 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Visual Attention Learning for Vehicle Re-Identification
Paper and Code


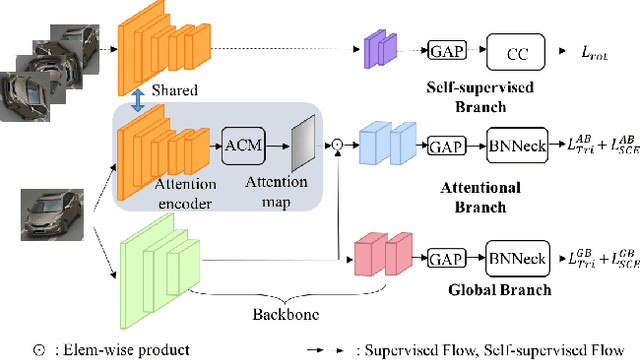
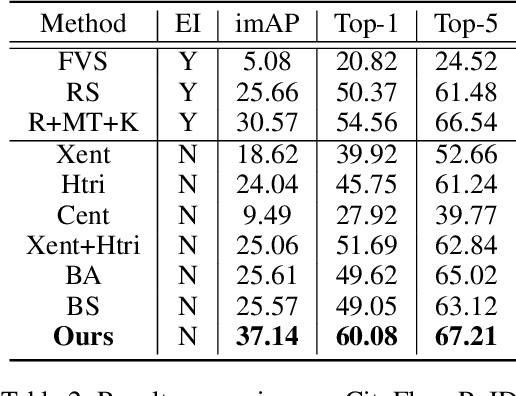
Visual attention learning (VAL) aims to produce a confidence map as weights to detect discriminative features in each image for certain task such as vehicle re-identification (ReID) where the same vehicle instance needs to be identified across different cameras. In contrast to the literature, in this paper we propose utilizing self-supervised learning to regularize VAL to improving the performance for vehicle ReID. Mathematically using lifting we can factorize the two functions of VAL and self-supervised regularization through another shared function. We implement such factorization using a deep learning framework consisting of three branches: (1) a global branch as backbone for image feature extraction, (2) an attentional branch for producing attention masks, and (3) a self-supervised branch for regularizing the attention learning. Our network design naturally leads to an end-to-end multi-task joint optimization. We conduct comprehensive experiments on three benchmark datasets for vehicle ReID, i.e., VeRi-776, CityFlow-ReID, and VehicleID. We demonstrate the state-of-the-art (SOTA) performance of our approach with the capability of capturing informative vehicle parts with no corresponding manual labels. We also demonstrate the good generalization of our approach in other ReID tasks such as person ReID and multi-target multi-camera tracking.