 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral-Adaptive Modulation Networks for Visual Perception
Mar 31, 2025Recent studies have shown that 2D convolution and self-attention exhibit distinct spectral behaviors, and optimizing their spectral properties can enhance vision model performance. However, theoretical analyses remain limited in explaining why 2D convolution is more effective in high-pass filtering than self-attention and why larger kernels favor shape bias, akin to self-attention. In this paper, we employ graph spectral analysis to theoretically simulate and compare the frequency responses of 2D convolution and self-attention within a unified framework. Our results corroborate previous empirical findings and reveal that node connectivity, modulated by window size, is a key factor in shaping spectral functions. Leveraging this insight, we introduce a \textit{spectral-adaptive modulation} (SPAM) mixer, which processes visual features in a spectral-adaptive manner using multi-scale convolutional kernels and a spectral re-scaling mechanism to refine spectral components. Based on SPAM, we develop SPANetV2 as a novel vision backbone. Extensive experiments demonstrate that SPANetV2 outperforms state-of-the-art models across multiple vision tasks, including ImageNet-1K classification, COCO object detection, and ADE20K semantic segmentation.
SPANet: Frequency-balancing Token Mixer using Spectral Pooling Aggregation Modulation
Aug 22, 2023Recent studies show that self-attentions behave like low-pass filters (as opposed to convolutions) and enhancing their high-pass filtering capability improves model performance. Contrary to this idea, we investigate existing convolution-based models with spectral analysis and observe that improving the low-pass filtering in convolution operations also leads to performance improvement. To account for this observation, we hypothesize that utilizing optimal token mixers that capture balanced representations of both high- and low-frequency components can enhance the performance of models. We verify this by decomposing visual features into the frequency domain and combining them in a balanced manner. To handle this, we replace the balancing problem with a mask filtering problem in the frequency domain. Then, we introduce a novel token-mixer named SPAM and leverage it to derive a MetaFormer model termed as SPANet. Experimental results show that the proposed method provides a way to achieve this balance, and the balanced representations of both high- and low-frequency components can improve the performance of models on multiple computer vision tasks. Our code is available at $\href{https://doranlyong.github.io/projects/spanet/}{\text{https://doranlyong.github.io/projects/spanet/}}$.
PAM:Point-wise Attention Module for 6D Object Pose Estimation
Aug 12, 2020
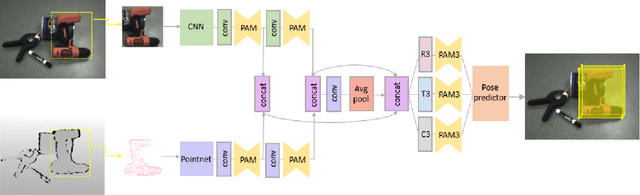
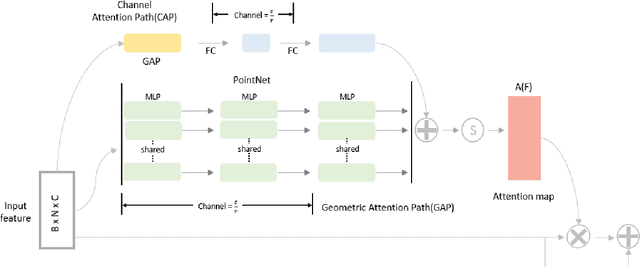
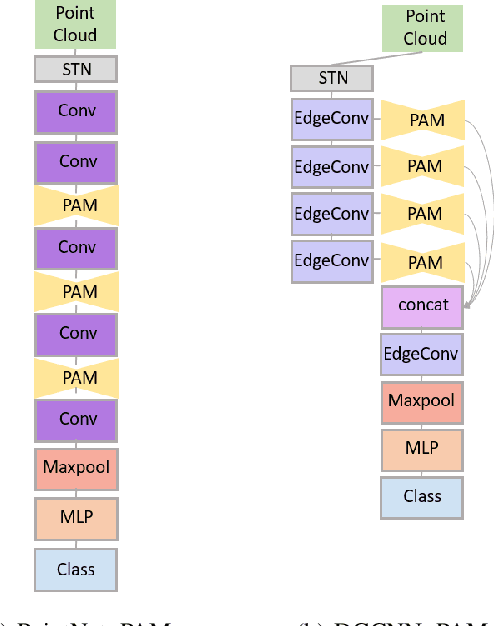
6D pose estimation refers to object recognition and estimation of 3D rotation and 3D translation. The key technology for estimating 6D pose is to estimate pose by extracting enough features to find pose in any environment. Previous methods utilized depth information in the refinement process or were designed as a heterogeneous architecture for each data space to extract feature. However, these methods are limited in that they cannot extract sufficient feature. Therefore, this paper proposes a Point Attention Module that can efficiently extract powerful feature from RGB-D. In our Module, attention map is formed through a Geometric Attention Path(GAP) and Channel Attention Path(CAP). In GAP, it is designed to pay attention to important information in geometric information, and CAP is designed to pay attention to important information in Channel information. We show that the attention module efficiently creates feature representations without significantly increasing computational complexity. Experimental results show that the proposed method outperforms the existing methods in benchmarks, YCB Video and LineMod. In addition, the attention module was applied to the classification task, and it was confirmed that the performance significantly improved compared to the existing model.
