 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChainReaction! Structured Approach with Causal Chains as Intermediate Representations for Improved and Explainable Causal Video Question Answering
Aug 28, 2025Existing Causal-Why Video Question Answering (VideoQA) models often struggle with higher-order reasoning, relying on opaque, monolithic pipelines that entangle video understanding, causal inference, and answer generation. These black-box approaches offer limited interpretability and tend to depend on shallow heuristics. We propose a novel, modular framework that explicitly decouples causal reasoning from answer generation, introducing natural language causal chains as interpretable intermediate representations. Inspired by human cognitive models, these structured cause-effect sequences bridge low-level video content with high-level causal reasoning, enabling transparent and logically coherent inference. Our two-stage architecture comprises a Causal Chain Extractor (CCE) that generates causal chains from video-question pairs, and a Causal Chain-Driven Answerer (CCDA) that produces answers grounded in these chains. To address the lack of annotated reasoning traces, we introduce a scalable method for generating high-quality causal chains from existing datasets using large language models. We also propose CauCo, a new evaluation metric for causality-oriented captioning. Experiments on three large-scale benchmarks demonstrate that our approach not only outperforms state-of-the-art models, but also yields substantial gains in explainability, user trust, and generalization -- positioning the CCE as a reusable causal reasoning engine across diverse domains. Project page: https://paritoshparmar.github.io/chainreaction/
A Decade of Action Quality Assessment: Largest Systematic Survey of Trends, Challenges, and Future Directions
Feb 05, 2025



Action Quality Assessment (AQA) -- the ability to quantify the quality of human motion, actions, or skill levels and provide feedback -- has far-reaching implications in areas such as low-cost physiotherapy, sports training, and workforce development. As such, it has become a critical field in computer vision & video understanding over the past decade. Significant progress has been made in AQA methodologies, datasets, & applications, yet a pressing need remains for a comprehensive synthesis of this rapidly evolving field. In this paper, we present a thorough survey of the AQA landscape, systematically reviewing over 200 research papers using the preferred reporting items for systematic reviews & meta-analyses (PRISMA) framework. We begin by covering foundational concepts & definitions, then move to general frameworks & performance metrics, & finally discuss the latest advances in methodologies & datasets. This survey provides a detailed analysis of research trends, performance comparisons, challenges, & future directions. Through this work, we aim to offer a valuable resource for both newcomers & experienced researchers, promoting further exploration & progress in AQA. Data are available at https://haoyin116.github.io/Survey_of_AQA/
CausalChaos! Dataset for Comprehensive Causal Action Question Answering Over Longer Causal Chains Grounded in Dynamic Visual Scenes
Apr 01, 2024Causal video question answering (QA) has garnered increasing interest, yet existing datasets often lack depth in causal reasoning analysis. To address this gap, we capitalize on the unique properties of cartoons and construct CausalChaos!, a novel, challenging causal Why-QA dataset built upon the iconic "Tom and Jerry" cartoon series. With thoughtful questions and multi-level answers, our dataset contains much longer causal chains embedded in dynamic interactions and visuals, at the same time principles of animation allows animators to create well-defined, unambiguous causal relationships. These factors allow models to solve more challenging, yet well-defined causal relationships. We also introduce hard negative mining, including CausalConfusion version. While models perform well, there is much room for improvement, especially, on open-ended answers. We identify more advanced/explicit causal relationship modeling and joint modeling of vision and language as the immediate areas for future efforts to focus upon. Along with the other complementary datasets, our new challenging dataset will pave the way for these developments in the field. We will release our dataset, codes, and models to help future efforts in this domain.
Hierarchical NeuroSymbolic Approach for Action Quality Assessment
Mar 20, 2024Action quality assessment (AQA) applies computer vision to quantitatively assess the performance or execution of a human action. Current AQA approaches are end-to-end neural models, which lack transparency and tend to be biased because they are trained on subjective human judgements as ground-truth. To address these issues, we introduce a neuro-symbolic paradigm for AQA, which uses neural networks to abstract interpretable symbols from video data and makes quality assessments by applying rules to those symbols. We take diving as the case study. We found that domain experts prefer our system and find it more informative than purely neural approaches to AQA in diving. Our system also achieves state-of-the-art action recognition and temporal segmentation, and automatically generates a detailed report that breaks the dive down into its elements and provides objective scoring with visual evidence. As verified by a group of domain experts, this report may be used to assist judges in scoring, help train judges, and provide feedback to divers. We will open-source all of our annotated training data and code for ease of reproducibility.
