 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGameDevBench: Evaluating Agentic Capabilities Through Game Development
Feb 11, 2026Despite rapid progress on coding agents, progress on their multimodal counterparts has lagged behind. A key challenge is the scarcity of evaluation testbeds that combine the complexity of software development with the need for deep multimodal understanding. Game development provides such a testbed as agents must navigate large, dense codebases while manipulating intrinsically multimodal assets such as shaders, sprites, and animations within a visual game scene. We present GameDevBench, the first benchmark for evaluating agents on game development tasks. GameDevBench consists of 132 tasks derived from web and video tutorials. Tasks require significant multimodal understanding and are complex -- the average solution requires over three times the amount of lines of code and file changes compared to prior software development benchmarks. Agents still struggle with game development, with the best agent solving only 54.5% of tasks. We find a strong correlation between perceived task difficulty and multimodal complexity, with success rates dropping from 46.9% on gameplay-oriented tasks to 31.6% on 2D graphics tasks. To improve multimodal capability, we introduce two simple image and video-based feedback mechanisms for agents. Despite their simplicity, these methods consistently improve performance, with the largest change being an increase in Claude Sonnet 4.5's performance from 33.3% to 47.7%. We release GameDevBench publicly to support further research into agentic game development.
Auptimize: Optimal Placement of Spatial Audio Cues for Extended Reality
Aug 18, 2024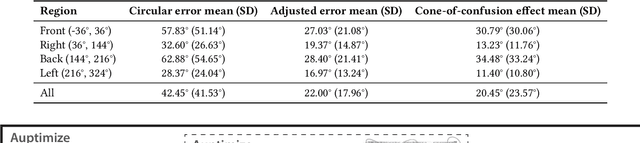
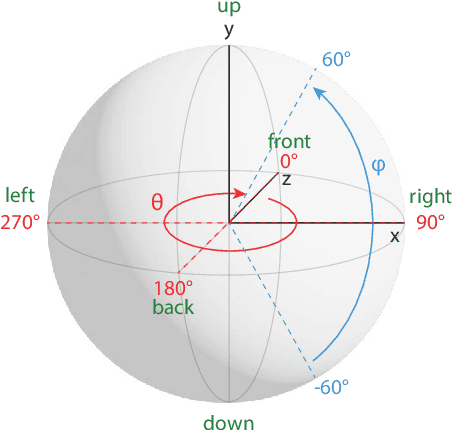
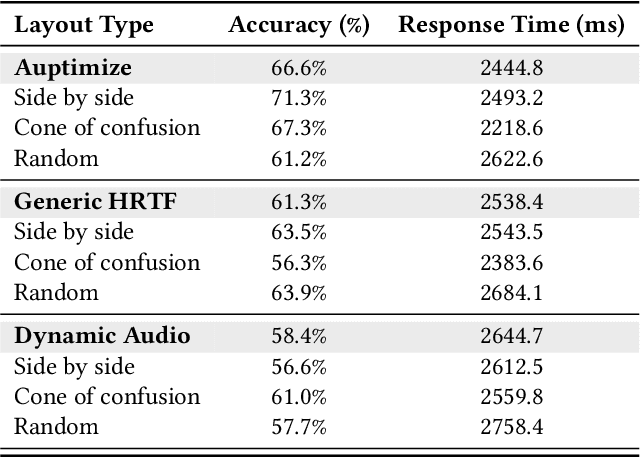
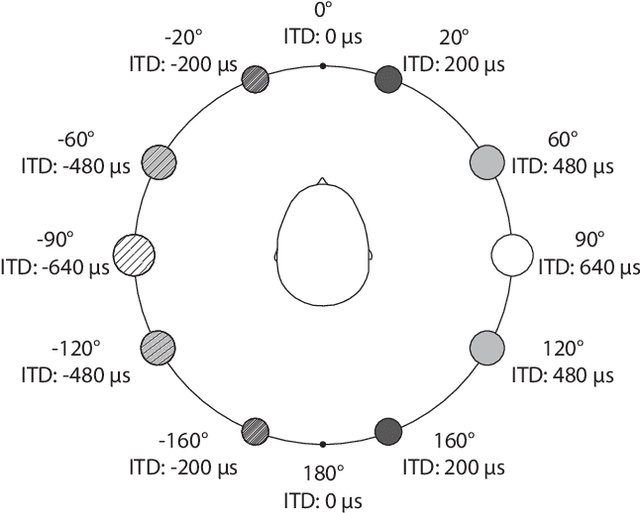
