 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRotation-Invariant Gait Identification with Quaternion Convolutional Neural Networks
Aug 04, 2020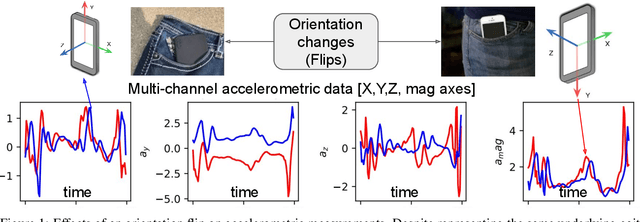
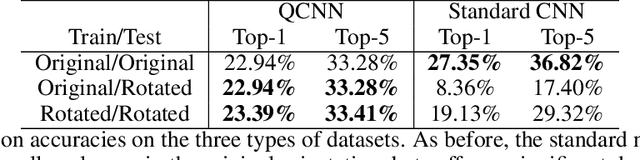
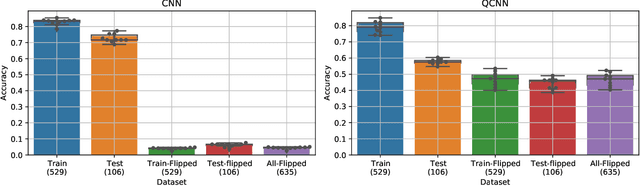
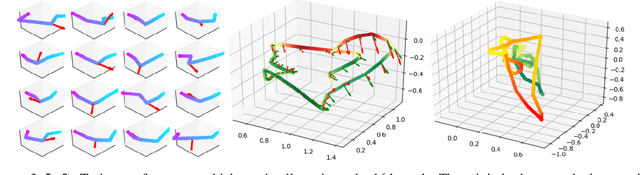
A desireable property of accelerometric gait-based identification systems is robustness to new device orientations presented by users during testing but unseen during the training phase. However, traditional Convolutional neural networks (CNNs) used in these systems compensate poorly for such transformations. In this paper, we target this problem by introducing Quaternion CNN, a network architecture which is intrinsically layer-wise equivariant and globally invariant under 3D rotations of an array of input vectors. We show empirically that this network indeed significantly outperforms a traditional CNN in a multi-user rotation-invariant gait classification setting .Lastly, we demonstrate how the kernels learned by this QCNN can also be visualized as basis-independent but origin- and chirality-dependent trajectory fragments in the euclidean space, thus yielding a novel mode of feature visualization and extraction.
Understanding Adversarial Robustness Through Loss Landscape Geometries
Jul 22, 2019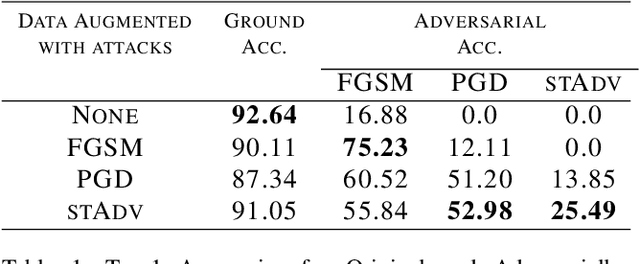
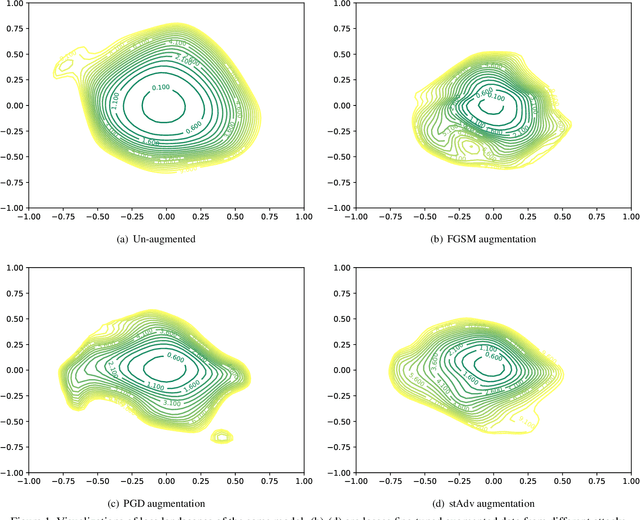

