 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Imbalanced Regression via Hierarchical Classification Adjustment
Oct 26, 2023Regression tasks in computer vision, such as age estimation or counting, are often formulated into classification by quantizing the target space into classes. Yet real-world data is often imbalanced -- the majority of training samples lie in a head range of target values, while a minority of samples span a usually larger tail range. By selecting the class quantization, one can adjust imbalanced regression targets into balanced classification outputs, though there are trade-offs in balancing classification accuracy and quantization error. To improve regression performance over the entire range of data, we propose to construct hierarchical classifiers for solving imbalanced regression tasks. The fine-grained classifiers limit the quantization error while being modulated by the coarse predictions to ensure high accuracy. Standard hierarchical classification approaches, however, when applied to the regression problem, fail to ensure that predicted ranges remain consistent across the hierarchy. As such, we propose a range-preserving distillation process that can effectively learn a single classifier from the set of hierarchical classifiers. Our novel hierarchical classification adjustment (HCA) for imbalanced regression shows superior results on three diverse tasks: age estimation, crowd counting and depth estimation. We will release the source code upon acceptance.
Discrete-Constrained Regression for Local Counting Models
Jul 20, 2022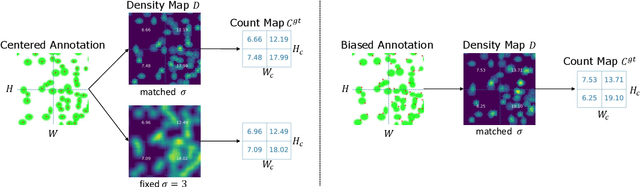
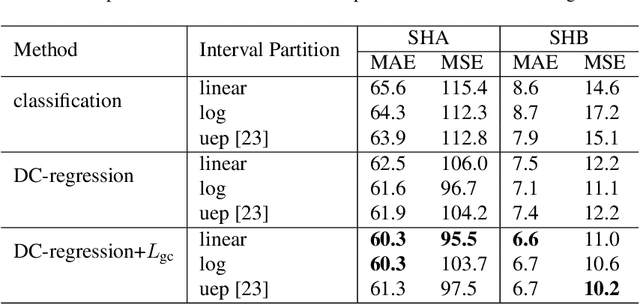
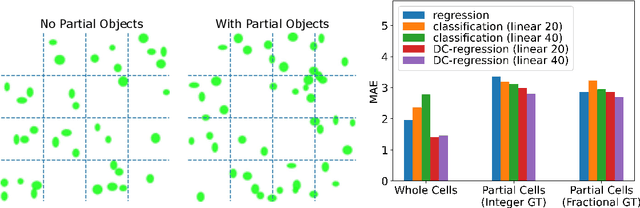
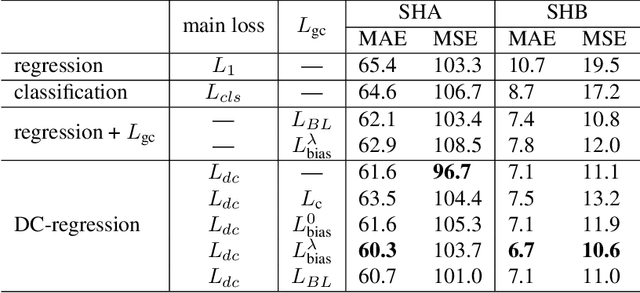
Local counts, or the number of objects in a local area, is a continuous value by nature. Yet recent state-of-the-art methods show that formulating counting as a classification task performs better than regression. Through a series of experiments on carefully controlled synthetic data, we show that this counter-intuitive result is caused by imprecise ground truth local counts. Factors such as biased dot annotations and incorrectly matched Gaussian kernels used to generate ground truth counts introduce deviations from the true local counts. Standard continuous regression is highly sensitive to these errors, explaining the performance gap between classification and regression. To mitigate the sensitivity, we loosen the regression formulation from a continuous scale to a discrete ordering and propose a novel discrete-constrained (DC) regression. Applied to crowd counting, DC-regression is more accurate than both classification and standard regression on three public benchmarks. A similar advantage also holds for the age estimation task, verifying the overall effectiveness of DC-regression.
