 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiCrafter: High-Fidelity Multi-Subject Generation via Spatially Disentangled Attention and Identity-Aware Reinforcement Learning
Sep 26, 2025Multi-subject image generation aims to synthesize user-provided subjects in a single image while preserving subject fidelity, ensuring prompt consistency, and aligning with human aesthetic preferences. However, existing methods, particularly those built on the In-Context-Learning paradigm, are limited by their reliance on simple reconstruction-based objectives, leading to both severe attribute leakage that compromises subject fidelity and failing to align with nuanced human preferences. To address this, we propose MultiCrafter, a framework that ensures high-fidelity, preference-aligned generation. First, we find that the root cause of attribute leakage is a significant entanglement of attention between different subjects during the generation process. Therefore, we introduce explicit positional supervision to explicitly separate attention regions for each subject, effectively mitigating attribute leakage. To enable the model to accurately plan the attention region of different subjects in diverse scenarios, we employ a Mixture-of-Experts architecture to enhance the model's capacity, allowing different experts to focus on different scenarios. Finally, we design a novel online reinforcement learning framework to align the model with human preferences, featuring a scoring mechanism to accurately assess multi-subject fidelity and a more stable training strategy tailored for the MoE architecture. Experiments validate that our framework significantly improves subject fidelity while aligning with human preferences better.
Dynamic-DINO: Fine-Grained Mixture of Experts Tuning for Real-time Open-Vocabulary Object Detection
Jul 23, 2025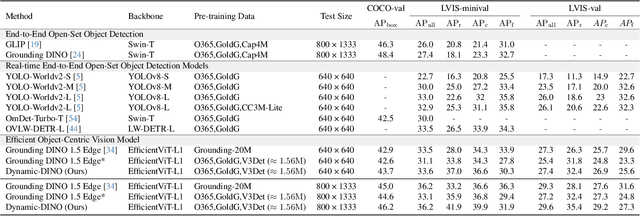
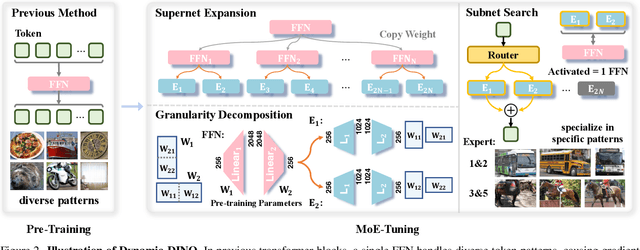

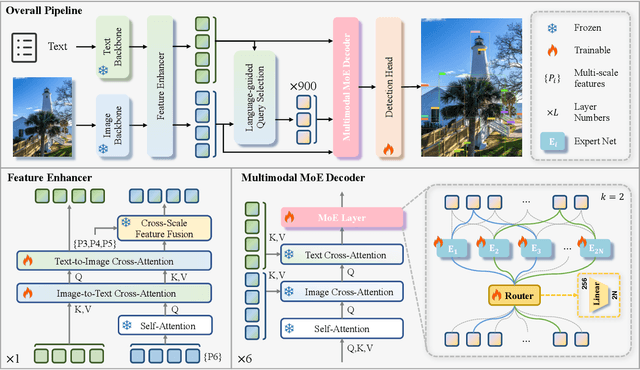
The Mixture of Experts (MoE) architecture has excelled in Large Vision-Language Models (LVLMs), yet its potential in real-time open-vocabulary object detectors, which also leverage large-scale vision-language datasets but smaller models, remains unexplored. This work investigates this domain, revealing intriguing insights. In the shallow layers, experts tend to cooperate with diverse peers to expand the search space. While in the deeper layers, fixed collaborative structures emerge, where each expert maintains 2-3 fixed partners and distinct expert combinations are specialized in processing specific patterns. Concretely, we propose Dynamic-DINO, which extends Grounding DINO 1.5 Edge from a dense model to a dynamic inference framework via an efficient MoE-Tuning strategy. Additionally, we design a granularity decomposition mechanism to decompose the Feed-Forward Network (FFN) of base model into multiple smaller expert networks, expanding the subnet search space. To prevent performance degradation at the start of fine-tuning, we further propose a pre-trained weight allocation strategy for the experts, coupled with a specific router initialization. During inference, only the input-relevant experts are activated to form a compact subnet. Experiments show that, pretrained with merely 1.56M open-source data, Dynamic-DINO outperforms Grounding DINO 1.5 Edge, pretrained on the private Grounding20M dataset.
CamI2V: Camera-Controlled Image-to-Video Diffusion Model
Oct 21, 2024



Recently, camera pose, as a user-friendly and physics-related condition, has been introduced into text-to-video diffusion model for camera control. However, existing methods simply inject camera conditions through a side input. These approaches neglect the inherent physical knowledge of camera pose, resulting in imprecise camera control, inconsistencies, and also poor interpretability. In this paper, we emphasize the necessity of integrating explicit physical constraints into model design. Epipolar attention is proposed for modeling all cross-frame relationships from a novel perspective of noised condition. This ensures that features are aggregated from corresponding epipolar lines in all noised frames, overcoming the limitations of current attention mechanisms in tracking displaced features across frames, especially when features move significantly with the camera and become obscured by noise. Additionally, we introduce register tokens to handle cases without intersections between frames, commonly caused by rapid camera movements, dynamic objects, or occlusions. To support image-to-video, we propose the multiple guidance scale to allow for precise control for image, text, and camera, respectively. Furthermore, we establish a more robust and reproducible evaluation pipeline to solve the inaccuracy and instability of existing camera control measurement. We achieve a 25.5\% improvement in camera controllability on RealEstate10K while maintaining strong generalization to out-of-domain images. Only 24GB and 12GB are required for training and inference, respectively. We plan to release checkpoints, along with training and evaluation codes. Dynamic videos are best viewed at \url{https://zgctroy.github.io/CamI2V}.
BEVSpread: Spread Voxel Pooling for Bird's-Eye-View Representation in Vision-based Roadside 3D Object Detection
Jun 13, 2024



Vision-based roadside 3D object detection has attracted rising attention in autonomous driving domain, since it encompasses inherent advantages in reducing blind spots and expanding perception range. While previous work mainly focuses on accurately estimating depth or height for 2D-to-3D mapping, ignoring the position approximation error in the voxel pooling process. Inspired by this insight, we propose a novel voxel pooling strategy to reduce such error, dubbed BEVSpread. Specifically, instead of bringing the image features contained in a frustum point to a single BEV grid, BEVSpread considers each frustum point as a source and spreads the image features to the surrounding BEV grids with adaptive weights. To achieve superior propagation performance, a specific weight function is designed to dynamically control the decay speed of the weights according to distance and depth. Aided by customized CUDA parallel acceleration, BEVSpread achieves comparable inference time as the original voxel pooling. Extensive experiments on two large-scale roadside benchmarks demonstrate that, as a plug-in, BEVSpread can significantly improve the performance of existing frustum-based BEV methods by a large margin of (1.12, 5.26, 3.01) AP in vehicle, pedestrian and cyclist.