Learning to Visually Connect Actions and their Effects
Jan 19, 2024In this work, we introduce the novel concept of visually Connecting Actions and Their Effects (CATE) in video understanding. CATE can have applications in areas like task planning and learning from demonstration. We propose different CATE-based task formulations, such as action selection and action specification, where video understanding models connect actions and effects at semantic and fine-grained levels. We observe that different formulations produce representations capturing intuitive action properties. We also design various baseline models for action selection and action specification. Despite the intuitive nature of the task, we observe that models struggle, and humans outperform them by a large margin. The study aims to establish a foundation for future efforts, showcasing the flexibility and versatility of connecting actions and effects in video understanding, with the hope of inspiring advanced formulations and models.
Domain Knowledge-Informed Self-Supervised Representations for Workout Form Assessment
Feb 28, 2022
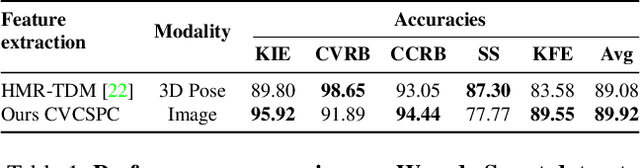


Maintaining proper form while exercising is important for preventing injuries and maximizing muscle mass gains. While fitness apps are becoming popular, they lack the functionality to detect errors in workout form. Detecting such errors naturally requires estimating users' body pose. However, off-the-shelf pose estimators struggle to perform well on the videos recorded in gym scenarios due to factors such as camera angles, occlusion from gym equipment, illumination, and clothing. To aggravate the problem, the errors to be detected in the workouts are very subtle. To that end, we propose to learn exercise-specific representations from unlabeled samples such that a small dataset annotated by experts suffices for supervised error detection. In particular, our domain knowledge-informed self-supervised approaches exploit the harmonic motion of the exercise actions, and capitalize on the large variances in camera angles, clothes, and illumination to learn powerful representations. To facilitate our self-supervised pretraining, and supervised finetuning, we curated a new exercise dataset, Fitness-AQA, comprising of three exercises: BackSquat, BarbellRow, and OverheadPress. It has been annotated by expert trainers for multiple crucial and typically occurring exercise errors. Experimental results show that our self-supervised representations outperform off-the-shelf 2D- and 3D-pose estimators and several other baselines.
Win-Fail Action Recognition
Feb 15, 2021
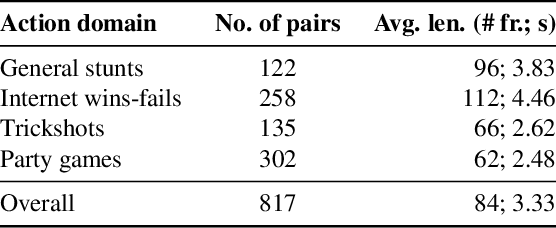

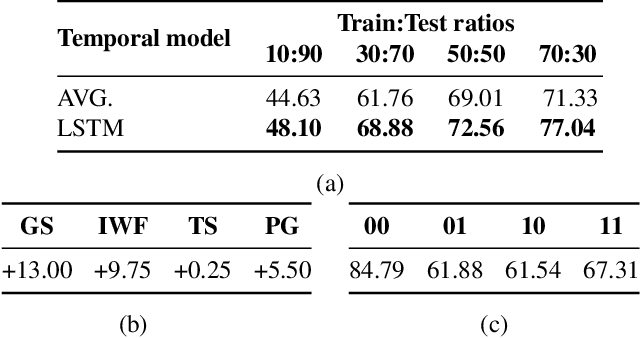
Current video/action understanding systems have demonstrated impressive performance on large recognition tasks. However, they might be limiting themselves to learning to recognize spatiotemporal patterns, rather than attempting to thoroughly understand the actions. To spur progress in the direction of a truer, deeper understanding of videos, we introduce the task of win-fail action recognition -- differentiating between successful and failed attempts at various activities. We introduce a first of its kind paired win-fail action understanding dataset with samples from the following domains: "General Stunts," "Internet Wins-Fails," "Trick Shots," and "Party Games." Unlike existing action recognition datasets, intra-class variation is high making the task challenging, yet feasible. We systematically analyze the characteristics of the win-fail task/dataset with prototypical action recognition networks and a novel video retrieval task. While current action recognition methods work well on our task/dataset, they still leave a large gap to achieve high performance. We hope to motivate more work towards the true understanding of actions/videos. Dataset will be available from https://github.com/ParitoshParmar/Win-Fail-Action-Recognition.
