 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFonts-2-Handwriting: A Seed-Augment-Train framework for universal digit classification
May 16, 2019

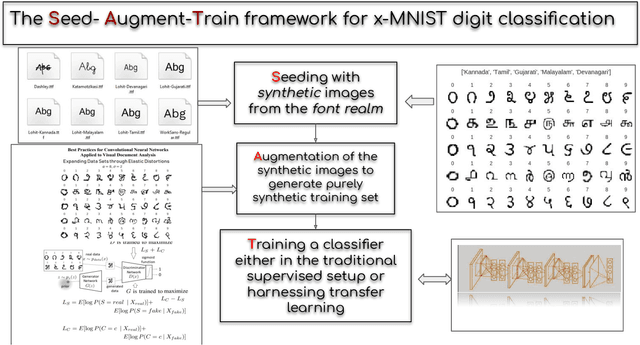

In this paper, we propose a Seed-Augment-Train/Transfer (SAT) framework that contains a synthetic seed image dataset generation procedure for languages with different numeral systems using freely available open font file datasets. This seed dataset of images is then augmented to create a purely synthetic training dataset, which is in turn used to train a deep neural network and test on held-out real world handwritten digits dataset spanning five Indic scripts, Kannada, Tamil, Gujarati, Malayalam, and Devanagari. We showcase the efficacy of this approach both qualitatively, by training a Boundary-seeking GAN (BGAN) that generates realistic digit images in the five languages, and also quantitatively by testing a CNN trained on the synthetic data on the real-world datasets. This establishes not only an interesting nexus between the font-datasets-world and transfer learning but also provides a recipe for universal-digit classification in any script.