Weighing Counts: Sequential Crowd Counting by Reinforcement Learning
Jul 16, 2020
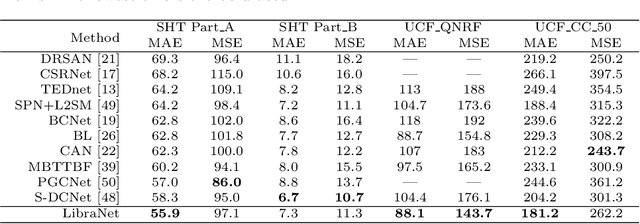
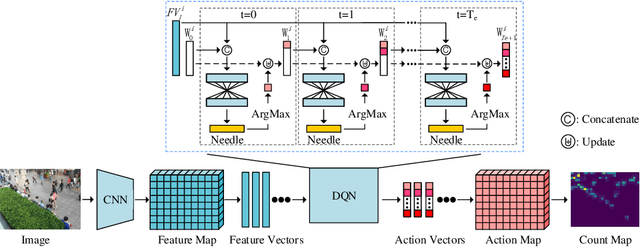
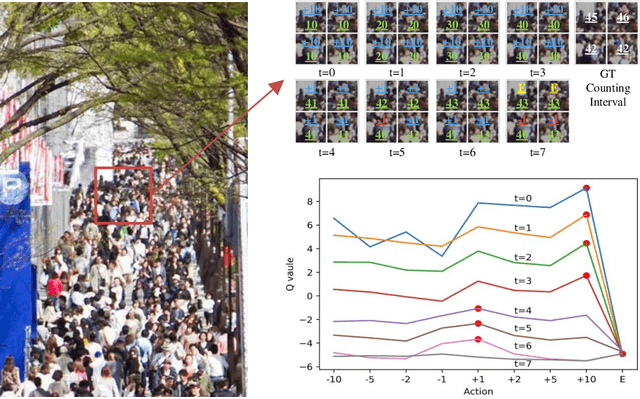
We formulate counting as a sequential decision problem and present a novel crowd counting model solvable by deep reinforcement learning. In contrast to existing counting models that directly output count values, we divide one-step estimation into a sequence of much easier and more tractable sub-decision problems. Such sequential decision nature corresponds exactly to a physical process in reality scale weighing. Inspired by scale weighing, we propose a novel 'counting scale' termed LibraNet where the count value is analogized by weight. By virtually placing a crowd image on one side of a scale, LibraNet (agent) sequentially learns to place appropriate weights on the other side to match the crowd count. At each step, LibraNet chooses one weight (action) from the weight box (the pre-defined action pool) according to the current crowd image features and weights placed on the scale pan (state). LibraNet is required to learn to balance the scale according to the feedback of the needle (Q values). We show that LibraNet exactly implements scale weighing by visualizing the decision process how LibraNet chooses actions. Extensive experiments demonstrate the effectiveness of our design choices and report state-of-the-art results on a few crowd counting benchmarks. We also demonstrate good cross-dataset generalization of LibraNet. Code and models are made available at: https://git.io/libranet
From Open Set to Closed Set: Supervised Spatial Divide-and-Conquer for Object Counting
Jan 07, 2020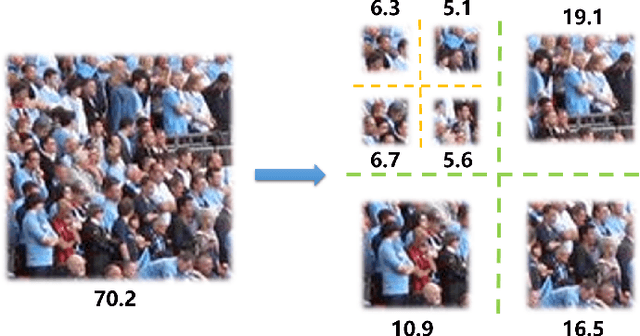

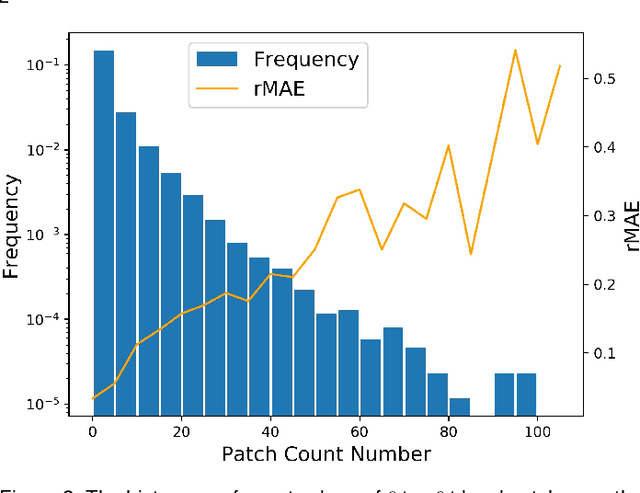
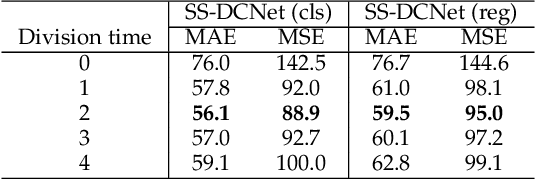
Visual counting, a task that aims to estimate the number of objects from an image/video, is an open-set problem by nature, i.e., the number of population can vary in [0, inf) in theory. However, collected data and labeled instances are limited in reality, which means that only a small closed set is observed. Existing methods typically model this task in a regression manner, while they are prone to suffer from an unseen scene with counts out of the scope of the closed set. In fact, counting has an interesting and exclusive property---spatially decomposable. A dense region can always be divided until