 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext Enhanced Transformer for Single Image Object Detection
Dec 26, 2023



With the increasing importance of video data in real-world applications, there is a rising need for efficient object detection methods that utilize temporal information. While existing video object detection (VOD) techniques employ various strategies to address this challenge, they typically depend on locally adjacent frames or randomly sampled images within a clip. Although recent Transformer-based VOD methods have shown promising results, their reliance on multiple inputs and additional network complexity to incorporate temporal information limits their practical applicability. In this paper, we propose a novel approach to single image object detection, called Context Enhanced TRansformer (CETR), by incorporating temporal context into DETR using a newly designed memory module. To efficiently store temporal information, we construct a class-wise memory that collects contextual information across data. Additionally, we present a classification-based sampling technique to selectively utilize the relevant memory for the current image. In the testing, We introduce a test-time memory adaptation method that updates individual memory functions by considering the test distribution. Experiments with CityCam and ImageNet VID datasets exhibit the efficiency of the framework on various video systems. The project page and code will be made available at: https://ku-cvlab.github.io/CETR.
Semi-Supervised Learning of Monocular Depth Estimation via Consistency Regularization with K-way Disjoint Masking
Dec 22, 2022
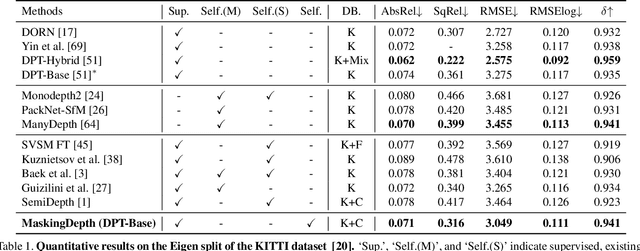
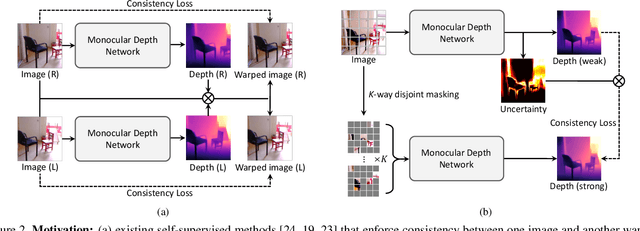
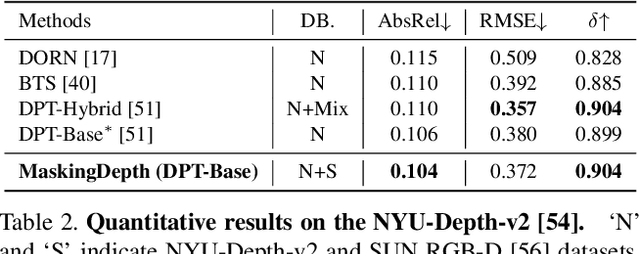
Semi-Supervised Learning (SSL) has recently accomplished successful achievements in various fields such as image classification, object detection, and semantic segmentation, which typically require a lot of labour to construct ground-truth. Especially in the depth estimation task, annotating training data is very costly and time-consuming, and thus recent SSL regime seems an attractive solution. In this paper, for the first time, we introduce a novel framework for semi-supervised learning of monocular depth estimation networks, using consistency regularization to mitigate the reliance on large ground-truth depth data. We propose a novel data augmentation approach, called K-way disjoint masking, which allows the network for learning how to reconstruct invisible regions so that the model not only becomes robust to perturbations but also generates globally consistent output depth maps. Experiments on the KITTI and NYU-Depth-v2 datasets demonstrate the effectiveness of each component in our pipeline, robustness to the use of fewer and fewer annotated images, and superior results compared to other state-of-the-art, semi-supervised methods for monocular depth estimation. Our code is available at https://github.com/KU-CVLAB/MaskingDepth.
DAG: Depth-Aware Guidance with Denoising Diffusion Probabilistic Models
Dec 17, 2022



In recent years, generative models have undergone significant advancement due to the success of diffusion models. The success of these models is often attributed to their use of guidance techniques, such as classifier and classifier-free methods, which provides effective mechanisms to trade-off between fidelity and diversity. However, these methods are not capable of guiding a generated image to be aware of its geometric configuration, e.g., depth, which hinders the application of diffusion models to areas that require a certain level of depth awareness. To address this limitation, we propose a novel guidance approach for diffusion models that uses estimated depth information derived from the rich intermediate representations of diffusion models. To do this, we first present a label-efficient depth estimation framework using the internal representations of diffusion models. At the sampling phase, we utilize two guidance techniques to self-condition the generated image using the estimated depth map, the first of which uses pseudo-labeling, and the subsequent one uses a depth-domain diffusion prior. Experiments and extensive ablation studies demonstrate the effectiveness of our method in guiding the diffusion models toward geometrically plausible image generation. Project page is available at https://ku-cvlab.github.io/DAG/.
InstaFormer: Instance-Aware Image-to-Image Translation with Transformer
Mar 30, 2022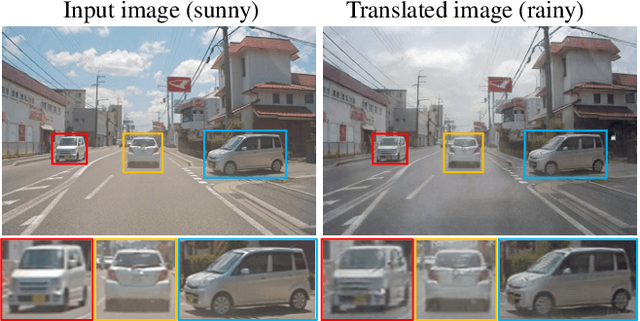