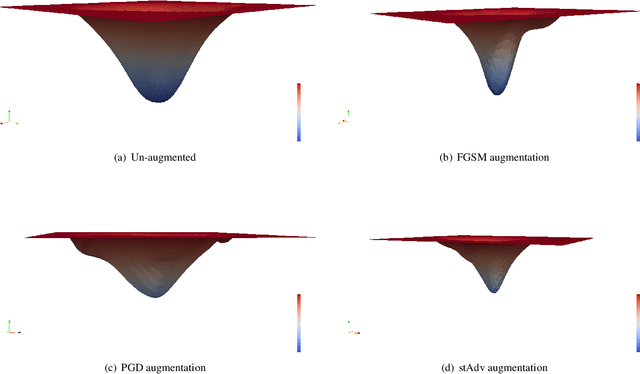
The pursuit of explaining and improving generalization in deep learning has elicited efforts both in regularization techniques as well as visualization techniques of the loss surface geometry. The latter is related to the intuition prevalent in the community that flatter local optima leads to lower generalization error. In this paper, we harness the state-of-the-art "filter normalization" technique of loss-surface visualization to qualitatively understand the consequences of using adversarial training data augmentation as the explicit regularization technique of choice. Much to our surprise, we discover that this oft deployed adversarial augmentation technique does not actually result in "flatter" loss-landscapes, which requires rethinking adversarial training generalization, and the relationship between generalization and loss landscapes geometries.
Covering up bias in CelebA-like datasets with Markov blankets: A post-hoc cure for attribute prior avoidance
Jul 22, 2019

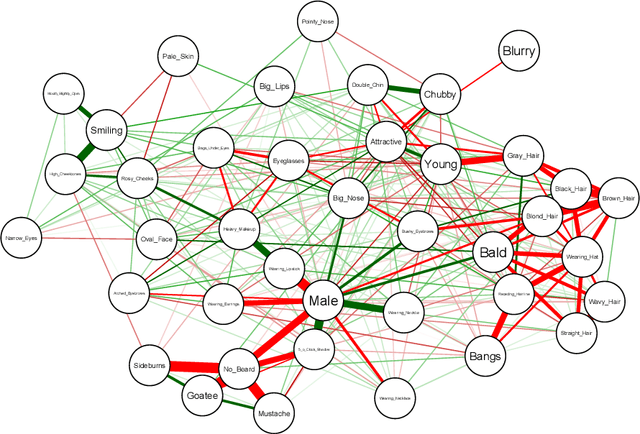
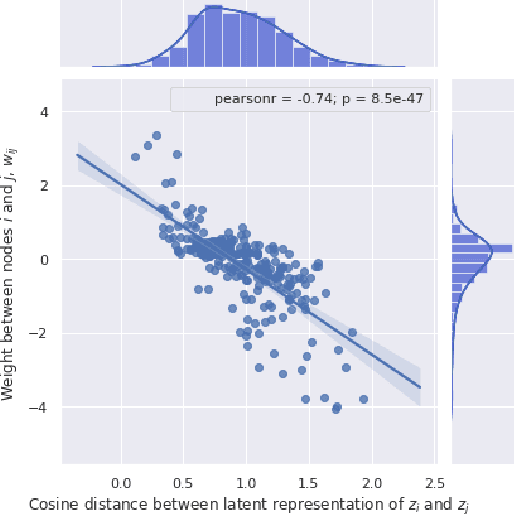
Attribute prior avoidance entails subconscious or willful non-modeling of (meta)attributes that datasets are oft born with, such as the 40 semantic facial attributes associated with the CelebA and CelebA-HQ datasets. The consequences of this infirmity, we discover, are especially stark in state-of-the-art deep generative models learned on these datasets that just model the pixel-space measurements, resulting in an inter-attribute bias-laden latent space. This viscerally manifests itself when we perform face manipulation experiments based on latent vector interpolations. In this paper, we address this and propose a post-hoc solution that utilizes an Ising attribute prior learned in the attribute space and showcase its efficacy via qualitative experiments.
Fonts-2-Handwriting: A Seed-Augment-Train framework for universal digit classification
May 16, 2019

