 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal audio synthesizer control with normalizing flows
Jul 01, 2019
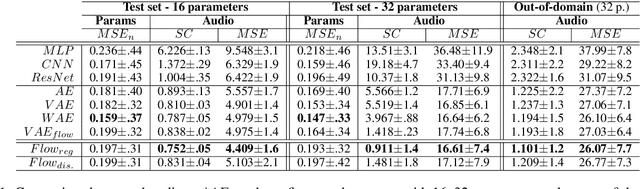
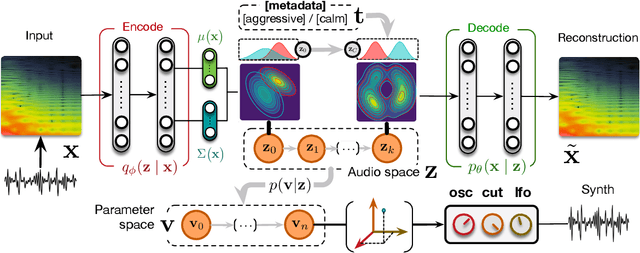
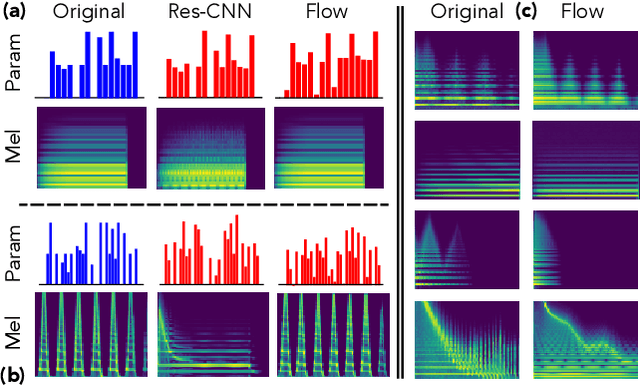
The ubiquity of sound synthesizers has reshaped music production and even entirely defined new music genres. However, the increasing complexity and number of parameters in modern synthesizers make them harder to master. Hence, the development of methods allowing to easily create and explore with synthesizers is a crucial need. Here, we introduce a novel formulation of audio synthesizer control. We formalize it as finding an organized latent audio space that represents the capabilities of a synthesizer, while constructing an invertible mapping to the space of its parameters. By using this formulation, we show that we can address simultaneously automatic parameter inference, macro-control learning and audio-based preset exploration within a single model. To solve this new formulation, we rely on Variational Auto-Encoders (VAE) and Normalizing Flows (NF) to organize and map the respective auditory and parameter spaces. We introduce the disentangling flows, which allow to perform the invertible mapping between separate latent spaces, while steering the organization of some latent dimensions to match target variation factors by splitting the objective as partial density evaluation. We evaluate our proposal against a large set of baseline models and show its superiority in both parameter inference and audio reconstruction. We also show that the model disentangles the major factors of audio variations as latent dimensions, that can be directly used as macro-parameters. We also show that our model is able to learn semantic controls of a synthesizer by smoothly mapping to its parameters. Finally, we discuss the use of our model in creative applications and its real-time implementation in Ableton Live
LIUM-CVC Submissions for WMT18 Multimodal Translation Task
Sep 01, 2018
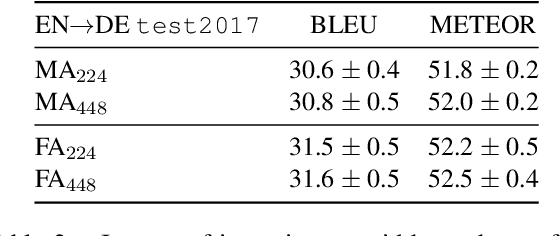
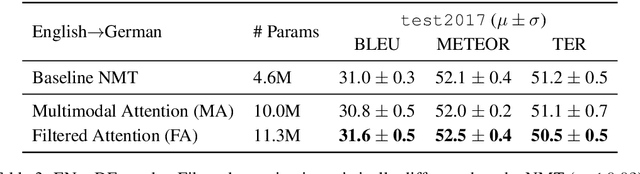
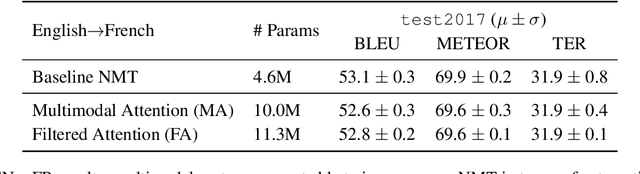
This paper describes the multimodal Neural Machine Translation systems developed by LIUM and CVC for WMT18 Shared Task on Multimodal Translation. This year we propose several modifications to our previous multimodal attention architecture in order to better integrate convolutional features and refine them using encoder-side information. Our final constrained submissions ranked first for English-French and second for English-German language pairs among the constrained submissions according to the automatic evaluation metric METEOR.