Spatial audio in Extended Reality (XR) provides users with better awareness of where virtual elements are placed, and efficiently guides them to events such as notifications, system alerts from different windows, or approaching avatars. Humans, however, are inaccurate in localizing sound cues, especially with multiple sources due to limitations in human auditory perception such as angular discrimination error and front-back confusion. This decreases the efficiency of XR interfaces because users misidentify from which XR element a sound is coming. To address this, we propose Auptimize, a novel computational approach for placing XR sound sources, which mitigates such localization errors by utilizing the ventriloquist effect. Auptimize disentangles the sound source locations from the visual elements and relocates the sound sources to optimal positions for unambiguous identification of sound cues, avoiding errors due to inter-source proximity and front-back confusion. Our evaluation shows that Auptimize decreases spatial audio-based source identification errors compared to playing sound cues at the paired visual-sound locations. We demonstrate the applicability of Auptimize for diverse spatial audio-based interactive XR scenarios.
STAT: Shrinking Transformers After Training
May 29, 2024



We present STAT: a simple algorithm to prune transformer models without any fine-tuning. STAT eliminates both attention heads and neurons from the network, while preserving accuracy by calculating a correction to the weights of the next layer. Each layer block in the network is compressed using a series of principled matrix factorizations that preserve the network structure. Our entire algorithm takes minutes to compress BERT, and less than three hours to compress models with 7B parameters using a single GPU. Using only several hundred data examples, STAT preserves the output of the network and improves upon existing gradient-free pruning methods. It is even competitive with methods that include significant fine-tuning. We demonstrate our method on both encoder and decoder architectures, including BERT, DistilBERT, and Llama-2 using benchmarks such as GLUE, Squad, WikiText2.
