 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHalluciNet-ing Spatiotemporal Representations Using 2D-CNN
Paper and Code
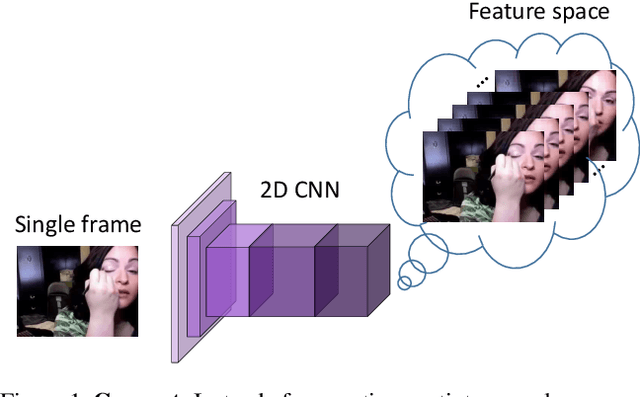
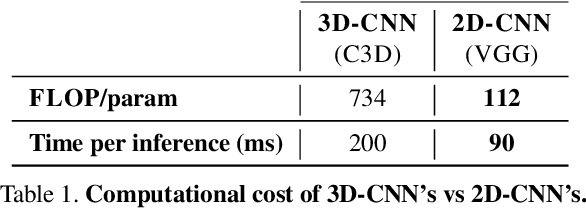

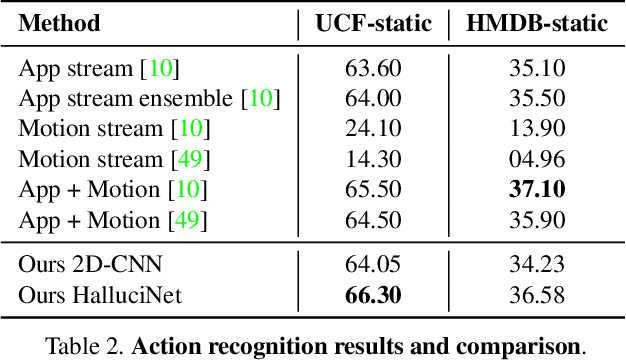
Spatiotemporal representations learnt using 3D convolutional neural networks (CNN's) are currently the state-of-the-art approaches for action related tasks. However, 3D-CNN's are notoriously known for being memory and compute resource intensive. 2D-CNN's, on the other hand, are much lighter on computing resource requirements, and are faster. However, 2D-CNN's performance on action related tasks is generally inferior to that of 3D-CNN's. Also, whereas 3D-CNN's simultaneously attend to appearance and salient motion patterns, 2D-CNN's are known to take shortcuts and recognize actions just from attending to background, which is not very meaningful. Taking inspiration from the fact that we, humans, can intuit how the actors will act and objects will be manipulated through years of experience and general understanding of the "how the world works," we suggest a way to combine the best attributes of 2D- and 3D-CNN's -- we propose to hallucinate spatiotemporal representations as computed by 3D-CNN's, using a 2D-CNN. We believe that requiring the 2D-CNN to "see" into the future, would encourage it gain deeper about actions, and how scenes evolve by providing a stronger supervisory signal. Hallucination task is treated rather as an auxiliary task, while the main task is any other action related task such as, action recognition. Thorough experimental evaluation shows that hallucination task indeed helps improve performance on action recognition, action quality assessment, and dynamic scene recognition. From practical standpoint, being able to hallucinate spatiotemporal representations without an actual 3D-CNN, would enable deployment in resource-constrained scenarios such as lower-end phones and edge devices, and/or with lower bandwidth. This translates to pervasion of Video Analytics Software as a Service (VA SaaS), for e.g., automated physiotherapy options for financially challenged demographic.