 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Granularity Video Object Segmentation
Dec 03, 2024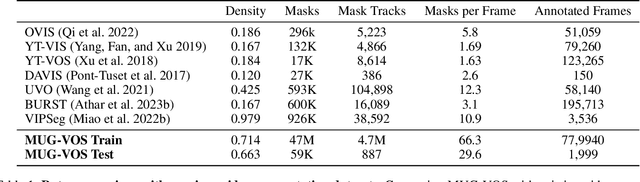
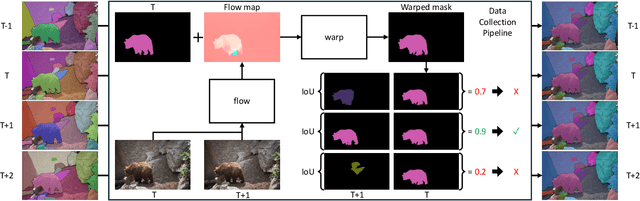


Current benchmarks for video segmentation are limited to annotating only salient objects (i.e., foreground instances). Despite their impressive architectural designs, previous works trained on these benchmarks have struggled to adapt to real-world scenarios. Thus, developing a new video segmentation dataset aimed at tracking multi-granularity segmentation target in the video scene is necessary. In this work, we aim to generate multi-granularity video segmentation dataset that is annotated for both salient and non-salient masks. To achieve this, we propose a large-scale, densely annotated multi-granularity video object segmentation (MUG-VOS) dataset that includes various types and granularities of mask annotations. We automatically collected a training set that assists in tracking both salient and non-salient objects, and we also curated a human-annotated test set for reliable evaluation. In addition, we present memory-based mask propagation model (MMPM), trained and evaluated on MUG-VOS dataset, which leads to the best performance among the existing video object segmentation methods and Segment SAM-based video segmentation methods. Project page is available at https://cvlab-kaist.github.io/MUG-VOS.
Context Enhanced Transformer for Single Image Object Detection
Dec 26, 2023



With the increasing importance of video data in real-world applications, there is a rising need for efficient object detection methods that utilize temporal information. While existing video object detection (VOD) techniques employ various strategies to address this challenge, they typically depend on locally adjacent frames or randomly sampled images within a clip. Although recent Transformer-based VOD methods have shown promising results, their reliance on multiple inputs and additional network complexity to incorporate temporal information limits their practical applicability. In this paper, we propose a novel approach to single image object detection, called Context Enhanced TRansformer (CETR), by incorporating temporal context into DETR using a newly designed memory module. To efficiently store temporal information, we construct a class-wise memory that collects contextual information across data. Additionally, we present a classification-based sampling technique to selectively utilize the relevant memory for the current image. In the testing, We introduce a test-time memory adaptation method that updates individual memory functions by considering the test distribution. Experiments with CityCam and ImageNet VID datasets exhibit the efficiency of the framework on various video systems. The project page and code will be made available at: https://ku-cvlab.github.io/CETR.
CAT-Seg: Cost Aggregation for Open-Vocabulary Semantic Segmentation
Mar 21, 2023Existing works on open-vocabulary semantic segmentation have utilized large-scale vision-language models, such as CLIP, to leverage their exceptional open-vocabulary recognition capabilities. However, the problem of transferring these capabilities learned from image-level supervision to the pixel-level task of segmentation and addressing arbitrary unseen categories at inference makes this task challenging. To address these issues, we aim to attentively relate objects within an image to given categories by leveraging relational information among class categories and visual semantics through aggregation, while also adapting the CLIP representations to the pixel-level task. However, we observe that direct optimization of the CLIP embeddings can harm its open-vocabulary capabilities. In this regard, we propose an alternative approach to optimize the image-text similarity map, i.e. the cost map, using a novel cost aggregation-based method. Our framework, namely CAT-Seg, achieves state-of-the-art performance across all benchmarks. We provide extensive ablation studies to validate our choices. Project page: https://ku-cvlab.github.io/CAT-Seg/.