Planning for target retrieval using a robotic manipulator in cluttered and occluded environments
Jul 09, 2019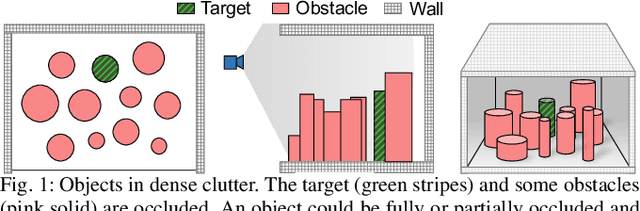
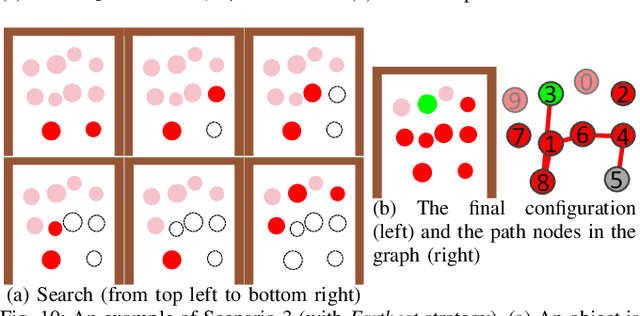
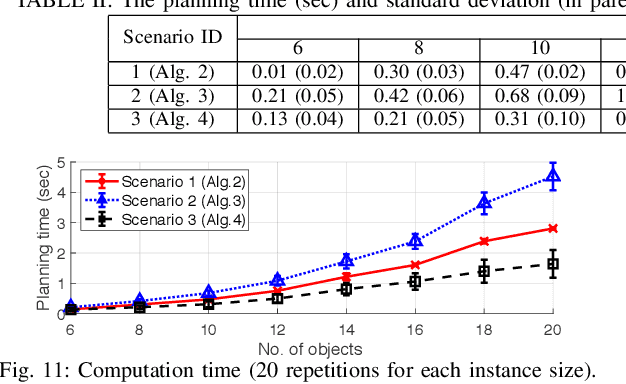
This paper presents planning algorithms for a robotic manipulator with a fixed base in order to grasp a target object in cluttered environments. We consider a configuration of objects in a confined space with a high density so no collision-free path to the target exists. The robot must relocate some objects to retrieve the target while avoiding collisions. For fast completion of the retrieval task, the robot needs to compute a plan optimizing an appropriate objective value directly related to the execution time of the relocation plan. We propose planning algorithms that aim to minimize the number of objects to be relocated. Our objective value is appropriate for the object retrieval task because grasping and releasing objects often dominate the total running time. In addition to the algorithm working in fully known and static environments, we propose algorithms that can deal with uncertain and dynamic situations incurred by occluded views. The proposed algorithms are shown to be complete and run in polynomial time. Our methods reduce the total running time significantly compared to a baseline method (e.g., 25.1% of reduction in a known static environment with 10 objects