LIUM Machine Translation Systems for WMT17 News Translation Task
Jul 14, 2017

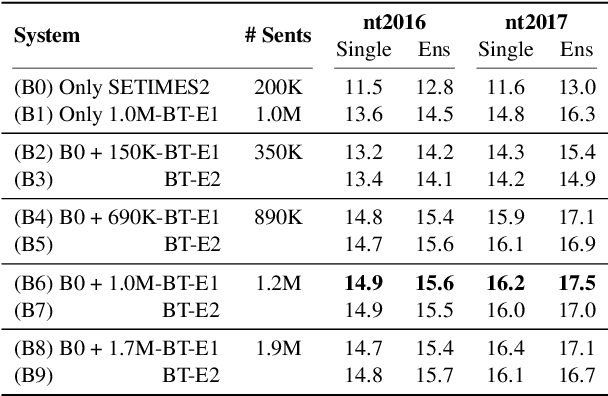
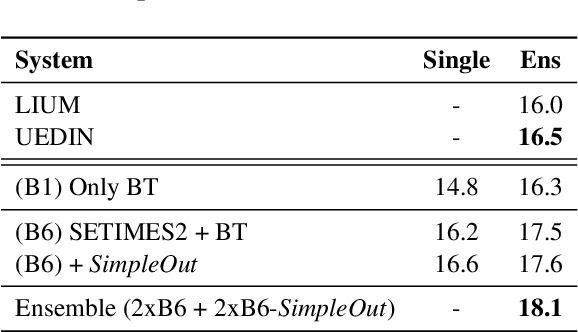
This paper describes LIUM submissions to WMT17 News Translation Task for English-German, English-Turkish, English-Czech and English-Latvian language pairs. We train BPE-based attentive Neural Machine Translation systems with and without factored outputs using the open source nmtpy framework. Competitive scores were obtained by ensembling various systems and exploiting the availability of target monolingual corpora for back-translation. The impact of back-translation quantity and quality is also analyzed for English-Turkish where our post-deadline submission surpassed the best entry by +1.6 BLEU.
LIUM-CVC Submissions for WMT17 Multimodal Translation Task
Jul 14, 2017This paper describes the monomodal and multimodal Neural Machine Translation systems developed by LIUM and CVC for WMT17 Shared Task on Multimodal Translation. We mainly explored two multimodal architectures where either global visual features or convolutional feature maps are integrated in order to benefit from visual context. Our final systems ranked first for both En-De and En-Fr language pairs according to the automatic evaluation metrics METEOR and BLEU.
NMTPY: A Flexible Toolkit for Advanced Neural Machine Translation Systems
Jun 01, 2017



In this paper, we present nmtpy, a flexible Python toolkit based on Theano for training Neural Machine Translation and other neural sequence-to-sequence architectures. nmtpy decouples the specification of a network from the training and inference utilities to simplify the addition of a new architecture and reduce the amount of boilerplate code to be written. nmtpy has been used for LIUM's top-ranked submissions to WMT Multimodal Machine Translation and News Translation tasks in 2016 and 2017.