 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Equalization for Individual Instrument Tracks Using Convolutional Neural Networks
Jul 23, 2024We propose a novel approach for the automatic equalization of individual musical instrument tracks. Our method begins by identifying the instrument present within a source recording in order to choose its corresponding ideal spectrum as a target. Next, the spectral difference between the recording and the target is calculated, and accordingly, an equalizer matching model is used to predict settings for a parametric equalizer. To this end, we build upon a differentiable parametric equalizer matching neural network, demonstrating improvements relative to previously established state-of-the-art. Unlike past approaches, we show how our system naturally allows real-world audio data to be leveraged during the training of our matching model, effectively generating suitably produced training targets in an automated manner mirroring conditions at inference time. Consequently, we illustrate how fine-tuning our matching model on such examples considerably improves parametric equalizer matching performance in real-world scenarios, decreasing mean absolute error by 24% relative to methods relying solely on random parameter sampling techniques as a self-supervised learning strategy. We perform listening tests, and demonstrate that our proposed automatic equalization solution subjectively enhances the tonal characteristics for recordings of common instrument types.
Synthesizer Sound Matching Using Audio Spectrogram Transformers
Jul 23, 2024

Systems for synthesizer sound matching, which automatically set the parameters of a synthesizer to emulate an input sound, have the potential to make the process of synthesizer programming faster and easier for novice and experienced musicians alike, whilst also affording new means of interaction with synthesizers. Considering the enormous variety of synthesizers in the marketplace, and the complexity of many of them, general-purpose sound matching systems that function with minimal knowledge or prior assumptions about the underlying synthesis architecture are particularly desirable. With this in mind, we introduce a synthesizer sound matching model based on the Audio Spectrogram Transformer. We demonstrate the viability of this model by training on a large synthetic dataset of randomly generated samples from the popular Massive synthesizer. We show that this model can reconstruct parameters of samples generated from a set of 16 parameters, highlighting its improved fidelity relative to multi-layer perceptron and convolutional neural network baselines. We also provide audio examples demonstrating the out-of-domain model performance in emulating vocal imitations, and sounds from other synthesizers and musical instruments.
DSP-informed bandwidth extension using locally-conditioned excitation and linear time-varying filter subnetworks
Jul 22, 2024
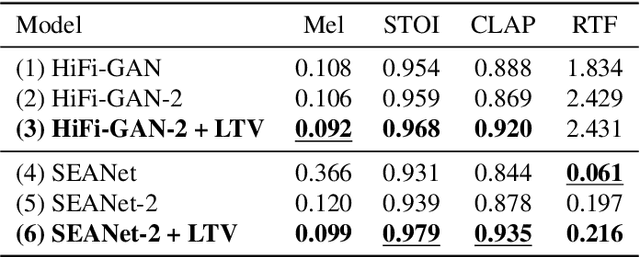
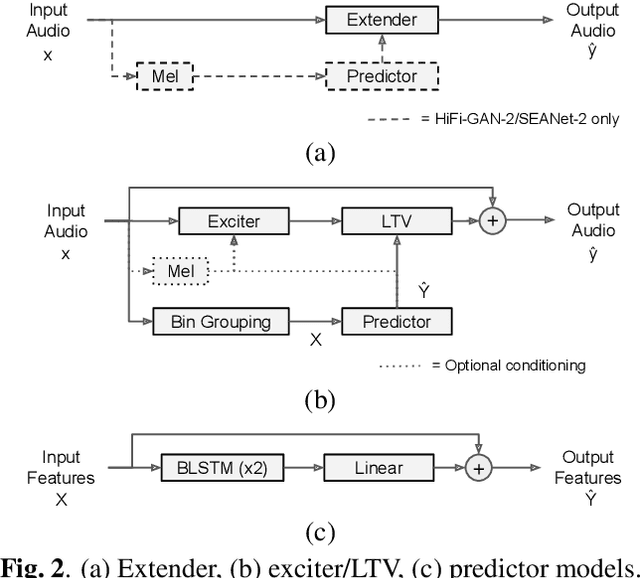
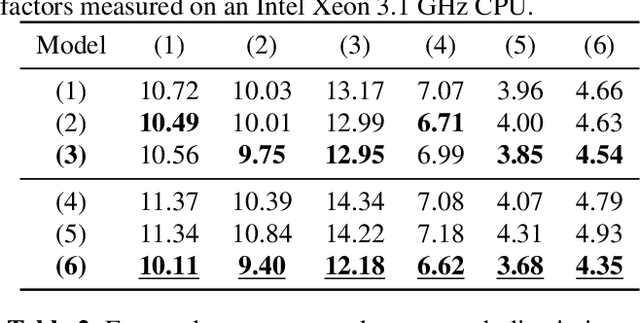
In this paper, we propose a dual-stage architecture for bandwidth extension (BWE) increasing the effective sampling rate of speech signals from 8 kHz to 48 kHz. Unlike existing end-to-end deep learning models, our proposed method explicitly models BWE using excitation and linear time-varying (LTV) filter stages. The excitation stage broadens the spectrum of the input, while the filtering stage properly shapes it based on outputs from an acoustic feature predictor. To this end, an acoustic feature loss term can implicitly promote the excitation subnetwork to produce white spectra in the upper frequency band to be synthesized. Experimental results demonstrate that the added inductive bias provided by our approach can improve upon BWE results using the generators from both SEANet or HiFi-GAN as exciters, and that our means of adapting processing with acoustic feature predictions is more effective than that used in HiFi-GAN-2. Secondary contributions include extensions of the SEANet model to accommodate local conditioning information, as well as the application of HiFi-GAN-2 for the BWE problem.
Generating Sample-Based Musical Instruments Using Neural Audio Codec Language Models
Jul 22, 2024In this paper, we propose and investigate the use of neural audio codec language models for the automatic generation of sample-based musical instruments based on text or reference audio prompts. Our approach extends a generative audio framework to condition on pitch across an 88-key spectrum, velocity, and a combined text/audio embedding. We identify maintaining timbral consistency within the generated instruments as a major challenge. To tackle this issue, we introduce three distinct conditioning schemes. We analyze our methods through objective metrics and human listening tests, demonstrating that our approach can produce compelling musical instruments. Specifically, we introduce a new objective metric to evaluate the timbral consistency of the generated instruments and adapt the average Contrastive Language-Audio Pretraining (CLAP) score for the text-to-instrument case, noting that its naive application is unsuitable for assessing this task. Our findings reveal a complex interplay between timbral consistency, the quality of generated samples, and their correspondence to the input prompt.
InstrumentGen: Generating Sample-Based Musical Instruments From Text
Nov 07, 2023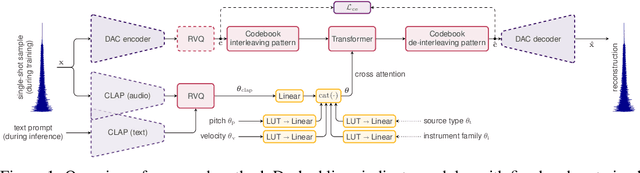
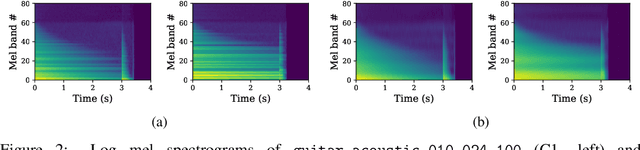
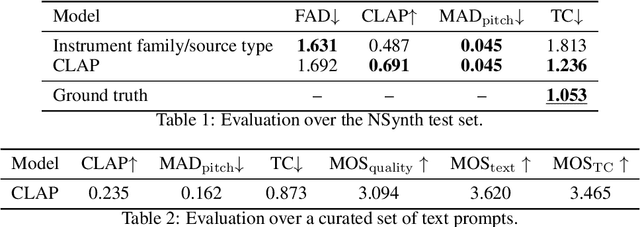
We introduce the text-to-instrument task, which aims at generating sample-based musical instruments based on textual prompts. Accordingly, we propose InstrumentGen, a model that extends a text-prompted generative audio framework to condition on instrument family, source type, pitch (across an 88-key spectrum), velocity, and a joint text/audio embedding. Furthermore, we present a differentiable loss function to evaluate the intra-instrument timbral consistency of sample-based instruments. Our results establish a foundational text-to-instrument baseline, extending research in the domain of automatic sample-based instrument generation.
Differentiable WORLD Synthesizer-based Neural Vocoder With Application To End-To-End Audio Style Transfer
Sep 01, 2022


