 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShowUI-$π$: Flow-based Generative Models as GUI Dexterous Hands
Dec 31, 2025Building intelligent agents capable of dexterous manipulation is essential for achieving human-like automation in both robotics and digital environments. However, existing GUI agents rely on discrete click predictions (x,y), which prohibits free-form, closed-loop trajectories (e.g. dragging a progress bar) that require continuous, on-the-fly perception and adjustment. In this work, we develop ShowUI-$π$, the first flow-based generative model as GUI dexterous hand, featuring the following designs: (i) Unified Discrete-Continuous Actions, integrating discrete clicks and continuous drags within a shared model, enabling flexible adaptation across diverse interaction modes; (ii) Flow-based Action Generation for drag modeling, which predicts incremental cursor adjustments from continuous visual observations via a lightweight action expert, ensuring smooth and stable trajectories; (iii) Drag Training data and Benchmark, where we manually collect and synthesize 20K drag trajectories across five domains (e.g. PowerPoint, Adobe Premiere Pro), and introduce ScreenDrag, a benchmark with comprehensive online and offline evaluation protocols for assessing GUI agents' drag capabilities. Our experiments show that proprietary GUI agents still struggle on ScreenDrag (e.g. Operator scores 13.27, and the best Gemini-2.5-CUA reaches 22.18). In contrast, ShowUI-$π$ achieves 26.98 with only 450M parameters, underscoring both the difficulty of the task and the effectiveness of our approach. We hope this work advances GUI agents toward human-like dexterous control in digital world. The code is available at https://github.com/showlab/showui-pi.
Computer-Use Agents as Judges for Generative User Interface
Nov 19, 2025Computer-Use Agents (CUA) are becoming increasingly capable of autonomously operating digital environments through Graphical User Interfaces (GUI). Yet, most GUI remain designed primarily for humans--prioritizing aesthetics and usability--forcing agents to adopt human-oriented behaviors that are unnecessary for efficient task execution. At the same time, rapid advances in coding-oriented language models (Coder) have transformed automatic GUI design. This raises a fundamental question: Can CUA as judges to assist Coder for automatic GUI design? To investigate, we introduce AUI-Gym, a benchmark for Automatic GUI development spanning 52 applications across diverse domains. Using language models, we synthesize 1560 tasks that simulate real-world scenarios. To ensure task reliability, we further develop a verifier that programmatically checks whether each task is executable within its environment. Building on this, we propose a Coder-CUA in Collaboration framework: the Coder acts as Designer, generating and revising websites, while the CUA serves as Judge, evaluating functionality and refining designs. Success is measured not by visual appearance, but by task solvability and CUA navigation success rate. To turn CUA feedback into usable guidance, we design a CUA Dashboard that compresses multi-step navigation histories into concise visual summaries, offering interpretable guidance for iterative redesign. By positioning agents as both designers and judges, our framework shifts interface design toward agent-native efficiency and reliability. Our work takes a step toward shifting agents from passive use toward active participation in digital environments. Our code and dataset are available at https://github.com/showlab/AUI.
The Dawn of GUI Agent: A Preliminary Case Study with Claude 3.5 Computer Use
Nov 15, 2024



The recently released model, Claude 3.5 Computer Use, stands out as the first frontier AI model to offer computer use in public beta as a graphical user interface (GUI) agent. As an early beta, its capability in the real-world complex environment remains unknown. In this case study to explore Claude 3.5 Computer Use, we curate and organize a collection of carefully designed tasks spanning a variety of domains and software. Observations from these cases demonstrate Claude 3.5 Computer Use's unprecedented ability in end-to-end language to desktop actions. Along with this study, we provide an out-of-the-box agent framework for deploying API-based GUI automation models with easy implementation. Our case studies aim to showcase a groundwork of capabilities and limitations of Claude 3.5 Computer Use with detailed analyses and bring to the fore questions about planning, action, and critic, which must be considered for future improvement. We hope this preliminary exploration will inspire future research into the GUI agent community. All the test cases in the paper can be tried through the project: https://github.com/showlab/computer_use_ootb.
MS-Net: A Multi-Path Sparse Model for Motion Prediction in Multi-Scenes
Mar 01, 2024



