the need for chord categories in harmony models from the informatics perspective.
* 22 pages, 14 figures, version accepted to JNMR, minor revision
View paper on