 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing the Reasoning Ability of Multimodal Large Language Models via Mixed Preference Optimization
Paper and Code
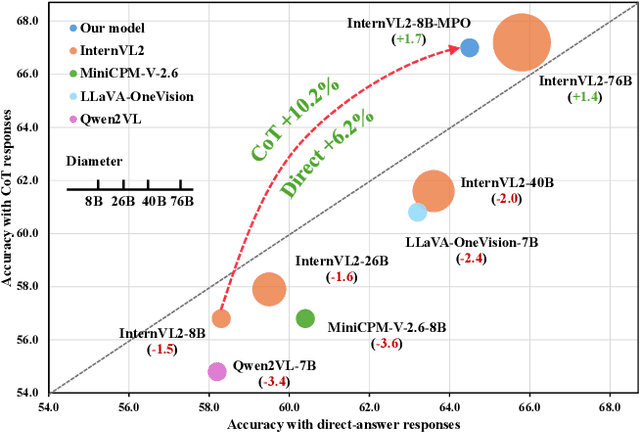

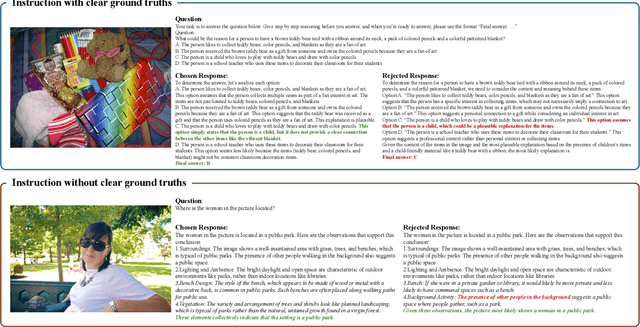
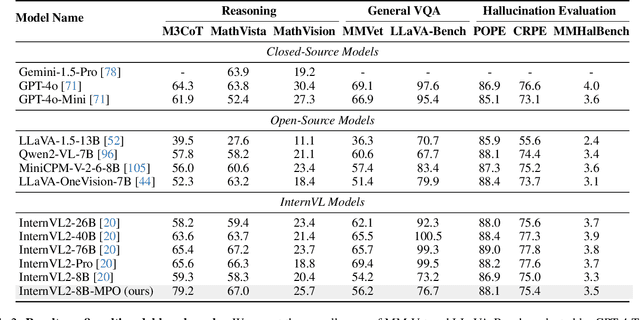
Existing open-source multimodal large language models (MLLMs) generally follow a training process involving pre-training and supervised fine-tuning. However, these models suffer from distribution shifts, which limit their multimodal reasoning, particularly in the Chain-of-Thought (CoT) performance. To address this, we introduce a preference optimization (PO) process to enhance the multimodal reasoning capabilities of MLLMs. Specifically, (1) on the data side, we design an automated preference data construction pipeline to create MMPR, a high-quality, large-scale multimodal reasoning preference dataset. and (2) on the model side, we explore integrating PO with MLLMs, developing a simple yet effective method, termed Mixed Preference Optimization (MPO), which boosts multimodal CoT performance. Our approach demonstrates improved performance across multiple benchmarks, particularly in multimodal reasoning tasks. Notably, our model, InternVL2-8B-MPO, achieves an accuracy of 67.0 on MathVista, outperforming InternVL2-8B by 8.7 points and achieving performance comparable to the 10x larger InternVL2-76B. We hope this study could inspire further advancements in MLLMs. Code, data, and model shall be publicly released.