The multi-modality and stochastic characteristics of human behavior make motion prediction a highly challenging task, which is critical for autonomous driving. While deep learning approaches have demonstrated their great potential in this area, it still remains unsolved to establish a connection between multiple driving scenes (e.g., merging, roundabout, intersection) and the design of deep learning models. Current learning-based methods typically use one unified model to predict trajectories in different scenarios, which may result in sub-optimal results for one individual scene. To address this issue, we propose Multi-Scenes Network (aka. MS-Net), which is a multi-path sparse model trained by an evolutionary process. MS-Net selectively activates a subset of its parameters during the inference stage to produce prediction results for each scene. In the training stage, the motion prediction task under differentiated scenes is abstracted as a multi-task learning problem, an evolutionary algorithm is designed to encourage the network search of the optimal parameters for each scene while sharing common knowledge between different scenes. Our experiment results show that with substantially reduced parameters, MS-Net outperforms existing state-of-the-art methods on well-established pedestrian motion prediction datasets, e.g., ETH and UCY, and ranks the 2nd place on the INTERACTION challenge.
TRACT: Denoising Diffusion Models with Transitive Closure Time-Distillation
Mar 07, 2023



Denoising Diffusion models have demonstrated their proficiency for generative sampling. However, generating good samples often requires many iterations. Consequently, techniques such as binary time-distillation (BTD) have been proposed to reduce the number of network calls for a fixed architecture. In this paper, we introduce TRAnsitive Closure Time-distillation (TRACT), a new method that extends BTD. For single step diffusion,TRACT improves FID by up to 2.4x on the same architecture, and achieves new single-step Denoising Diffusion Implicit Models (DDIM) state-of-the-art FID (7.4 for ImageNet64, 3.8 for CIFAR10). Finally we tease apart the method through extended ablations. The PyTorch implementation will be released soon.
A Fast MR Fingerprinting Simulator for Direct Error Estimation and Sequence Optimization
May 25, 2021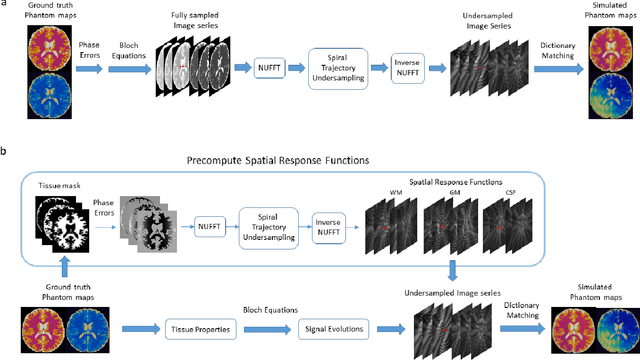
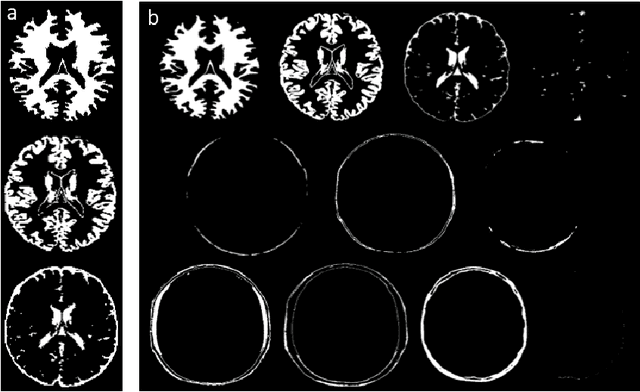
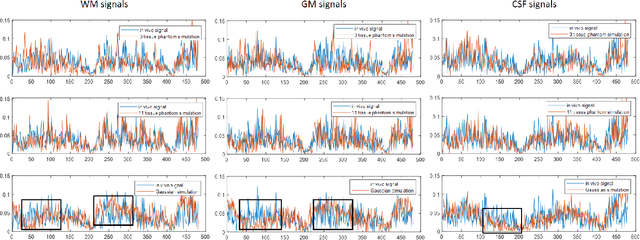

MR Fingerprinting is a novel quantitative MR technique that could simultaneously provide multiple tissue property maps. When optimizing MRF scans, modeling undersampling errors and field imperfections in cost functions will make the optimization results more practical and robust. However, this process is computationally expensive and impractical for sequence optimization algorithms when MRF signal evolutions need to be generated for each optimization iteration. Here, we introduce a fast MRF simulator to simulate aliased images from actual scan scenarios including undersampling and system imperfections, which substantially reduces computational time and allows for direct error estimation and efficient sequence optimization. By constraining the total number of tissues present in a brain phantom, MRF signals from highly undersampled scans can be simulated as the product of the spatial response functions based on sampling patterns and sequence-dependent temporal functions. During optimization, the spatial response function is independent of sequence design and does not need to be recalculated. We evaluate the performance and computational speed of the proposed approach by simulations and in vivo experiments. We also demonstrate the power of applying the simulator in MRF sequence optimization. The simulation results from the proposed method closely approximate the signals and MRF maps from in vivo scans, with 158 times shorter processing time than the conventional simulation method using Non-uniform Fourier transform. Incorporating the proposed simulator in the MRF optimization framework makes direct estimation of undersampling errors during the optimization process feasible, and provide optimized MRF sequences that are robust against undersampling factors and system inhomogeneity.