 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSP-informed bandwidth extension using locally-conditioned excitation and linear time-varying filter subnetworks
Jul 22, 2024
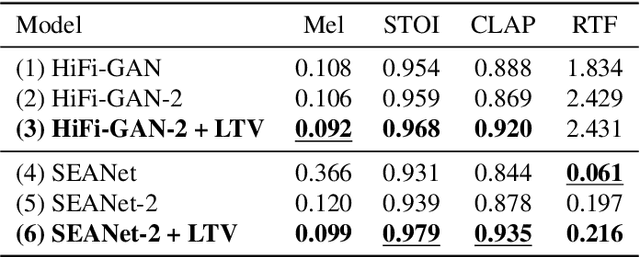
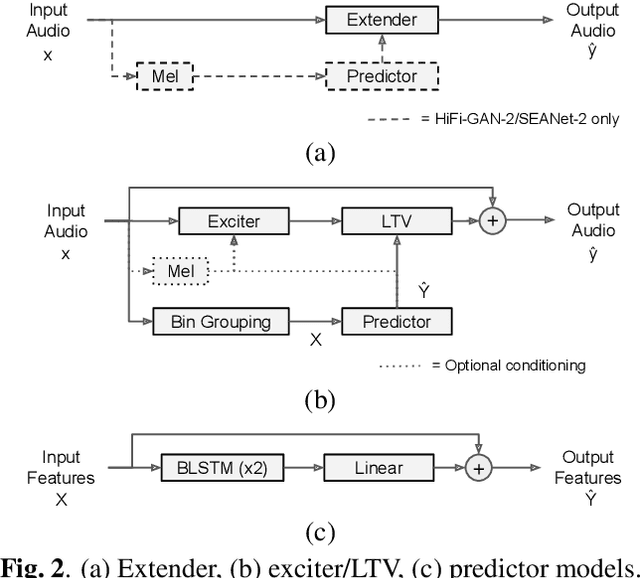
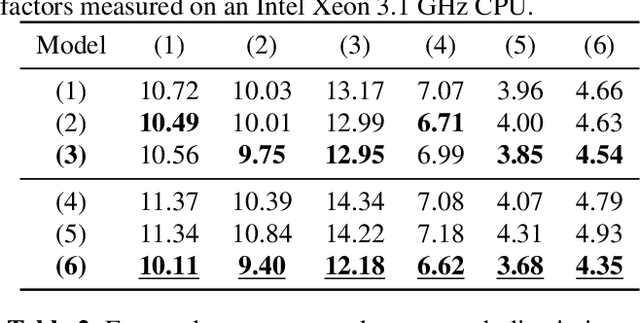
In this paper, we propose a dual-stage architecture for bandwidth extension (BWE) increasing the effective sampling rate of speech signals from 8 kHz to 48 kHz. Unlike existing end-to-end deep learning models, our proposed method explicitly models BWE using excitation and linear time-varying (LTV) filter stages. The excitation stage broadens the spectrum of the input, while the filtering stage properly shapes it based on outputs from an acoustic feature predictor. To this end, an acoustic feature loss term can implicitly promote the excitation subnetwork to produce white spectra in the upper frequency band to be synthesized. Experimental results demonstrate that the added inductive bias provided by our approach can improve upon BWE results using the generators from both SEANet or HiFi-GAN as exciters, and that our means of adapting processing with acoustic feature predictions is more effective than that used in HiFi-GAN-2. Secondary contributions include extensions of the SEANet model to accommodate local conditioning information, as well as the application of HiFi-GAN-2 for the BWE problem.