 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLip Forcing: Few-Step Autoregressive Diffusion for Real-time Lip Synchronization
Jun 09, 2026Diffusion-based lip synchronization models achieve strong visual quality and audio-visual alignment, but full-sequence bidirectional attention and many denoising steps make them impractical for real-time inference. We present Lip Forcing, to our knowledge the first autoregressive diffusion method for video-to-video (V2V) lip synchronization, which distills a 14B audio-conditioned bidirectional video diffusion teacher into causal students. At inference, the students generate each chunk in only two denoising steps without inference-time CFG, enabling real-time lip synchronization. A lip-sync-specific teacher-trajectory analysis reveals a CFG fidelity-sync tradeoff: no-CFG predictions favor reference fidelity, whereas CFG-guided predictions favor synchronization within a mid-trajectory band. Lip Forcing translates this finding into three analysis-derived components: Sync-Window DMD, a two-step inference schedule, and a SyncNet-based reward. We validate Lip Forcing at two student scales, both distilled from the 14B teacher. The 1.3B student crosses into real-time streaming at 31 FPS, $17.6\times$ faster than its same-scale bidirectional model. The 14B student, the largest diffusion model reported for V2V lip synchronization, runs $39.8\times$ faster than its teacher at comparable reference fidelity. Time-to-first-frame is sub-millisecond at both scales, far below every diffusion baseline.
WorldKV: Efficient World Memory with World Retrieval and Compression
May 21, 2026Autoregressive video diffusion models have enabled real-time, action-conditioned world generation. However, sustaining a persistent world, where revisiting a previously seen viewpoint yields consistent content, remains an open problem. Full KV-cache attention preserves this consistency but breaks real-time constraints: memory footprint and attention cost grow linearly with rollout length. Sliding window inference restores throughput but discards long-term consistency. We propose WorldKV, a training-free framework with two components: World Retrieval and World Compression. World Retrieval stores evicted KV-cache chunks in GPU/CPU memory and selectively retrieves scene-relevant chunks via camera/ action correspondence, inserting them back into the native attention window without re-encoding. World Compression prunes redundant tokens within each chunk via key-key similarity to an anchor frame, halving per-chunk storage to fit 2x more history under a fixed budget. On Matrix-Game-2.0 and LingBot- World-Fast, WorldKV matches or exceeds full-KV memory fidelity at roughly 2x the throughput, and is competitive with memory-trained baselines without any fine-tuning. Project Page: https://cvlab-kaist.github.io/WorldKV/
Repurposing Video Diffusion Transformers for Robust Point Tracking
Dec 23, 2025Point tracking aims to localize corresponding points across video frames, serving as a fundamental task for 4D reconstruction, robotics, and video editing. Existing methods commonly rely on shallow convolutional backbones such as ResNet that process frames independently, lacking temporal coherence and producing unreliable matching costs under challenging conditions. Through systematic analysis, we find that video Diffusion Transformers (DiTs), pre-trained on large-scale real-world videos with spatio-temporal attention, inherently exhibit strong point tracking capability and robustly handle dynamic motions and frequent occlusions. We propose DiTracker, which adapts video DiTs through: (1) query-key attention matching, (2) lightweight LoRA tuning, and (3) cost fusion with a ResNet backbone. Despite training with 8 times smaller batch size, DiTracker achieves state-of-the-art performance on challenging ITTO benchmark and matches or outperforms state-of-the-art models on TAP-Vid benchmarks. Our work validates video DiT features as an effective and efficient foundation for point tracking.
Exploring Temporally-Aware Features for Point Tracking
Jan 21, 2025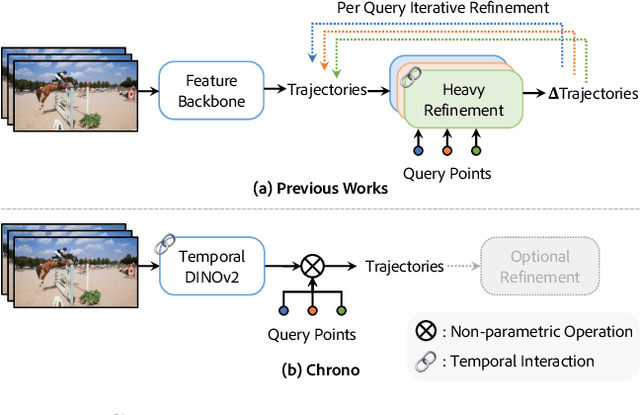
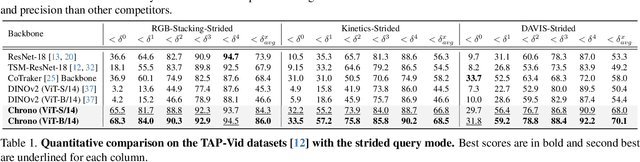


Point tracking in videos is a fundamental task with applications in robotics, video editing, and more. While many vision tasks benefit from pre-trained feature backbones to improve generalizability, point tracking has primarily relied on simpler backbones trained from scratch on synthetic data, which may limit robustness in real-world scenarios. Additionally, point tracking requires temporal awareness to ensure coherence across frames, but using temporally-aware features is still underexplored. Most current methods often employ a two-stage process: an initial coarse prediction followed by a refinement stage to inject temporal information and correct errors from the coarse stage. These approach, however, is computationally expensive and potentially redundant if the feature backbone itself captures sufficient temporal information. In this work, we introduce Chrono, a feature backbone specifically designed for point tracking with built-in temporal awareness. Leveraging pre-trained representations from self-supervised learner DINOv2 and enhanced with a temporal adapter, Chrono effectively captures long-term temporal context, enabling precise prediction even without the refinement stage. Experimental results demonstrate that Chrono achieves state-of-the-art performance in a refiner-free setting on the TAP-Vid-DAVIS and TAP-Vid-Kinetics datasets, among common feature backbones used in point tracking as well as DINOv2, with exceptional efficiency. Project page: https://cvlab-kaist.github.io/Chrono/
Fast Sun-aligned Outdoor Scene Relighting based on TensoRF
Nov 07, 2023

In this work, we introduce our method of outdoor scene relighting for Neural Radiance Fields (NeRF) named Sun-aligned Relighting TensoRF (SR-TensoRF). SR-TensoRF offers a lightweight and rapid pipeline aligned with the sun, thereby achieving a simplified workflow that eliminates the need for environment maps. Our sun-alignment strategy is motivated by the insight that shadows, unlike viewpoint-dependent albedo, are determined by light direction. We directly use the sun direction as an input during shadow generation, simplifying the requirements of the inference process significantly. Moreover, SR-TensoRF leverages the training efficiency of TensoRF by incorporating our proposed cubemap concept, resulting in notable acceleration in both training and rendering processes compared to existing methods.