 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Open-Vocabulary Semantic Segmentation Without Semantic Labels
Paper and Code
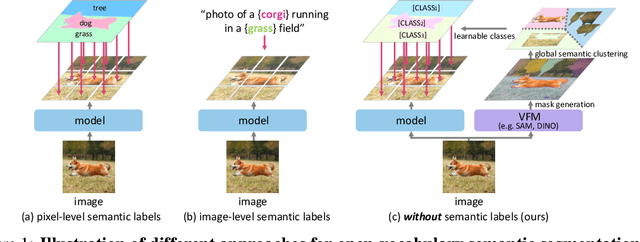
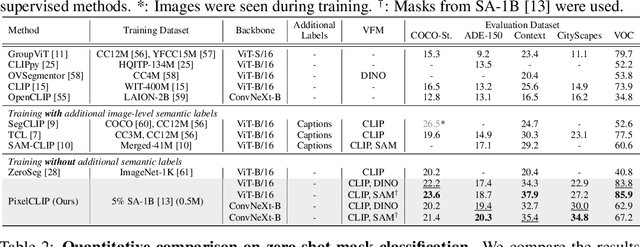

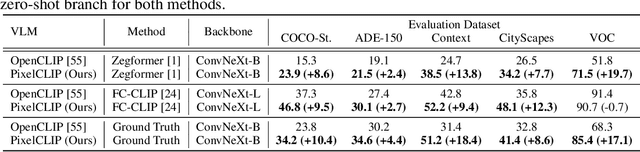
Large-scale vision-language models like CLIP have demonstrated impressive open-vocabulary capabilities for image-level tasks, excelling in recognizing what objects are present. However, they struggle with pixel-level recognition tasks like semantic segmentation, which additionally require understanding where the objects are located. In this work, we propose a novel method, PixelCLIP, to adapt the CLIP image encoder for pixel-level understanding by guiding the model on where, which is achieved using unlabeled images and masks generated from vision foundation models such as SAM and DINO. To address the challenges of leveraging masks without semantic labels, we devise an online clustering algorithm using learnable class names to acquire general semantic concepts. PixelCLIP shows significant performance improvements over CLIP and competitive results compared to caption-supervised methods in open-vocabulary semantic segmentation. Project page is available at https://cvlab-kaist.github.io/PixelCLIP