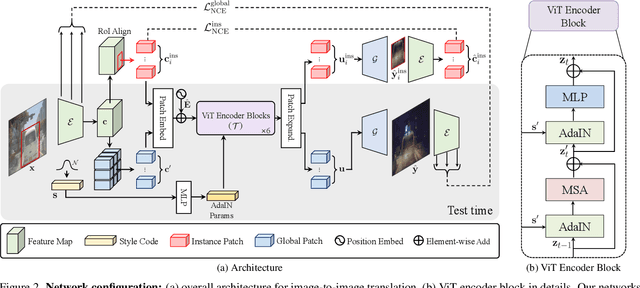
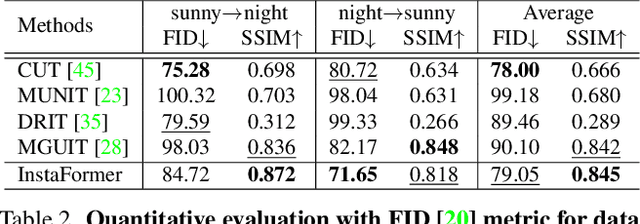
We present a novel Transformer-based network architecture for instance-aware image-to-image translation, dubbed InstaFormer, to effectively integrate global- and instance-level information. By considering extracted content features from an image as tokens, our networks discover global consensus of content features by considering context information through a self-attention module in Transformers. By augmenting such tokens with an instance-level feature extracted from the content feature with respect to bounding box information, our framework is capable of learning an interaction between object instances and the global image, thus boosting the instance-awareness. We replace layer normalization (LayerNorm) in standard Transformers with adaptive instance normalization (AdaIN) to enable a multi-modal translation with style codes. In addition, to improve the instance-awareness and translation quality at object regions, we present an instance-level content contrastive loss defined between input and translated image. We conduct experiments to demonstrate the effectiveness of our InstaFormer over the latest methods and provide extensive ablation studies.
Semi-Supervised Learning with Mutual Distillation for Monocular Depth Estimation
Mar 18, 2022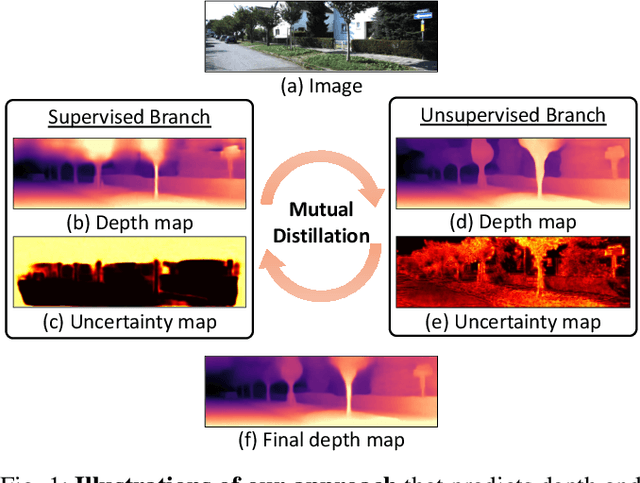

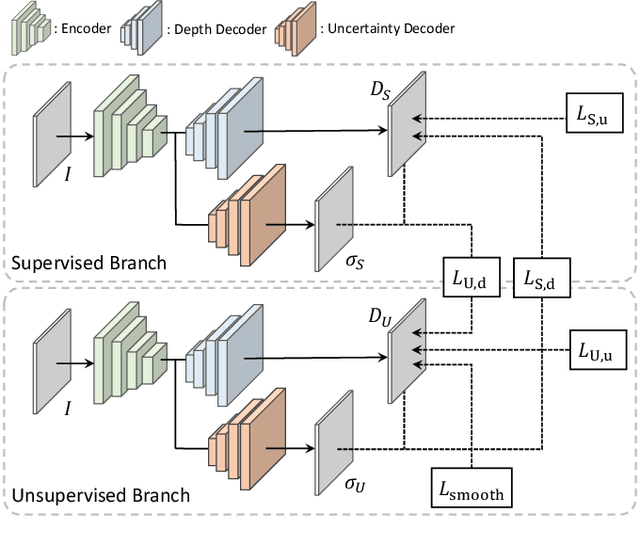

We propose a semi-supervised learning framework for monocular depth estimation. Compared to existing semi-supervised learning methods, which inherit limitations of both sparse supervised and unsupervised loss functions, we achieve the complementary advantages of both loss functions, by building two separate network branches for each loss and distilling each other through the mutual distillation loss function. We also present to apply different data augmentation to each branch, which improves the robustness. We conduct experiments to demonstrate the effectiveness of our framework over the latest methods and provide extensive ablation studies.