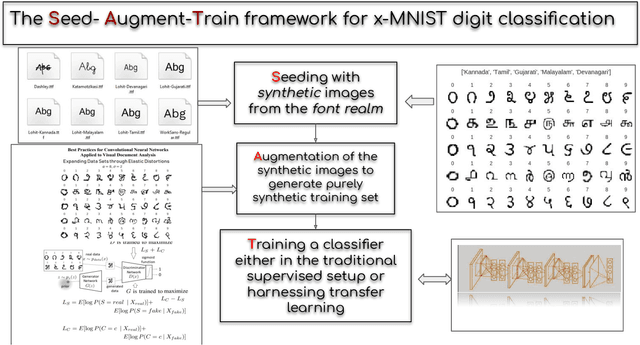

In this paper, we propose a Seed-Augment-Train/Transfer (SAT) framework that contains a synthetic seed image dataset generation procedure for languages with different numeral systems using freely available open font file datasets. This seed dataset of images is then augmented to create a purely synthetic training dataset, which is in turn used to train a deep neural network and test on held-out real world handwritten digits dataset spanning five Indic scripts, Kannada, Tamil, Gujarati, Malayalam, and Devanagari. We showcase the efficacy of this approach both qualitatively, by training a Boundary-seeking GAN (BGAN) that generates realistic digit images in the five languages, and also quantitatively by testing a CNN trained on the synthetic data on the real-world datasets. This establishes not only an interesting nexus between the font-datasets-world and transfer learning but also provides a recipe for universal-digit classification in any script.
On Lyapunov exponents and adversarial perturbation
Feb 20, 2018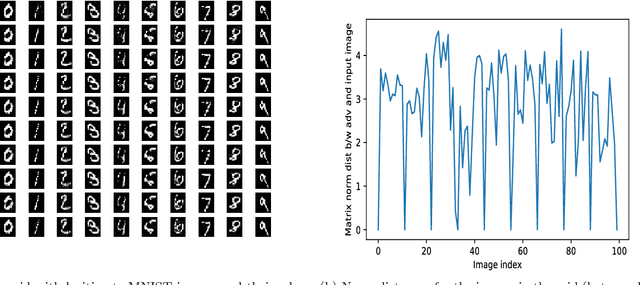
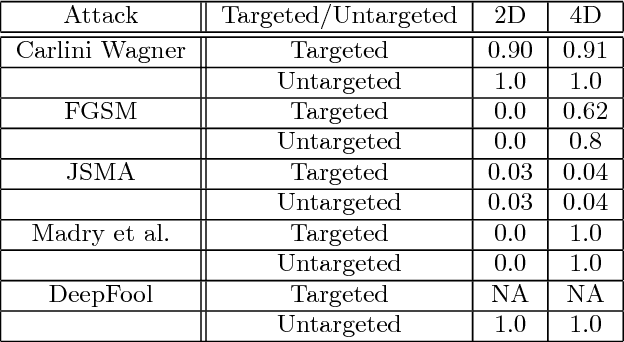

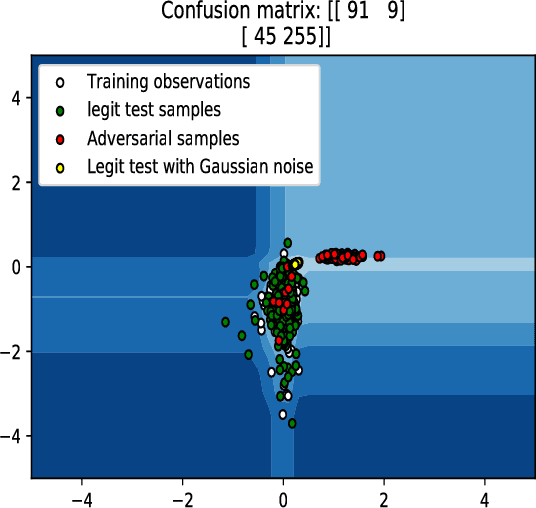
In this paper, we would like to disseminate a serendipitous discovery involving Lyapunov exponents of a 1-D time series and their use in serving as a filtering defense tool against a specific kind of deep adversarial perturbation. To this end, we use the state-of-the-art CleverHans library to generate adversarial perturbations against a standard Convolutional Neural Network (CNN) architecture trained on the MNIST as well as the Fashion-MNIST datasets. We empirically demonstrate how the Lyapunov exponents computed on the flattened 1-D vector representations of the images served as highly discriminative features that could be to pre-classify images as adversarial or legitimate before feeding the image into the CNN for classification. We also explore the issue of possible false-alarms when the input images are noisy in a non-adversarial sense.