 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssisted Sound Sample Generation with Musical Conditioning in Adversarial Auto-Encoders
Paper and Code
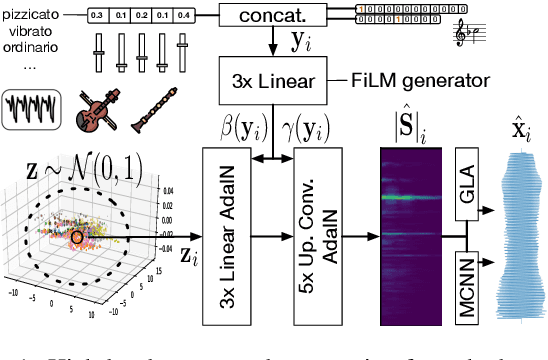
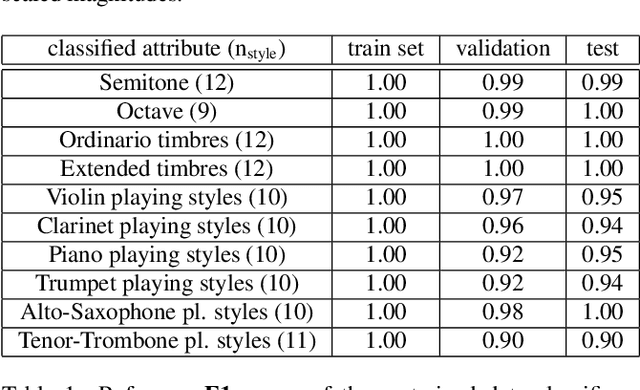
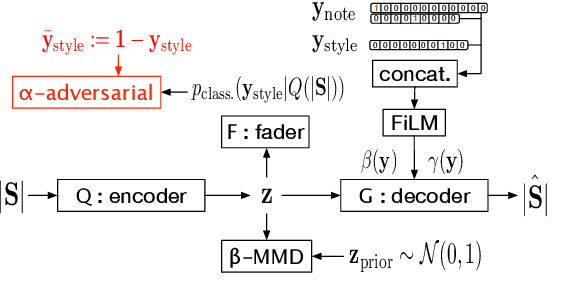
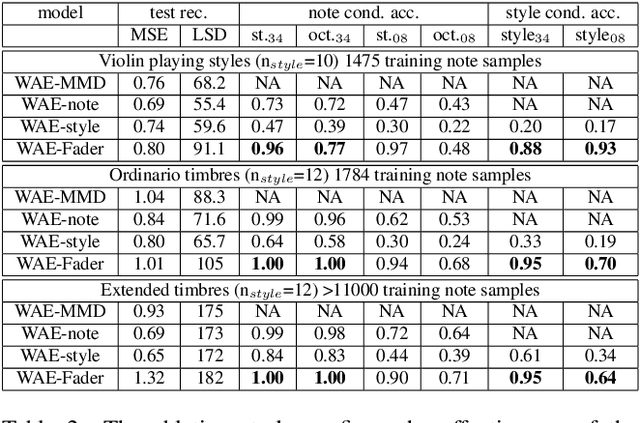
Generative models have thrived in computer vision, enabling unprecedented image processes. Yet the results in audio remain less advanced. Our project targets real-time sound synthesis from a reduced set of high-level parameters, including semantic controls that can be adapted to different sound libraries and specific tags. These generative variables should allow expressive modulations of target musical qualities and continuously mix into new styles. To this extent we train AEs on an orchestral database of individual note samples, along with their intrinsic attributes: note class, timbre domain and extended playing techniques. We condition the decoder for control over the rendered note attributes and use latent adversarial training for learning expressive style parameters that can ultimately be mixed. We evaluate both generative performances and latent representation. Our ablation study demonstrates the effectiveness of the musical conditioning mechanisms. The proposed model generates notes as magnitude spectrograms from any probabilistic latent code samples, with expressive control of orchestral timbres and playing styles. Its training data subsets can directly be visualized in the 3D latent representation. Waveform rendering can be done offline with GLA. In order to allow real-time interactions, we fine-tune the decoder with a pretrained MCNN and embed the full waveform generation pipeline in a plugin. Moreover the encoder could be used to process new input samples, after manipulating their latent attribute representation, the decoder can generate sample variations as an audio effect would. Our solution remains rather fast to train, it can directly be applied to other sound domains, including an user's libraries with custom sound tags that could be mapped to specific generative controls. As a result, it fosters creativity and intuitive audio style experimentations.