SketchEmbedNet: Learning Novel Concepts by Imitating Drawings
Aug 27, 2020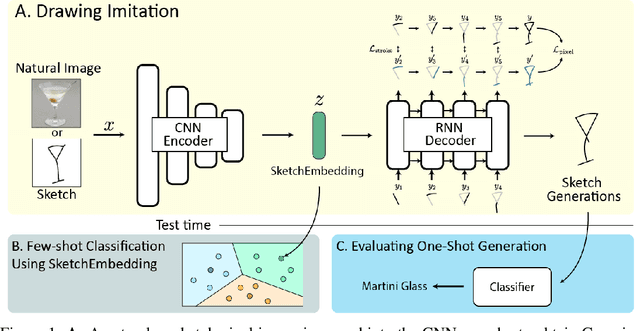
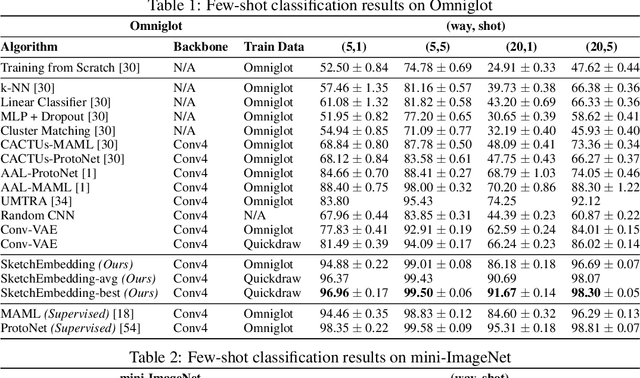

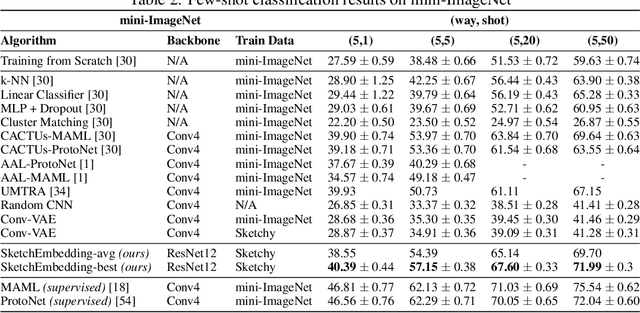
Sketch drawings are an intuitive visual domain that generally preserves semantics. Previous work has shown that recurrent neural networks are capable of producing sketch drawings of a single or few classes at a time. In this work we focus on the representations developed by training a generative model to produce sketches from pixel images across many classes in a sketch domain. We find that the embeddings learned by this sketching model are extremely informative for visual tasks and infer compositional information. We then use them to exceed state-of-the-art performance in unsupervised few-shot classification on the Omniglot and mini-ImageNet benchmarks. We also leverage the generative capacity of our model to produce high quality sketches of novel classes based on just a single example.
Covering up bias in CelebA-like datasets with Markov blankets: A post-hoc cure for attribute prior avoidance
Jul 22, 2019

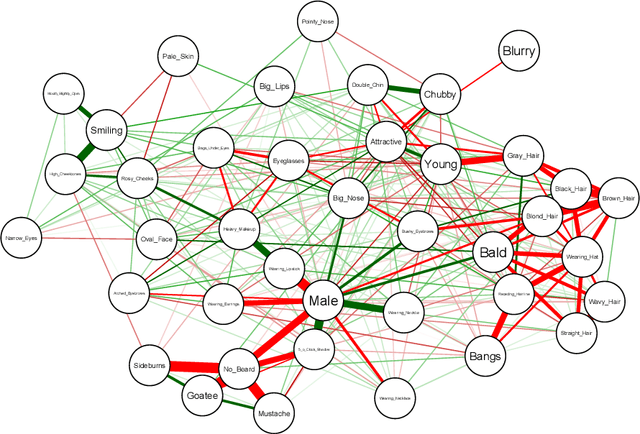
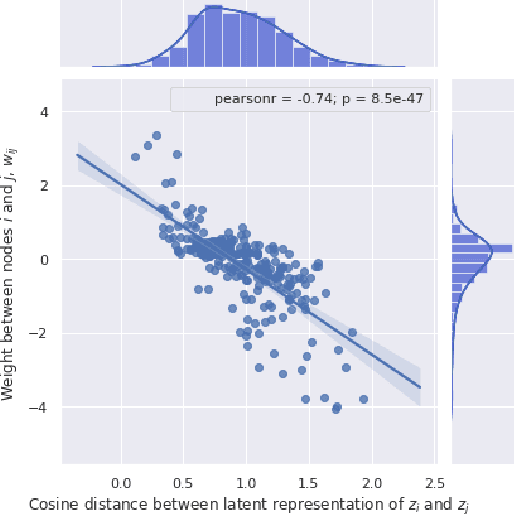
Attribute prior avoidance entails subconscious or willful non-modeling of (meta)attributes that datasets are oft born with, such as the 40 semantic facial attributes associated with the CelebA and CelebA-HQ datasets. The consequences of this infirmity, we discover, are especially stark in state-of-the-art deep generative models learned on these datasets that just model the pixel-space measurements, resulting in an inter-attribute bias-laden latent space. This viscerally manifests itself when we perform face manipulation experiments based on latent vector interpolations. In this paper, we address this and propose a post-hoc solution that utilizes an Ising attribute prior learned in the attribute space and showcase its efficacy via qualitative experiments.