sub-region counts are within the previously observed closed set. We therefore introduce the idea of spatial divide-and-conquer (S-DC) that transforms open-set counting into a closed-set problem. This idea is implemented by a novel Supervised Spatial Divide-and-Conquer Network (SS-DCNet). Thus, SS-DCNet can only learn from a closed set but generalize well to open-set scenarios via S-DC. SS-DCNet is also efficient. To avoid repeatedly computing sub-region convolutional features, S-DC is executed on the feature map instead of on the input image. We provide theoretical analyses as well as a controlled experiment on toy data, demonstrating why closed-set modeling makes sense. Extensive experiments show that SS-DCNet achieves the state-of-the-art performance. Code and models are available at: https://tinyurl.com/SS-DCNet.
From Open Set to Closed Set: Counting Objects by Spatial Divide-and-Conquer
Aug 15, 2019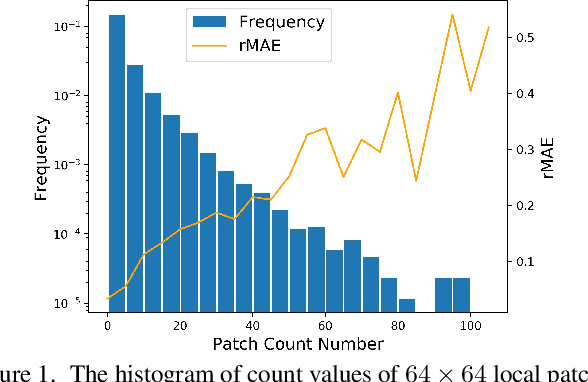

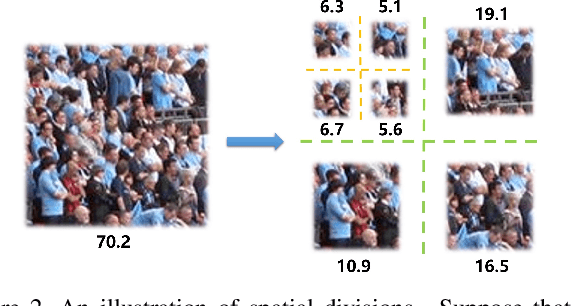

Visual counting, a task that predicts the number of objects from an image/video, is an open-set problem by nature, i.e., the number of population can vary in $[0,+\infty)$ in theory. However, the collected images and labeled count values are limited in reality, which means only a small closed set is observed. Existing methods typically model this task in a regression manner, while they are likely to suffer from an unseen scene with counts out of the scope of the closed set. In fact, counting is decomposable. A dense region can always be divided until sub-region counts are within the previously observed closed set. Inspired by this idea, we propose a simple but effective approach, Spatial Divide-and- Conquer Network (S-DCNet). S-DCNet only learns from a closed set but can generalize well to open-set scenarios via S-DC. S-DCNet is also efficient. To avoid repeatedly computing sub-region convolutional features, S-DC is executed on the feature map instead of on the input image. S-DCNet achieves the state-of-the-art performance on three crowd counting datasets (ShanghaiTech, UCF_CC_50 and UCF-QNRF), a vehicle counting dataset (TRANCOS) and a plant counting dataset (MTC). Compared to the previous best methods, S-DCNet brings a 20.2% relative improvement on the ShanghaiTech Part B, 20.9% on the UCF-QNRF, 22.5% on the TRANCOS and 15.1% on the MTC. Code has been made available at: https://github. com/xhp-hust-2018-2011/S-DCNet.