 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApple Intelligence Foundation Language Models
Jul 29, 2024



We present foundation language models developed to power Apple Intelligence features, including a ~3 billion parameter model designed to run efficiently on devices and a large server-based language model designed for Private Cloud Compute. These models are designed to perform a wide range of tasks efficiently, accurately, and responsibly. This report describes the model architecture, the data used to train the model, the training process, how the models are optimized for inference, and the evaluation results. We highlight our focus on Responsible AI and how the principles are applied throughout the model development.
TRACT: Denoising Diffusion Models with Transitive Closure Time-Distillation
Mar 07, 2023



Denoising Diffusion models have demonstrated their proficiency for generative sampling. However, generating good samples often requires many iterations. Consequently, techniques such as binary time-distillation (BTD) have been proposed to reduce the number of network calls for a fixed architecture. In this paper, we introduce TRAnsitive Closure Time-distillation (TRACT), a new method that extends BTD. For single step diffusion,TRACT improves FID by up to 2.4x on the same architecture, and achieves new single-step Denoising Diffusion Implicit Models (DDIM) state-of-the-art FID (7.4 for ImageNet64, 3.8 for CIFAR10). Finally we tease apart the method through extended ablations. The PyTorch implementation will be released soon.
Deep Connectomics Networks: Neural Network Architectures Inspired by Neuronal Networks
Dec 19, 2019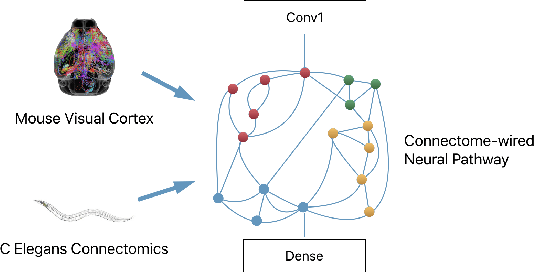
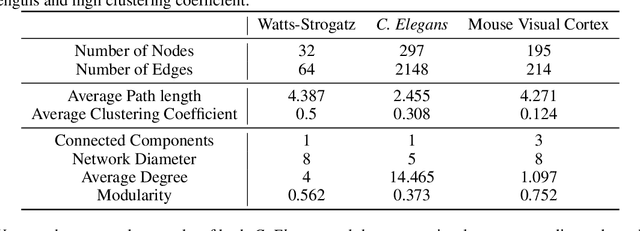
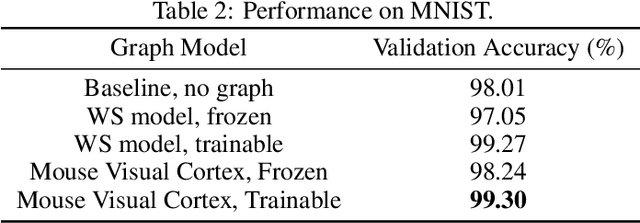
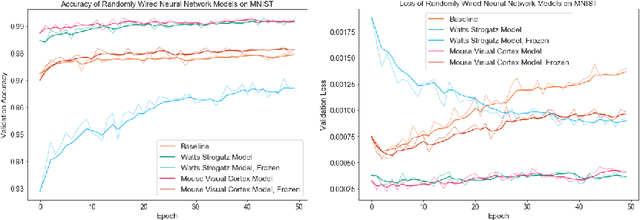
The interplay between inter-neuronal network topology and cognition has been studied deeply by connectomics researchers and network scientists, which is crucial towards understanding the remarkable efficacy of biological neural networks. Curiously, the deep learning revolution that revived neural networks has not paid much attention to topological aspects. The architectures of deep neural networks (DNNs) do not resemble their biological counterparts in the topological sense. We bridge this gap by presenting initial results of Deep Connectomics Networks (DCNs) as DNNs with topologies inspired by real-world neuronal networks. We show high classification accuracy obtained by DCNs whose architecture was inspired by the biological neuronal networks of C. Elegans and the mouse visual cortex.
Grassmannian Packings in Neural Networks: Learning with Maximal Subspace Packings for Diversity and Anti-Sparsity
Nov 18, 2019

