 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWin-Fail Action Recognition
Feb 15, 2021
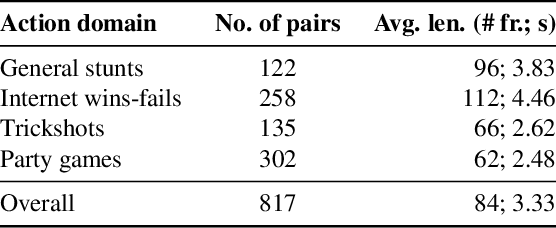

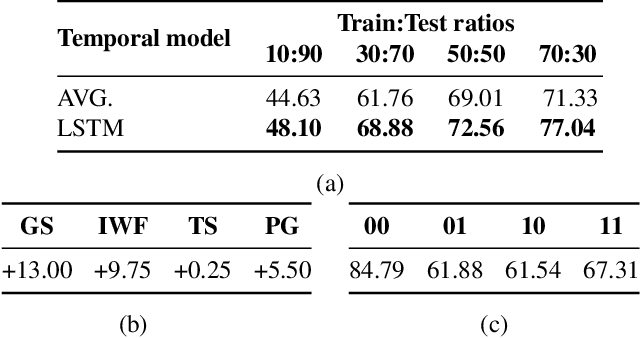
Current video/action understanding systems have demonstrated impressive performance on large recognition tasks. However, they might be limiting themselves to learning to recognize spatiotemporal patterns, rather than attempting to thoroughly understand the actions. To spur progress in the direction of a truer, deeper understanding of videos, we introduce the task of win-fail action recognition -- differentiating between successful and failed attempts at various activities. We introduce a first of its kind paired win-fail action understanding dataset with samples from the following domains: "General Stunts," "Internet Wins-Fails," "Trick Shots," and "Party Games." Unlike existing action recognition datasets, intra-class variation is high making the task challenging, yet feasible. We systematically analyze the characteristics of the win-fail task/dataset with prototypical action recognition networks and a novel video retrieval task. While current action recognition methods work well on our task/dataset, they still leave a large gap to achieve high performance. We hope to motivate more work towards the true understanding of actions/videos. Dataset will be available from https://github.com/ParitoshParmar/Win-Fail-Action-Recognition.
Piano Skills Assessment
Jan 13, 2021
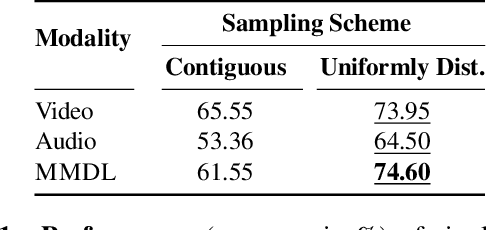
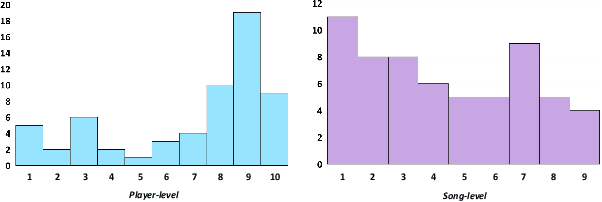

Can a computer determine a piano player's skill level? Is it preferable to base this assessment on visual analysis of the player's performance or should we trust our ears over our eyes? Since current CNNs have difficulty processing long video videos, how can shorter clips be sampled to best reflect the players skill level? In this work, we collect and release a first-of-its-kind dataset for multimodal skill assessment focusing on assessing piano player's skill level, answer the asked questions, initiate work in automated evaluation of piano playing skills and provide baselines for future work.
HalluciNet-ing Spatiotemporal Representations Using 2D-CNN
Dec 10, 2019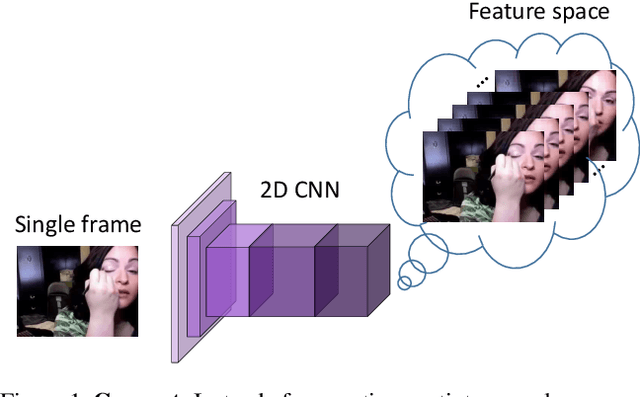
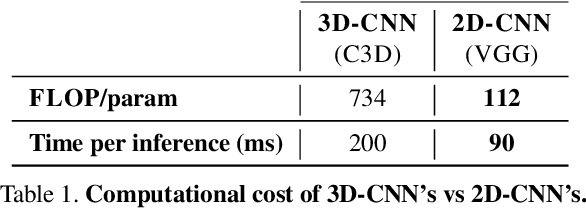