In this paper, we propose a differentiable WORLD synthesizer and demonstrate its use in end-to-end audio style transfer tasks such as (singing) voice conversion and the DDSP timbre transfer task. Accordingly, our baseline differentiable synthesizer has no model parameters, yet it yields adequate synthesis quality. We can extend the baseline synthesizer by appending lightweight black-box postnets which apply further processing to the baseline output in order to improve fidelity. An alternative differentiable approach considers extraction of the source excitation spectrum directly, which can improve naturalness albeit for a narrower class of style transfer applications. The acoustic feature parameterization used by our approaches has the added benefit that it naturally disentangles pitch and timbral information so that they can be modeled separately. Moreover, as there exists a robust means of estimating these acoustic features from monophonic audio sources, it allows for parameter loss terms to be added to an end-to-end objective function, which can help convergence and/or further stabilize (adversarial) training.
Lightweight and interpretable neural modeling of an audio distortion effect using hyperconditioned differentiable biquads
Mar 15, 2021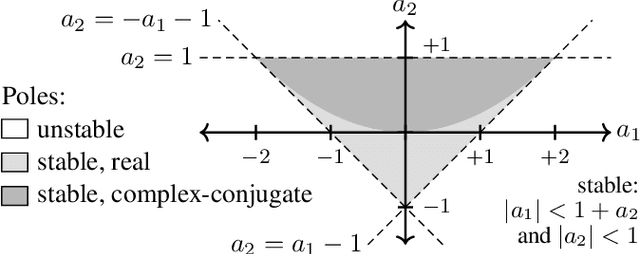

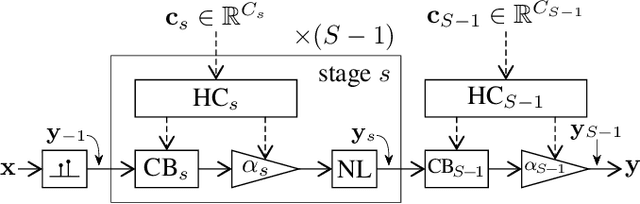

In this work, we propose using differentiable cascaded biquads to model an audio distortion effect. We extend trainable infinite impulse response (IIR) filters to the hyperconditioned case, in which a transformation is learned to directly map external parameters of the distortion effect to its internal filter and gain parameters, along with activations necessary to ensure filter stability. We propose a novel, efficient training scheme of IIR filters by means of a Fourier transform. Our models have significantly fewer parameters and reduced complexity relative to more traditional black-box neural audio effect modeling methodologies using finite impulse response filters. Our smallest, best-performing model adequately models a BOSS MT-2 pedal at 44.1 kHz, using a total of 40 biquads and only 210 parameters. Its model parameters are interpretable, can be related back to the original analog audio circuit, and can even be intuitively altered by machine learning non-specialists after model training. Quantitative and qualitative results illustrate the effectiveness of the proposed method.