Piano Skills Assessment
Jan 13, 2021
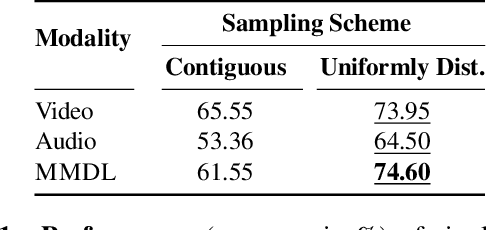
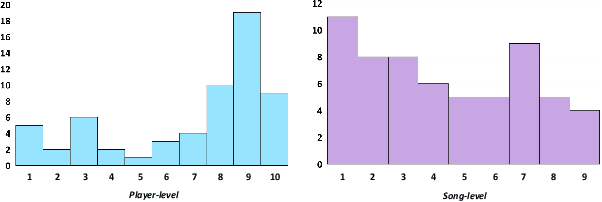

Can a computer determine a piano player's skill level? Is it preferable to base this assessment on visual analysis of the player's performance or should we trust our ears over our eyes? Since current CNNs have difficulty processing long video videos, how can shorter clips be sampled to best reflect the players skill level? In this work, we collect and release a first-of-its-kind dataset for multimodal skill assessment focusing on assessing piano player's skill level, answer the asked questions, initiate work in automated evaluation of piano playing skills and provide baselines for future work.
HalluciNet-ing Spatiotemporal Representations Using 2D-CNN
Dec 10, 2019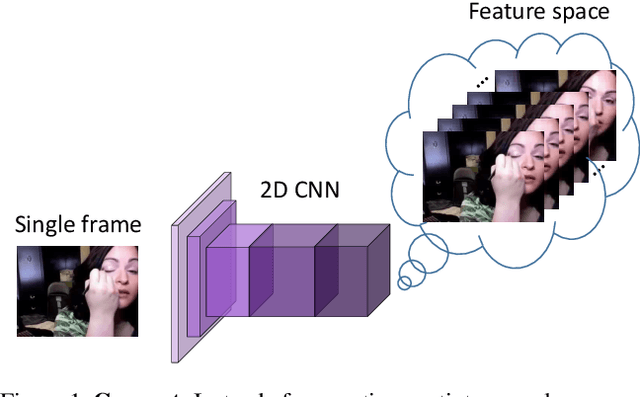
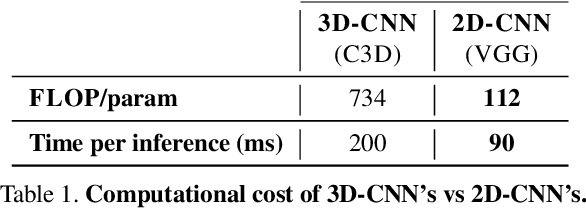

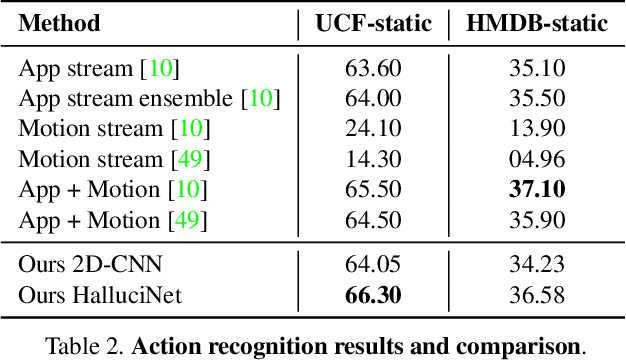
Spatiotemporal representations learnt using 3D convolutional neural networks (CNN's) are currently the state-of-the-art approaches for action related tasks. However, 3D-CNN's are notoriously known for being memory and compute resource intensive. 2D-CNN's, on the other hand, are much lighter on computing resource requirements, and are faster. However, 2D-CNN's performance on action related tasks is generally inferior to that of 3D-CNN's. Also, whereas 3D-CNN's simultaneously attend to appearance and salient motion patterns, 2D-CNN's are known to take shortcuts and recognize actions just from attending to background, which is not very meaningful. Taking inspiration from the fact that we, humans, can intuit how the actors will act and objects will be manipulated through years of experience and general understanding of the "how the world works," we suggest a way to combine the best attributes of 2D- and 3D-CNN's -- we propose to hallucinate spatiotemporal representations as computed by 3D-CNN's, using a 2D-CNN. We believe that requiring the 2D-CNN to "see" into the future, would encourage it gain deeper about actions, and how scenes evolve by providing a stronger supervisory signal. Hallucination task is treated rather as an auxiliary task, while the main task is any other action related task such as, action recognition. Thorough experimental evaluation shows that hallucination task indeed helps improve performance on action recognition, action quality assessment, and dynamic scene recognition. From practical standpoint, being able to hallucinate spatiotemporal representations without an actual 3D-CNN, would enable deployment in resource-constrained scenarios such as lower-end phones and edge devices, and/or with lower bandwidth. This translates to pervasion of Video Analytics Software as a Service (VA SaaS), for e.g., automated physiotherapy options for financially challenged demographic.