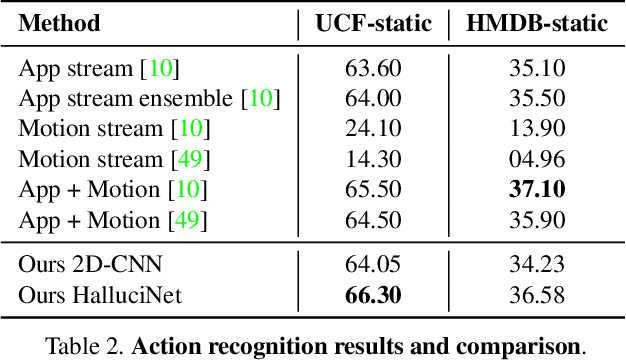
Spatiotemporal representations learnt using 3D convolutional neural networks (CNN's) are currently the state-of-the-art approaches for action related tasks. However, 3D-CNN's are notoriously known for being memory and compute resource intensive. 2D-CNN's, on the other hand, are much lighter on computing resource requirements, and are faster. However, 2D-CNN's performance on action related tasks is generally inferior to that of 3D-CNN's. Also, whereas 3D-CNN's simultaneously attend to appearance and salient motion patterns, 2D-CNN's are known to take shortcuts and recognize actions just from attending to background, which is not very meaningful. Taking inspiration from the fact that we, humans, can intuit how the actors will act and objects will be manipulated through years of experience and general understanding of the "how the world works," we suggest a way to combine the best attributes of 2D- and 3D-CNN's -- we propose to hallucinate spatiotemporal representations as computed by 3D-CNN's, using a 2D-CNN. We believe that requiring the 2D-CNN to "see" into the future, would encourage it gain deeper about actions, and how scenes evolve by providing a stronger supervisory signal. Hallucination task is treated rather as an auxiliary task, while the main task is any other action related task such as, action recognition. Thorough experimental evaluation shows that hallucination task indeed helps improve performance on action recognition, action quality assessment, and dynamic scene recognition. From practical standpoint, being able to hallucinate spatiotemporal representations without an actual 3D-CNN, would enable deployment in resource-constrained scenarios such as lower-end phones and edge devices, and/or with lower bandwidth. This translates to pervasion of Video Analytics Software as a Service (VA SaaS), for e.g., automated physiotherapy options for financially challenged demographic.
Keypoint Density-based Region Proposal for Fine-Grained Object Detection and Classification using Regions with Convolutional Neural Network Features
Mar 01, 2016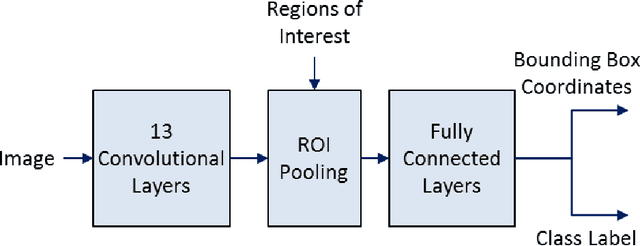



Although recent advances in regional Convolutional Neural Networks (CNNs) enable them to outperform conventional techniques on standard object detection and classification tasks, their response time is still slow for real-time performance. To address this issue, we propose a method for region proposal as an alternative to selective search, which is used in current state-of-the art object detection algorithms. We evaluate our Keypoint Density-based Region Proposal (KDRP) approach and show that it speeds up detection and classification on fine-grained tasks by 100% versus the existing selective search region proposal technique without compromising classification accuracy. KDRP makes the application of CNNs to real-time detection and classification feasible.