 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIDNet: LiDAR Point Cloud Semantic Segmentation with Fully Interpolation Decoding
Paper and Code


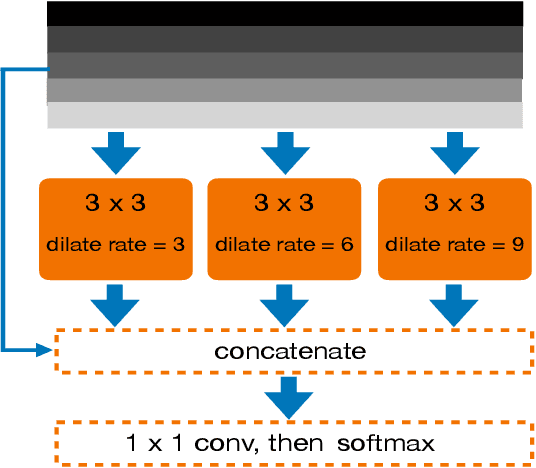

Projecting the point cloud on the 2D spherical range image transforms the LiDAR semantic segmentation to a 2D segmentation task on the range image. However, the LiDAR range image is still naturally different from the regular 2D RGB image; for example, each position on the range image encodes the unique geometry information. In this paper, we propose a new projection-based LiDAR semantic segmentation pipeline that consists of a novel network structure and an efficient post-processing step. In our network structure, we design a FID (fully interpolation decoding) module that directly upsamples the multi-resolution feature maps using bilinear interpolation. Inspired by the 3D distance interpolation used in PointNet++, we argue this FID module is a 2D version distance interpolation on $(\theta, \phi)$ space. As a parameter-free decoding module, the FID largely reduces the model complexity by maintaining good performance. Besides the network structure, we empirically find that our model predictions have clear boundaries between different semantic classes. This makes us rethink whether the widely used K-nearest-neighbor post-processing is still necessary for our pipeline. Then, we realize the many-to-one mapping causes the blurring effect that some points are mapped into the same pixel and share the same label. Therefore, we propose to process those occluded points by assigning the nearest predicted label to them. This NLA (nearest label assignment) post-processing step shows a better performance than KNN with faster inference speed in the ablation study. On the SemanticKITTI dataset, our pipeline achieves the best performance among all projection-based methods with $64 \times 2048$ resolution and all point-wise solutions. With a ResNet-34 as the backbone, both the training and testing of our model can be finished on a single RTX 2080 Ti with 11G memory. The code is released.