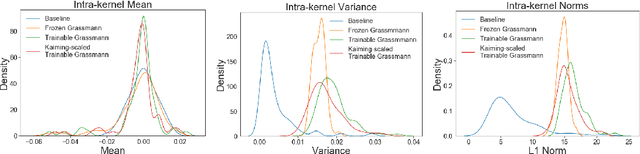
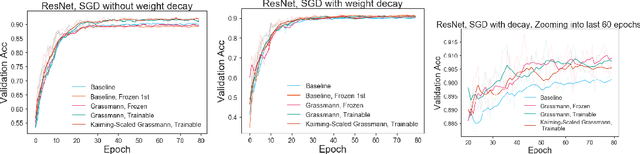
Kernel sparsity ("dying ReLUs") and lack of diversity are commonly observed in CNN kernels, which decreases model capacity. Drawing inspiration from information theory and wireless communications, we demonstrate the intersection of coding theory and deep learning through the Grassmannian subspace packing problem in CNNs. We propose Grassmannian packings for initial kernel layers to be initialized maximally far apart based on chordal or Fubini-Study distance. Convolutional kernels initialized with Grassmannian packings exhibit diverse features and obtain diverse representations. We show that Grassmannian packings, especially in the initial layers, address kernel sparsity and encourage diversity, while improving classification accuracy across shallow and deep CNNs with better convergence rates.
Understanding Adversarial Robustness Through Loss Landscape Geometries
Jul 22, 2019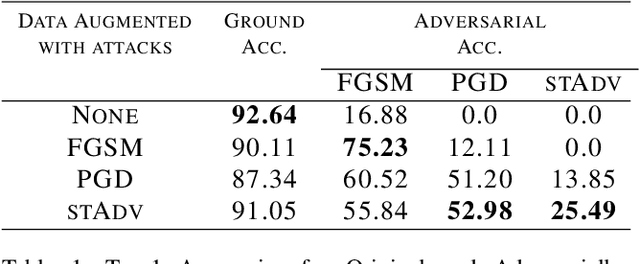
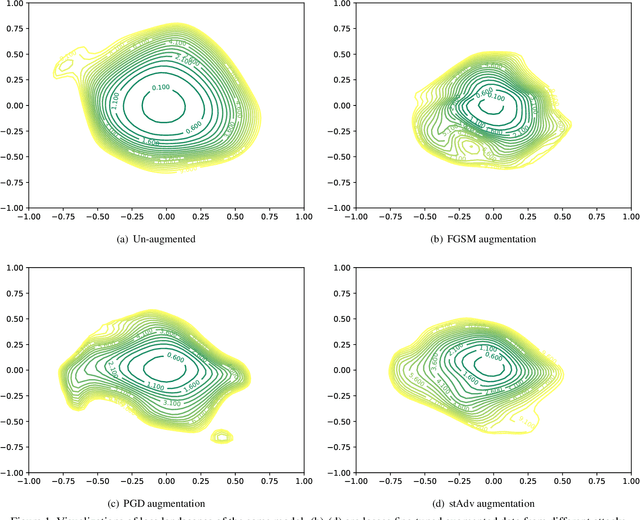

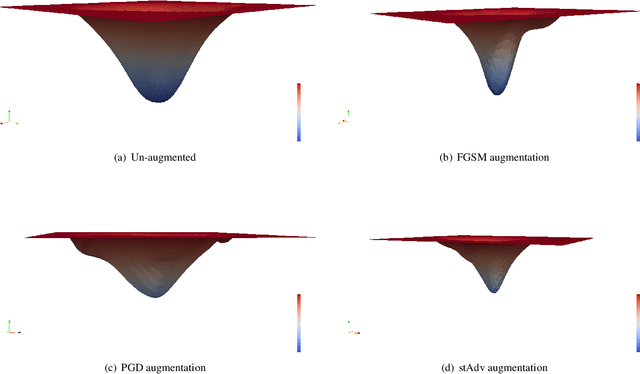
The pursuit of explaining and improving generalization in deep learning has elicited efforts both in regularization techniques as well as visualization techniques of the loss surface geometry. The latter is related to the intuition prevalent in the community that flatter local optima leads to lower generalization error. In this paper, we harness the state-of-the-art "filter normalization" technique of loss-surface visualization to qualitatively understand the consequences of using adversarial training data augmentation as the explicit regularization technique of choice. Much to our surprise, we discover that this oft deployed adversarial augmentation technique does not actually result in "flatter" loss-landscapes, which requires rethinking adversarial training generalization, and the relationship between generalization and loss landscapes geometries.
Covering up bias in CelebA-like datasets with Markov blankets: A post-hoc cure for attribute prior avoidance
Jul 22, 2019