What and How Well You Performed? A Multitask Learning Approach to Action Quality Assessment
Apr 08, 2019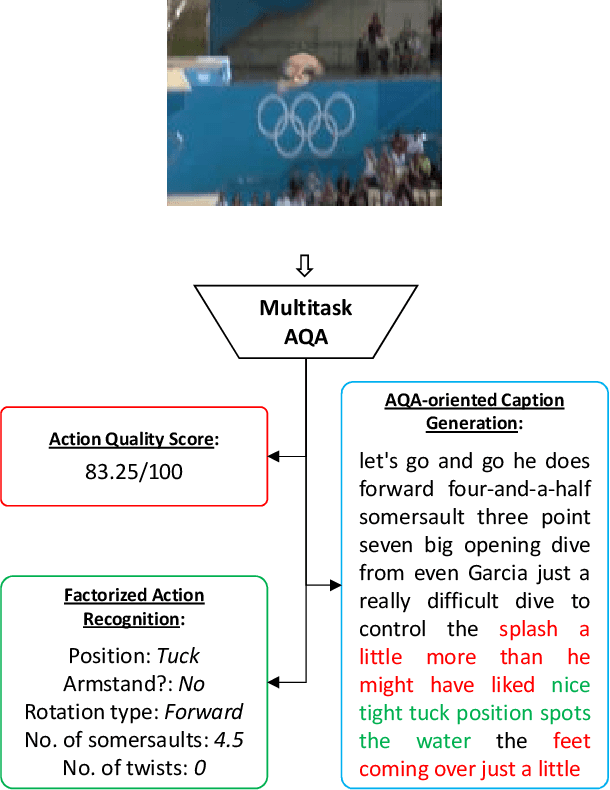


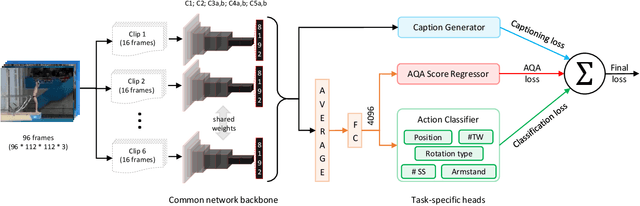
Can performance on the task of action quality assessment (AQA) be improved by exploiting a description of the action and its quality? Current AQA and skills assessment approaches propose to learn features that serve only one task - estimating the final score. In this paper, we propose to learn spatio-temporal features that explain three related tasks - fine-grained action recognition, commentary generation, and estimating the AQA score. A new multitask-AQA dataset, the largest to date, comprising of 1412 diving samples was collected to evaluate our approach (http://rtis.oit.unlv.edu/datasets.html). We show that our MTL approach outperforms STL approach using two different kinds of architectures: C3D-AVG and MSCADC. The C3D-AVG-MTL approach achieves the new state-of-the-art performance with a rank correlation of 90.44%. Detailed experiments were performed to show that MTL offers better generalization than STL, and representations from action recognition models are not sufficient for the AQA task and instead should be learned.