 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight and interpretable neural modeling of an audio distortion effect using hyperconditioned differentiable biquads
Mar 15, 2021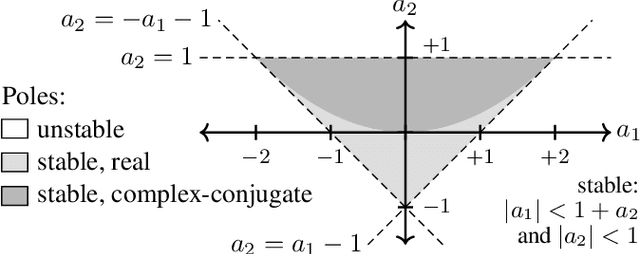

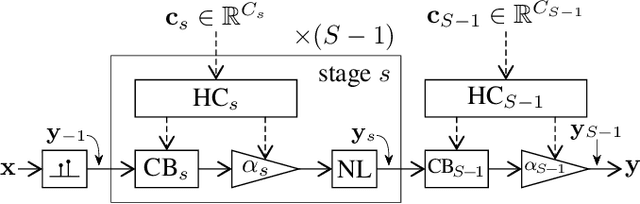

In this work, we propose using differentiable cascaded biquads to model an audio distortion effect. We extend trainable infinite impulse response (IIR) filters to the hyperconditioned case, in which a transformation is learned to directly map external parameters of the distortion effect to its internal filter and gain parameters, along with activations necessary to ensure filter stability. We propose a novel, efficient training scheme of IIR filters by means of a Fourier transform. Our models have significantly fewer parameters and reduced complexity relative to more traditional black-box neural audio effect modeling methodologies using finite impulse response filters. Our smallest, best-performing model adequately models a BOSS MT-2 pedal at 44.1 kHz, using a total of 40 biquads and only 210 parameters. Its model parameters are interpretable, can be related back to the original analog audio circuit, and can even be intuitively altered by machine learning non-specialists after model training. Quantitative and qualitative results illustrate the effectiveness of the proposed method.
Phasebook and Friends: Leveraging Discrete Representations for Source Separation
Oct 02, 2018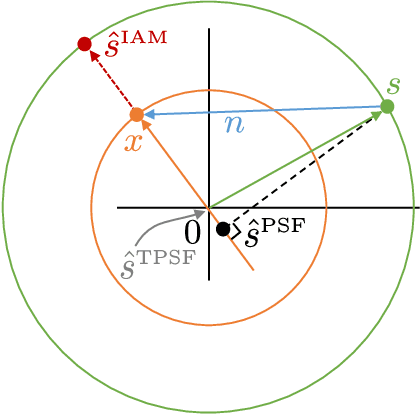

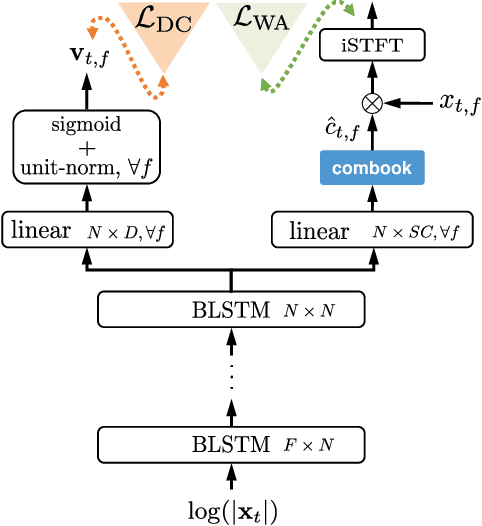
Deep learning based speech enhancement and source separation systems have recently reached unprecedented levels of quality, to the point that performance is reaching a new ceiling. Most systems rely on estimating the magnitude of a target source by estimating a real-valued mask to be applied to a time-frequency representation of the mixture signal. A limiting factor in such approaches is a lack of phase estimation: the phase of the mixture is most often used when reconstructing the estimated time-domain signal. Here, we propose `MagBook', `phasebook', and `Combook', three new types of layers based on discrete representations that can be used to estimate complex time-frequency masks. MagBook layers extend classical sigmoidal units and a recently introduced convex softmax activation for mask-based magnitude estimation. Phasebook layers use a similar structure to give an estimate of the phase mask without suffering from phase wrapping issues. Combook layers are an alternative to the MagBook-Phasebook combination that directly estimate complex masks. We present various training and inference regimes involving these representations, and explain in particular how to include them in an end-to-end learning framework. We also present an oracle study to assess upper bounds on performance for various types of masks using discrete phase representations. We evaluate the proposed methods on the wsj0-2mix dataset, a well-studied corpus for single-channel speaker-independent speaker separation, matching the performance of state-of-the-art mask-based approaches without requiring additional phase reconstruction steps.