 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrative Feature and Cost Aggregation with Transformers for Dense Correspondence
Paper and Code
Sep 20, 2022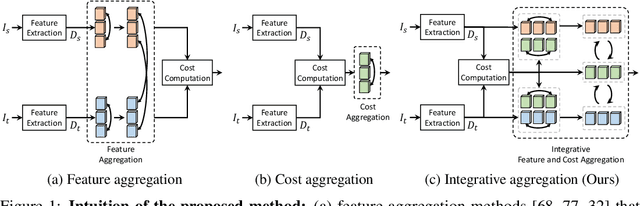
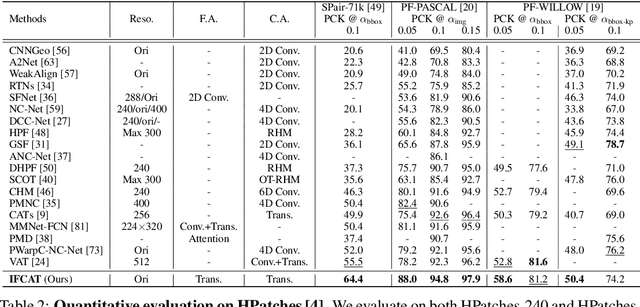

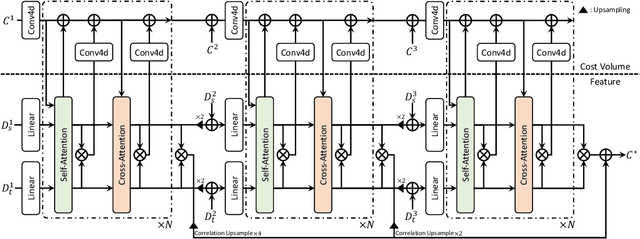
We present a novel architecture for dense correspondence. The current state-of-the-art are Transformer-based approaches that focus on either feature descriptors or cost volume aggregation. However, they generally aggregate one or the other but not both, though joint aggregation would boost each other by providing information that one has but other lacks, i.e., structural or semantic information of an image, or pixel-wise matching similarity. In this work, we propose a novel Transformer-based network that interleaves both forms of aggregations in a way that exploits their complementary information. Specifically, we design a self-attention layer that leverages the descriptor to disambiguate the noisy cost volume and that also utilizes the cost volume to aggregate features in a manner that promotes accurate matching. A subsequent cross-attention layer performs further aggregation conditioned on the descriptors of both images and aided by the aggregated outputs of earlier layers. We further boost the performance with hierarchical processing, in which coarser level aggregations guide those at finer levels. We evaluate the effectiveness of the proposed method on dense matching tasks and achieve state-of-the-art performance on all the major benchmarks. Extensive ablation studies are also provided to validate our design choices.