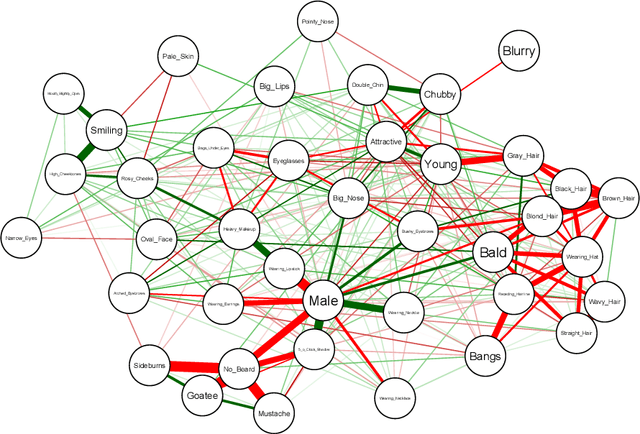
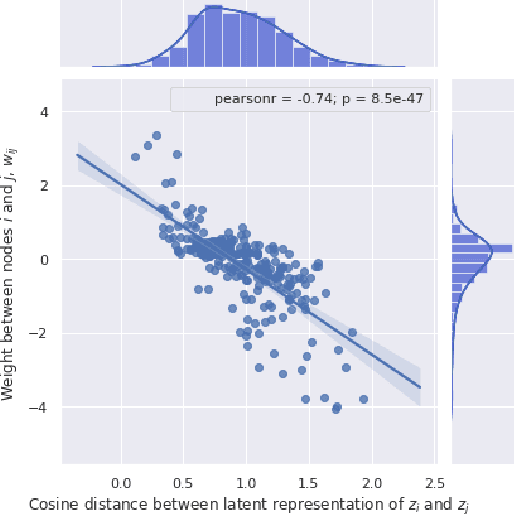
Attribute prior avoidance entails subconscious or willful non-modeling of (meta)attributes that datasets are oft born with, such as the 40 semantic facial attributes associated with the CelebA and CelebA-HQ datasets. The consequences of this infirmity, we discover, are especially stark in state-of-the-art deep generative models learned on these datasets that just model the pixel-space measurements, resulting in an inter-attribute bias-laden latent space. This viscerally manifests itself when we perform face manipulation experiments based on latent vector interpolations. In this paper, we address this and propose a post-hoc solution that utilizes an Ising attribute prior learned in the attribute space and showcase its efficacy via qualitative experiments.
Fonts-2-Handwriting: A Seed-Augment-Train framework for universal digit classification
May 16, 2019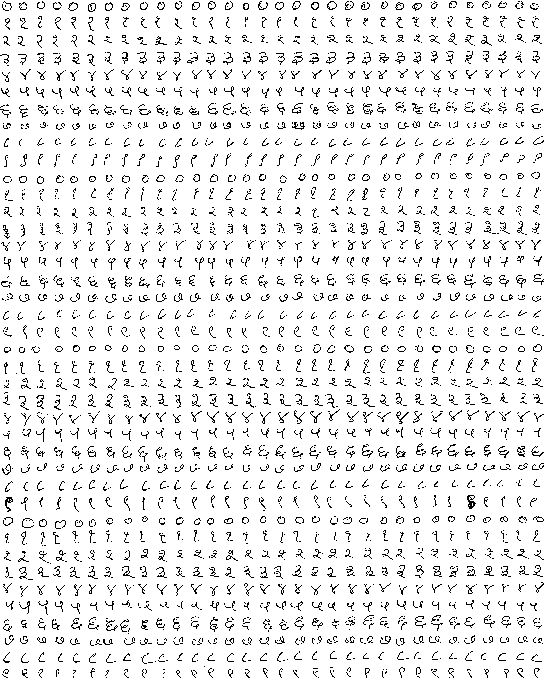

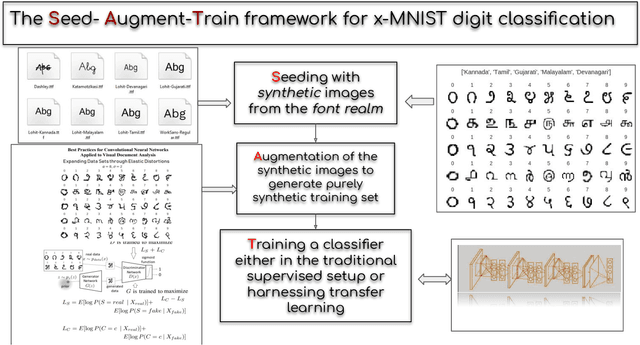

In this paper, we propose a Seed-Augment-Train/Transfer (SAT) framework that contains a synthetic seed image dataset generation procedure for languages with different numeral systems using freely available open font file datasets. This seed dataset of images is then augmented to create a purely synthetic training dataset, which is in turn used to train a deep neural network and test on held-out real world handwritten digits dataset spanning five Indic scripts, Kannada, Tamil, Gujarati, Malayalam, and Devanagari. We showcase the efficacy of this approach both qualitatively, by training a Boundary-seeking GAN (BGAN) that generates realistic digit images in the five languages, and also quantitatively by testing a CNN trained on the synthetic data on the real-world datasets. This establishes not only an interesting nexus between the font-datasets-world and transfer learning but also provides a recipe for universal-digit classification in any script.