 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Learning of Monocular Depth Estimation via Consistency Regularization with K-way Disjoint Masking
Paper and Code

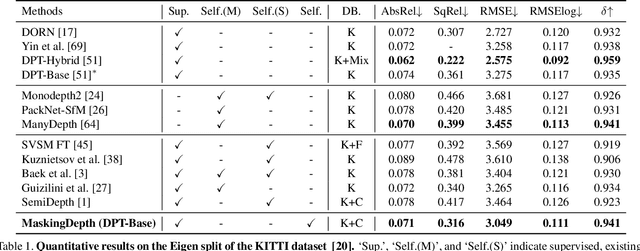
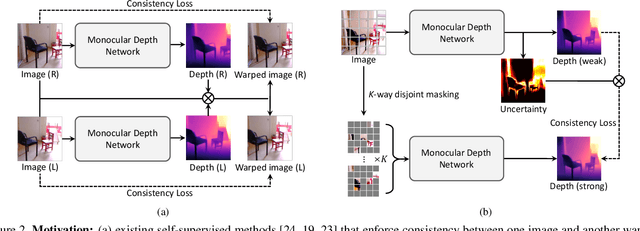
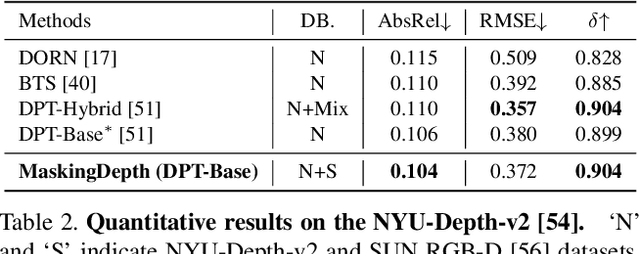
Semi-Supervised Learning (SSL) has recently accomplished successful achievements in various fields such as image classification, object detection, and semantic segmentation, which typically require a lot of labour to construct ground-truth. Especially in the depth estimation task, annotating training data is very costly and time-consuming, and thus recent SSL regime seems an attractive solution. In this paper, for the first time, we introduce a novel framework for semi-supervised learning of monocular depth estimation networks, using consistency regularization to mitigate the reliance on large ground-truth depth data. We propose a novel data augmentation approach, called K-way disjoint masking, which allows the network for learning how to reconstruct invisible regions so that the model not only becomes robust to perturbations but also generates globally consistent output depth maps. Experiments on the KITTI and NYU-Depth-v2 datasets demonstrate the effectiveness of each component in our pipeline, robustness to the use of fewer and fewer annotated images, and superior results compared to other state-of-the-art, semi-supervised methods for monocular depth estimation. Our code is available at https://github.com/KU-CVLAB/MaskingDepth.